

Property Graph vs RDF: Key Differences Between Graph Data Models
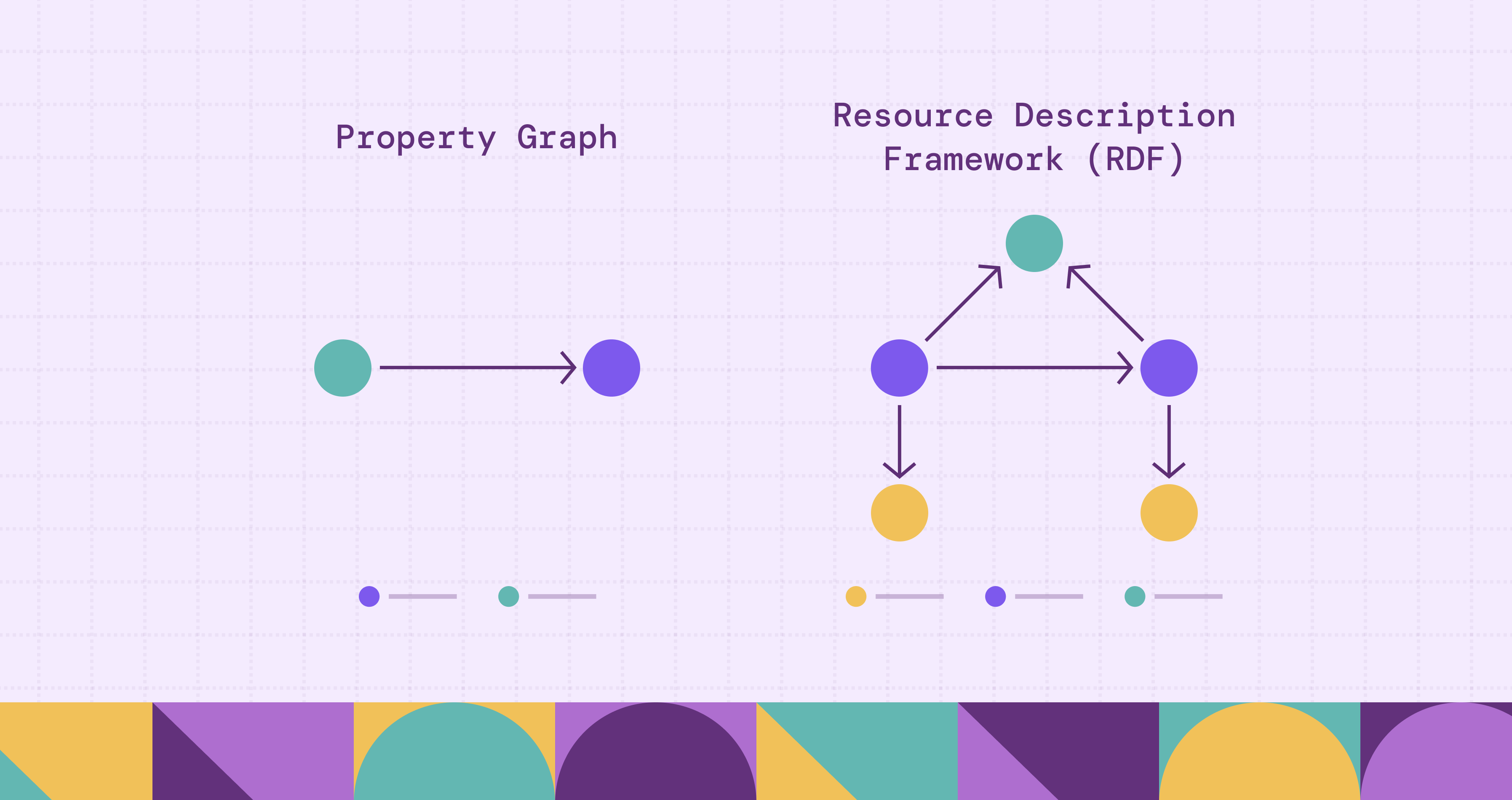
The property graph and the RDF (Resource Description Framework) graph are both popular paradigms for structuring connected data. Two models diverge fundamentally in their design goals, each has its own strength and performs well in some use cases.
