

RDF Knowledge Graphs: Structure & Benefits

RDF Knowledge Graphs provide a structured and semantic way to represent complex relationships between entities. Built on the Resource Description Framework (RDF), they organize information into interconnected triples: subject, predicate, and object, allowing machines to understand not only data but the meaning and context behind it. This framework supports advanced reasoning, data integration, and semantic querying, making RDF Knowledge Graphs essential for applications such as AI-powered search, recommendation systems, and knowledge discovery. In the following sections, we will examine RDF’s structure, its role in powering knowledge graphs, key components, comparisons with property graphs, and the advantages it offers in modeling interconnected information.
What is RDF (Resource Description Framework)?
The Resource Description Framework, or RDF, is a specification developed by the World Wide Web Consortium (W3C) to standardize how information is represented and exchanged on the web. At its core, RDF provides a way to describe resources, anything that can be identified with a URI, such as a person, a webpage, or an abstract concept.
RDF models information using triples:
- subject: the resource being described
- predicate: the property or relationship
- object: the value of that property (another resource or a literal)
For example, consider a simple description involving two people: “Alice knows Bob.”
In RDF terms, Alice is the subject, knows is the predicate, and Bob is the object.
We can enrich this graph with additional facts, such as Alice’s name or Bob’s homepage, to form a small RDF knowledge graph:
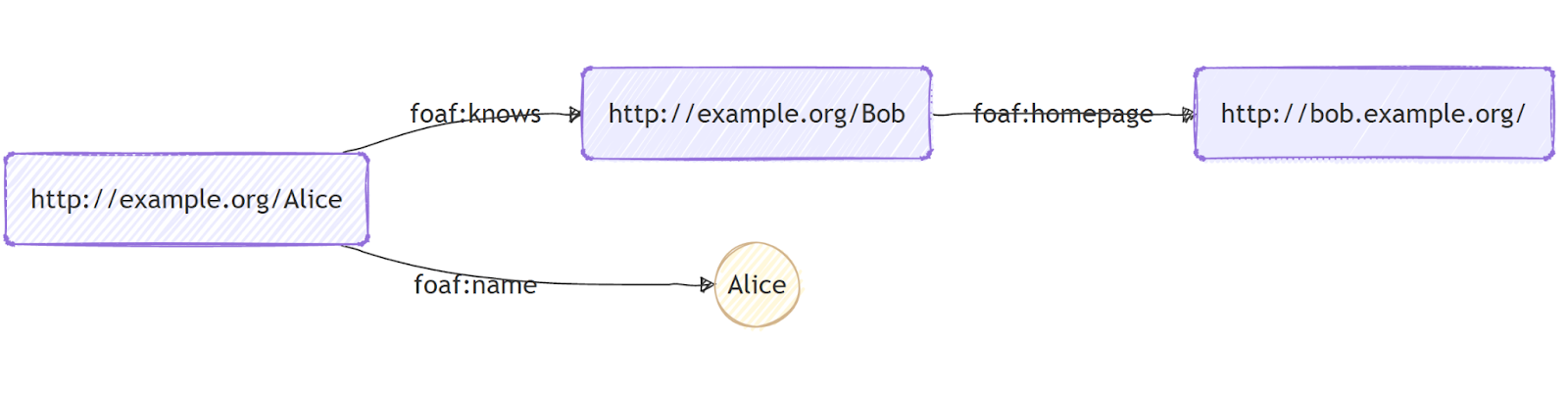
In this diagram:
- Each rectangle represents a URI resource.
- The oval represents a literal value (“Alice”).
- Arrows represent RDF predicates like foaf:name or foaf:knows.
Even with just a few triples, RDF creates a structured, semantic graph that both humans and machines can interpret.
One of RDF’s most important strengths is flexibility. Unlike relational databases that rely on fixed schemas, RDF graphs can evolve over time, new entities or relationships can be added without breaking existing data. RDF also supports ontologies, which formally define the types of resources and relationships in a domain. This enables consistent, machine-readable knowledge modeling at scale.
