

What Is Virtual Graph? How Does It Work?
As data becomes increasingly fragmented across transactional databases, lakehouses, and analytical storage formats such as Apache Iceberg, related entities and interactions are often split across systems and schemas, making relationship analysis significantly more complex. Traditional analytics tools analyze tables in isolation and struggle with multi-hop, cross-system relationships, especially when data freshness and query efficiency both matter.
Graph databases are well suited for relational queries, but they typically require ingesting and duplicating data into a dedicated graph store. This introduces latency, operational complexity, and consistency risks that conflict with modern architectures built around separation of storage and compute.
Virtual graphs address this gap by providing a graph abstraction directly on top of existing data sources, without physically materializing the graph. Users can run expressive graph queries, such as traversals and pattern matching, across heterogeneous systems while keeping data in place. This article explains what virtual graphs are, how they work, how they differ from physical graphs, and when they are the right architectural choice.
What Is a Virtual Graph?
A virtual graph is a logical graph representation defined on top of existing data sources without copying or persisting data into a native graph database. Nodes, edges, and properties are described through metadata mappings to underlying datasets such as relational tables, lakehouse tables (for example, Iceberg or Delta Lake), or external services. When a graph query is executed, it is translated into source-specific queries and evaluated dynamically.
Unlike a physical graph, a virtual graph does not store adjacency lists, edge indices, or graph-specific storage structures. Instead, it relies on the schemas, indexes, and storage mechanisms of the underlying systems. The graph exists conceptually rather than physically, enabling graph-style querying while keeping data in place.
This approach aligns naturally with modern lakehouse architectures. As data increasingly resides in lakehouse tables and storage and compute become decoupled, virtual graphs align naturally with this architecture by operating as a logical query layer over existing systems while data remains in its original storage locations.
From the user’s perspective, heterogeneous datasets appear as a unified graph. A customer table in PostgreSQL, event data in an Iceberg lake, and account metadata in MySQL can be traversed as a single connected structure. Because the graph is defined through metadata, models are flexible and iterative: new relationships or views can be introduced without data migration, and multiple graph schemas can coexist over the same sources.
Virtual graphs are especially attractive when data freshness, cross-system integration, and modeling agility matter more than storing a graph permanently. In some cases, performance can be further improved through techniques such as materialized views or local caching, while still retaining the core benefit of querying data in place.
Also, virtual graphs offer strong flexibility: the same underlying data can be modeled with different schemas, allowing multiple graph views to coexist without duplicating data. Instead of building and maintaining many separate physical graphs for different use cases, a single dataset can support multiple schemas with far lower storage, maintenance, and operational overhead.
How Virtual Graphs Work
At a high level, virtual graphs work by interpreting graph semantics over existing data sources at query time, rather than depending on a physical graph that is precomputed and stored in a separate graph database. This allows users to issue graph queries while keeping data in its original systems and formats.
The process begins with graph modeling. Users define a logical graph schema that maps nodes, edges, and properties to existing datasets. A node may correspond to a record in a database or a row in a lakehouse file, while an edge represents the relationship between two nodes. These definitions are metadata-driven and do not require data movement or transformation.
When a graph query is submitted, the virtual graph engine parses it and constructs a logical execution plan based on the graph model. The logical plan is then processed by the query optimizer, which generates an efficient physical execution plan. This plan determines which data sources are involved, how relationships should be evaluated, and how intermediate results need to be combined. The planning happens at a semantic level, independent of any single storage system.
Data required for the query is retrieved from underlying platforms through source connectors, which leverage each system’s native processing capabilities. The virtual graph engine then incrementally combines these results and performs computations related to graph semantics, such as traversals and pattern matching, to produce the final output.
From the user’s perspective, this complexity is hidden behind a unified graph interface. Queries behave as if they are executed against a single graph, even though computation is distributed across multiple systems. Because evaluation happens directly on source data, results reflect the current state of the underlying datasets.
By acting as a semantic and orchestration layer rather than a storage system, virtual graphs enable relational reasoning across heterogeneous data without introducing new data pipelines or persistence layers.
Virtual Graph Architecture
A virtual graph architecture organizes graph semantics, query planning, and physical data access into a coordinated, layered system. Queries are evaluated dynamically over existing data sources without materializing a graph. Rather than following a rigid execution pipeline, the architecture emphasizes how components collaborate at query time: the graph engine interprets queries with reference to the logical graph model, the planner & optimizer within the graph engine convert them into source-level operations, and connectors execute queries directly on underlying systems.