RDF, a standard established by the World Wide Web Consortium (W3C), prioritizes global data integration and formal semantics. It achieves this by relying on Internationalized Resource Identifiers (IRIs) for unique, web-scale identity, and by including built-in support for ontological reasoning, enabling the system to infer new knowledge. Conversely, the property graph model focuses intensely on application-specific performance and high-speed traversal, proving to scale exceptionally well for big data and large analytical workloads due to its intuitive, compact structure.
Property graphs and RDF each offer distinct advantages, and the choice between them depends on practical needs. This article will take a close look at property graphs and RDF, detailing their core features, contrasting their architectural differences, and introducing typical use cases where each model is the preferred solution.
What is a Property Graph?
A Property Graph is a labeled, directed graph model. It is designed to represent entities and their relationships with key-value pairs called properties.
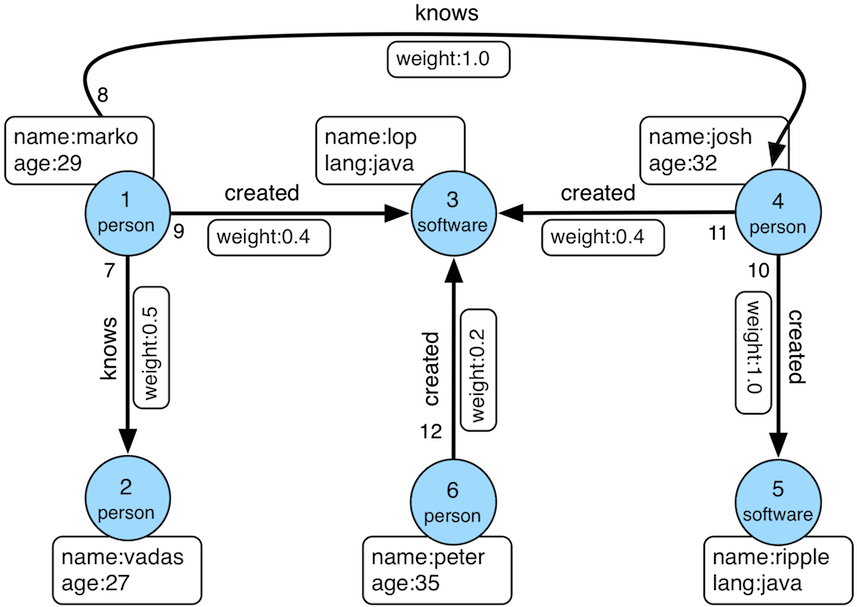
- Nodes (or vertices) represent entities, which can be people, software, or whatever. Each node has a label to categorize its type, indicating this node stands for a person, a software or other categorization.
- Relationships represent directed links between nodes. Like nodes, each relationship also has a label categorizing its type, such as :created and :knows. The source node, the destination node and the type uniquely determine a relationship.
- Properties are key–value pairs that describe attributes of both nodes and relationships, such as name:ripple or age:27. They answer questions like “Was this software written in java”, enabling complex graph queries.
The property graph structure is intentionally flexible. It has no strict schema, so you can add new node types and edge labels. If needed, you can also assign properties to them, making property graphs ideal for dynamic data that evolves over time.
Besides, due to the rich expressive power and exceptional efficiency, there are numerous graph algorithms based on the property graph model. Many of them are integrated into native graph databases, enabling users to perform complex graph analysis.
What is RDF?
RDF is the abbreviation for Resource Description Framework, which was originally designed by W3C (World Wide Web Consortium) for representing information on the web. Often, the term “RDF” is used to refer to its underlying abstract data model, especially RDF graph data model.
An RDF graph is a collection of triples, each consisting of a subject, a predicate and an object. Every subject-predicate-object triple represents a statement.