RDF plays a foundational role in the broader vision of the Semantic Web, where data is not just linked, but understood. By enabling machines to interpret meaning and context, RDF supports intelligent applications such as enhanced search, recommendation engines, automated reasoning, and knowledge-driven analytics.
RDF Data Structure: Triples, Subjects, Predicates, and Objects
At the core of RDF is the triple, the fundamental unit for representing knowledge. Each triple consists of a subject, a predicate, and an object, forming a directed connection that encodes semantic meaning. Subjects and objects are resources identified by URIs, while predicates define the relationships linking them. Literals, such as names or dates, can serve as object values to provide concrete data.
By chaining triples together, RDF creates a graph structure that allows machines to interpret complex relationships. Unlike rigid relational tables, RDF graphs are flexible: new entities and relationships can be added without disrupting existing data. This design enables semantic queries, reasoning, and the integration of data from multiple sources, forming the foundation for scalable knowledge graphs.
Example RDF Graph
Let’s re-examine the example used in the previous section:
- Rectangles represent URI-identified resources.
- Ovals represent literal values, such as Alice’s name.
- Arrows denote predicates, showing the semantic relationship between subjects and objects (e.g., foaf:knows, foaf:name).
Even with just a few triples, this graph illustrates how RDF encodes meaningful, machine-readable knowledge. By using URIs and typed literals, RDF ensures interoperability across datasets, enabling consistent reasoning and flexible expansion.
How RDF Powers Knowledge Graphs
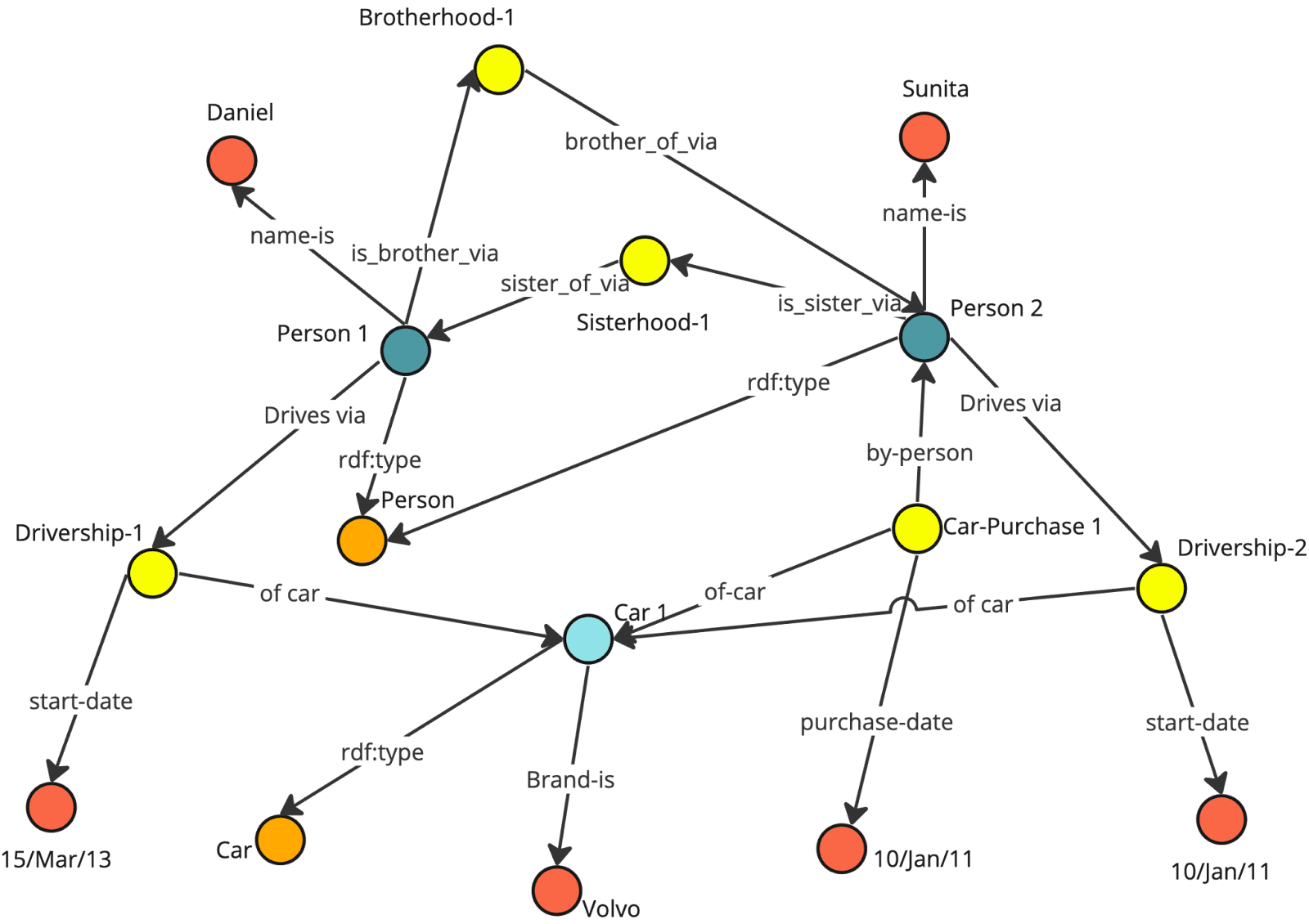
Knowledge graphs are structured representations of information where entities are nodes, and relationships between them are edges. RDF is particularly well-suited for powering knowledge graphs due to its triple-based architecture, which directly maps to the concept of nodes and edges. Each triple represents a directed edge from a subject to an object, labeled with a predicate, effectively encoding semantic relationships in a graph structure.
The ability of RDF to integrate data from diverse sources is one of its defining strengths. Data in RDF format can be combined from multiple datasets, even if they originate from different domains or adhere to different conventions. This interoperability is facilitated through shared vocabularies and ontologies. For instance, two datasets describing the same person using different naming conventions can be linked and understood as referring to the same individual through a process known as entity reconciliation.