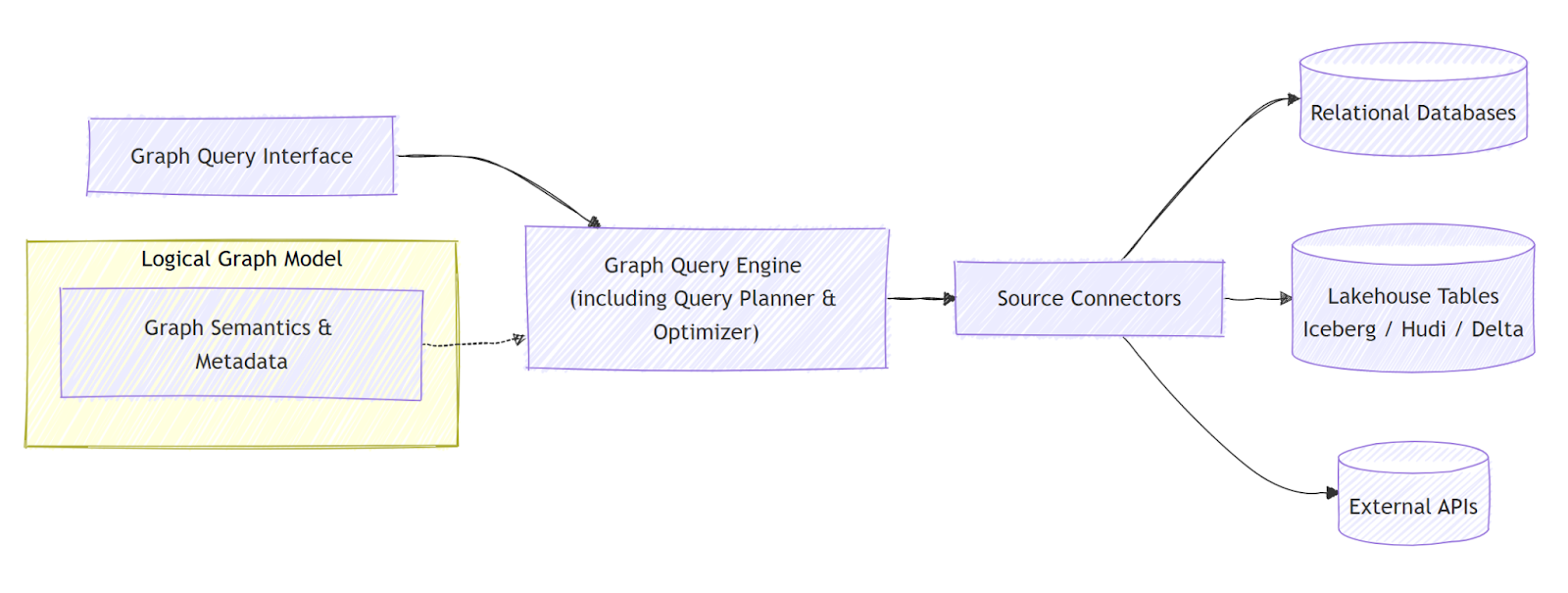
At the top is the graph query interface, exposing standard graph query languages such as openCypher or Gremlin. Users interact with a unified graph abstraction, independent of where the data physically resides.
The graph query engine acts as the semantic coordinator, interpreting queries and orchestrating execution. It references the logical graph model, which defines how nodes, edges, and properties map to underlying datasets. The model provides metadata and semantic meaning but contains no actual data.
The query planner and optimizer, inside the graph query engine, decompose graph operations into source-level instructions and apply optimizations such as join ordering, traversal pruning, and predicate pushdown.
Data access is handled through source connectors, which translate logical operations into SQL for relational databases, direct reads from lakehouse files like Iceberg, or API requests for external systems. Each source returns relevant data using its native processing capabilities. The virtual graph engine incrementally combines these results and performs computations related to graph semantics, ensuring traversals, pattern matching, and multi-hop queries are correctly evaluated.
This layered architecture ensures data remains in place, queries reflect live data, and graph reasoning spans heterogeneous systems without introducing ETL pipelines or new storage layers.
Virtual Graph vs Physical Graph
Imagine you have a large set of underlying data spread across relational databases and a Lakehouse, and you want to model and analyze relationships between entities. You have two main approaches: building a physical graph or using a virtual graph.
A physical graph is created by importing data from source systems into a dedicated graph database, where nodes, edges, and properties are stored in graph-native structures. Traversals and multi-hop queries are fast because relationships are stored as direct pointers. Graph algorithms like shortest path or PageRank run efficiently. However, this requires maintaining ETL pipelines to keep the graph in sync with source data, adding storage costs, latency, and potential consistency issues, especially when source data changes frequently.
A virtual graph, on the other hand, keeps data in place. Nodes and edges are defined via metadata that maps to relational tables or Lakehouse tables. Queries are interpreted by the graph query engine using the virtual graph schema, translated into source-specific operations, and executed through source connectors against the underlying data systems at runtime. This ensures results always reflect live data and eliminates data duplication and maintenance overhead. Complex traversals may be slower than in a physical graph, depending on source system performance, but performance can be improved selectively using materialized views or caching, while still keeping the core benefit of zero data movement.
Comparison:
Key Benefits of Virtual Graphs
Virtual graphs offer several advantages over physical graphs, particularly in distributed and heterogeneous data environments.