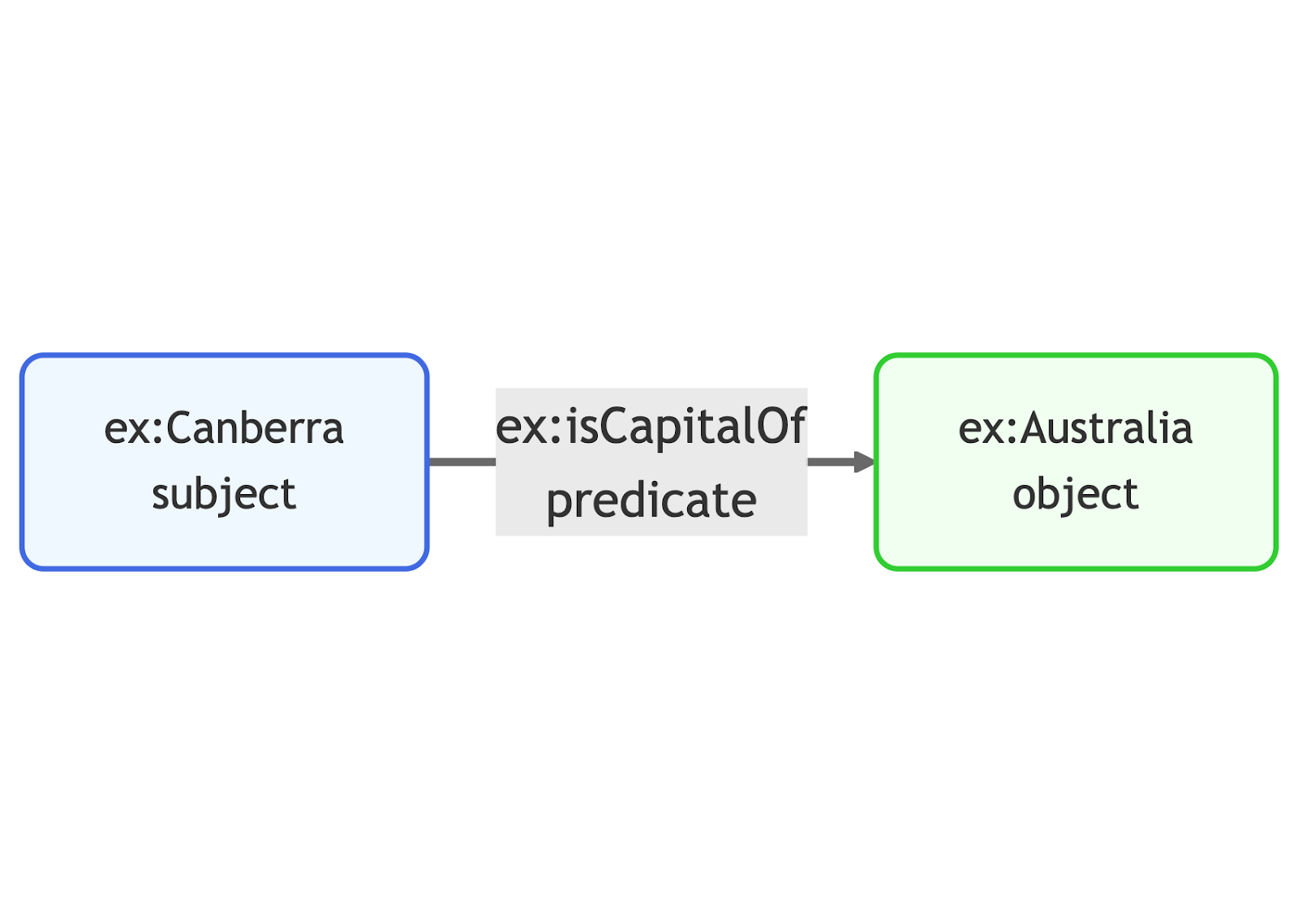
Take the statement “Canberra is the capital of Australia” for example, it can be expressed as ex:Canberra ex:isCapitalOf ex:Australia. It has the subject “Canberra”, the predicate “is the capital of” and the object “Australia”. Treating the subject and object as nodes, the predicate as an edge, an RDF graph is visualized as a directed graph, much like the property graph case.
Suppose on another website, we have the statement “Canberra is located in Oceania”. When using RDF to represent information on the web, it’s natural to think that the term “Canberra” in both sentences should refer to the unique entity.
Thereby Uniform Resource Identifier (URI), or IRI for RDF 1.2, comes in. By anchoring entities to globally unique IRIs, RDF enables coherent integration of distributed information, allowing systems to recognize that Canberra holds both properties, “the capital of Australia” and “the city in Oceania”.
Another fascinating feature of RDF is the semantic reasoning. Suppose the statement “Canberra is the capital of Australia” is stored in an RDF graph, and we further include a general rule that says all capitals are cities, something like ex:isCapitalOf rdfs:domain ex:City. With this additional semantic constraint, RDF reasoning engines can automatically infer the new fact that "Canberra is a city" without requiring this information to be explicitly stated.
Relationship Between Property Graph vs RDF
The core technical divergence between the Property Graph and RDF models centers on their foundational structure and the representation of metadata attached to relationships.
Structural Contrast: Nodes and Relationships vs. Triples
The property graph is structurally defined by four components: nodes, directed relationships, labels, and properties, which can be attached natively to both nodes and relationships. Every relationship (edge) is a first-class entity that connects a source and a target node.
In contrast, the RDF graph represents all information exclusively as atomic subject, predicate and object (S-P-O) triples. The subject and object are nodes, while the predicate serves as the directed, labeled relationship. Property graphs prioritize detailed, compact modeling of entities and their connected context, while RDF graphs prioritize the atomicity of statements for maximum semantic rigor.
Since nodes and edges are treated as distinct entities capable of holding their own descriptive properties, the property graph model performs well with big data and is highly optimized for performance-intensive traversal. Conversely, the high level of atomicity in the RDF triple structure, while maximizing semantic granularity, makes it harder to scale for large analytics workloads, generally leading to slower performance at scale.
Identity Mechanisms: Internal IDs vs. Global IRIs
In the property graph model, nodes are identified internally, typically using database-assigned IDs, and classified using human-readable labels (e.g., :Person). On the other hand, RDF relies on URIs or IRIs for identifying resources, including subjects and predicates. IRIs provide globally unambiguous identifiers, which is crucial for the RDF model’s primary goal of achieving web-scale interoperability and linking data across disparate systems.
Modeling Relationship Attributes
A significant functional divergence is how attributes are associated with relationships. The property graph supports properties natively on the edge (e.g., a :knows relationship may have a property {since: 2020}), which results in a highly detailed and concise model. RDF's rigid S-P-O structure prevents properties from being stored directly on the predicate (relationship type).
To capture relationship attributes in RDF, a structural workaround is necessary:
- Reification: The relationship itself is converted into a new node (often a blank node), and multiple triples are required to assert the property, greatly increasing graph density and query complexity.
- RDF-star: A syntactic extension that allows a triple to be the subject or object of another triple (nested triples), thereby capturing the edge property in a way that visually and semantically approximates the property graph model.
The atomic nature of RDF inevitably increases the sheer volume of statements in the graph compared to the compact property graph model, where attributes are retrieved instantly alongside the node or edge identifier.
Property Graph vs RDF: Key Differences
To sum up, the table below shows a direct comparison between property graphs and RDF.
Common Misconceptions
The historical rivalry between the two standards has generated several misconceptions that require clarification based on architectural reality.
Myth 1: RDF is the Only Solution for Knowledge Graphs
It is often asserted that RDF is the necessary or exclusive framework for building knowledge graphs due to its strong association with formal semantics and W3C standards. While RDF is ideal for modeling complex ontologies and enabling logical inference, property graphs are equally vital for knowledge graphs focused on operational efficiency and speed.
Many organizations find the property graph model, with its simplicity and efficient query of entity properties, easier to set up and use for a knowledge graph. Rather than take RDF’s complexity as a technical prerequisite, they only add semantic organizing principles, such as taxonomies and controlled vocabularies when specific semantic needs call for it.