- Live access to source data
Queries operate directly on underlying systems, allowing results to reflect current data without requiring continuous data synchronization pipelines. This is especially valuable for monitoring, investigative analysis, and operational analytics where freshness matters. - Reduced operational overhead
Because graph structures are defined logically rather than physically stored, teams can leverage existing databases and lakehouse platforms without introducing additional graph storage infrastructure or complex data movement workflows. - Rapid time to insight
Graph schemas can be defined through metadata mappings, enabling teams to begin querying immediately. This supports rapid experimentation, iterative modeling, and proof-of-concept exploration without long ingestion cycles. - Flexible schema modeling
Multiple graph schemas can be defined over the same underlying physical data. Different teams can model entities and relationships differently depending on analytical goals, without duplicating datasets or restructuring storage systems. - Unified cross-system relationship analysis
Virtual graphs provide a logical layer that connects distributed sources into a single relational context, making it easier to analyze relationships that would otherwise require pipelines, or data consolidation processes.
When to Use a Virtual Graph
A virtual graph is particularly well suited to modern data architectures built around lakehouses and the separation of storage and compute, two defining trends in today’s big data ecosystem. Organizations increasingly adopt lakehouse platforms to unify analytics across structured and unstructured data, while decoupled storage and compute enable independent scaling, shared data access, and cost-efficient resource utilization. In these environments, data typically remains in open storage layers and is accessed by multiple engines rather than copied into specialized systems.
Within this architectural model, a virtual graph layer enables graph modeling and querying directly on existing data without physical duplication or ETL pipelines. This leverages distributed execution, federated access to diverse sources, and flexible schema definitions. This approach prioritizes real-time data access, interoperability across systems, rapid analytical iteration, and reduced operational overhead: capabilities that align closely with the goals of modern, open, and scalable data platforms.
Virtual graphs are also a good fit when data freshness matters. Since queries operate directly on source systems, results always reflect the latest state. This is especially important in compliance, monitoring, and investigative scenarios.
Common Use Cases of Virtual Graphs
The common use cases of virtual graphs share a common characteristic: the underlying data already forms a graph structure and must be analyzed dynamically across systems. Virtual graphs provide flexible, runtime modeling and traversal directly over existing data, making them more practical than physical graphs for large, fast-changing, cross-system workloads.
One common use case is cybersecurity and threat detection, where users, devices, network flows, and authentication events are spread across logs and operational systems. Virtual graphs enable analysts to traverse live relationships across massive datasets during investigations. Another key scenario is financial anti-fraud analysis, where accounts, transactions, and behavioral signals evolve rapidly and require dynamic, runtime modeling to uncover coordinated activity patterns without heavy data ingestion.
Virtual graphs also support knowledge graph–style analytics, allowing multiple semantic graph models to be defined over evolving operational and analytical data without restructuring storage. In addition, observability and system analytics benefit from runtime graph exploration across telemetry, service dependencies, and infrastructure events generated at high volume.
Challenges and Limitations of Virtual Graphs
One of the primary challenges is performance. Because virtual graphs are logical constructs, their actual computation requires fetching data through source connectors. The overall query efficiency depends on both the virtual graph layer and the capabilities of the underlying data sources and connectors. However, this overhead can sometimes be mitigated by maintaining local caches, which help reduce latency.
Query optimization is another challenge. Graph queries must be translated into efficient source-level queries, which requires sophisticated planners and accurate statistics. Without careful optimization, performance can degrade quickly as data size grows.
Consistency across sources can also be an issue. Virtual graphs assume that relationships inferred from different systems are logically consistent, but transactional guarantees rarely span multiple databases. This can lead to subtle anomalies in query results.
Use PuppyGraph to build virtual graphs
PuppyGraph was designed to address exactly these challenges. It is a distributed graph query engine built specifically for graph analytics and graph query optimization.
Most virtual graph solutions are based on translating graph queries into SQL, which means their performance and capabilities are largely determined by the underlying data source. PuppyGraph takes a different approach. Instead of treating graph queries as SQL translations, it starts with the graph model itself and represents graph operations as a set of node and edge operators. These graph computations are executed within PuppyGraph’s own query engine.
This architecture makes it possible to optimize specifically for graph workloads rather than relying solely on the capabilities of the underlying data sources. As a result, PuppyGraph’s distributed compute engine enables multi-hop queries over billions of relationships in seconds. It supports fast iterative modeling, and lowers the complexity of adopting graph analytics without changing underlying data architecture.
What is PuppyGraph

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.


Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Virtual graphs provide a practical way to bring graph reasoning to modern, distributed data architectures without introducing new storage systems or complex ETL pipelines. By defining nodes and edges through metadata and executing queries directly on existing sources, they enable flexible modeling, live data access, and unified analysis across heterogeneous platforms such as relational databases and lakehouses. This approach aligns naturally with storage–compute separation and open data ecosystems.
While virtual graphs introduce challenges such as performance optimization and cross-system consistency, advances in query planning, caching, and distributed execution make them increasingly viable for enterprise workloads. PuppyGraph demonstrates how zero-ETL graph engines can deliver real-time, scalable graph analytics directly on existing data, helping organizations unlock relationship-driven insights faster while reducing operational complexity and infrastructure costs.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install