Myth 2: Architects Must Choose Exclusively Between RDF and Property Graph
Property graphs and RDF are not fundamentally incompatible. Technical mechanisms exist for converting data between the two structures to facilitate data exchange and interoperability. Property graph systems often include features that enable them to consume and produce RDF data, providing a pathway for integration with external semantic platforms or legacy triple stores. Conversely, established mappings allow for the conversion of property graphs into RDF formats.
Ultimately, the choice often relies on determining the core requirements, say, whether the primary focus is on semantic rigor (RDF) or high-speed traversal performance (property graphs), but they don’t have to be seen as entirely isolated models.
When to Use Property Graph vs RDF
The selection of a graph model is a strategic decision guided by the system's primary performance or semantic requirement. RDF excels in global identity and semantic reasoning, while property graphs thrive in fast multi-hop queries and flexible attribute management.
Property Graph Use Cases: Performance and Application Focus
The property graph is the superior choice when high-performance, real-time traversal, and transactional integrity are the most critical non-functional requirements.
- Fraud Detection: This application requires extremely rapid, deep pathfinding capabilities to uncover hidden connections and complex fraud rings in real-time. Property graphs’ guaranteed fast traversal is essential for maintaining low latency in multi-hop queries.
- Cybersecurity Analysis: Analyzing security threats, network infrastructure, and access control paths is a critical application of property graphs. By modeling network devices, user accounts, permissions, and threat lineage as a graph, security teams can use rapid traversal to identify attack vectors, trace the source of an intrusion, and visualize lateral movement within a system.
- Recommendation Engines: These systems rely on efficient network analytics to quickly find similar entities or connection paths to generate suggestions, demanding high-speed processing for analytical tasks.
RDF Use Cases: Semantic Interoperability and Reasoning
RDF is essential when the core system requirement is global data integration, strict adherence to formal ontologies, regulatory compliance and inferential capabilities.
- Knowledge Graphs: RDF's reliance on Internationalized Resource Identifiers (IRIs) and supporting W3C standards may assist in integrating highly heterogeneous datasets. By mapping disparate data sources to shared, global vocabularies, RDF can contribute to the construction of unified knowledge graphs. However, RDF is generally considered harder to scale for large analytical workloads, and retrieval speed may become slower as the knowledge database size significantly increases.
- Semantic Search: The formal structure of RDF triples and the ability to define ontologies can be leveraged in search applications. This approach may help systems interpret the relationships and concepts underlying the data, which can support more context-aware information retrieval than simple keyword matching.
- Data Validation and Governance Systems: The W3C semantic stack includes tools like the Shapes Constraint Language (SHACL) that define structural constraints for RDF data. These standards can be used for data quality checks and validation in structured environments, such as government data management systems or projects requiring strict regulatory compliance.
PuppyGraph: Query Your Relational Data as a Graph
We have already discussed the two types of graph models: the property graph and RDF. But how can they be applied to your data? Traditionally, you would need to transform your data and load it into a dedicated graph database through a complex ETL process, creating redundant data copies. You would also have to manage and maintain the entire data pipeline yourself.
Now, there’s a new approach — PuppyGraph.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC.
Conclusion
The property graph and RDF represent two divergent approaches to modeling connected data, stemming from their core design philosophies. Property graphs are for application speed, high-velocity transactional workloads, and optimized, real-time traversal performance. Conversely, RDF is rooted in the W3C Semantic Web initiative, prioritizing global interoperability, formalized semantic integration, and the ability to perform complex inferential reasoning.
The utility of each model is therefore dictated by the system’s primary non-functional requirement. Property graphs excel in performance-critical applications like fraud detection and cybersecurity analysis, while RDF is essential for complex data harmonization and knowledge modeling.
PuppyGraph provides high-performance graph analysis and data aggregation across various relational data sources. To see how PuppyGraph works seamlessly with your databases, try our forever-free Developer Edition or book a free demo with our team.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install