Furthermore, RDF enables advanced reasoning over knowledge graphs. By leveraging ontologies and inference rules, systems can derive new knowledge from existing data. For example, if an RDF graph contains statements like “All professors are researchers” and “Alice is a professor”, reasoning engines can infer that “Alice is a researcher”, even if this explicit triple is not present in the graph. This capability enhances data completeness and enables applications such as predictive analytics, semantic search, and intelligent recommendation systems.
Key Components of an RDF Knowledge Graph
RDF Knowledge Graphs rely on globally unique URIs, typed literals, and semantically defined predicates to represent information in a machine-interpretable way. These components work together to form a flexible and interoperable model capable of evolving over time, making RDF particularly suitable for scenarios that require merging data across sources and supporting reasoning at scale.

Nodes (Resources)
Nodes are the identifiable entities within an RDF graph, each represented by a URI that ensures global uniqueness. These nodes can refer to people, organizations, places, or abstract concepts. Because URIs serve as stable identifiers, RDF graphs from different domains can be combined without naming conflicts, enabling consistent data integration and interpretation across distributed systems.
Edges (Predicates / Properties)
Edges encode the semantic relationships that link one resource to another, and each predicate is also a URI tied to a shared vocabulary. This structure allows RDF graphs to carry explicit meaning, making relationships interoperable and machine-understandable. Predicates such as foaf:knows or schema:affiliation carry well-defined semantics, allowing reasoning systems to derive additional knowledge from the graph.
Literals (Typed Values)
Literals attach concrete data values to resources, such as names, dates, or links, and each value carries a datatype like xsd:string or xsd:anyURI. Typed literals ensure precision and consistency across systems, enabling accurate comparison, filtering, and reasoning. They enrich the graph with descriptive detail while remaining distinct from URI-identified entities, maintaining RDF’s clear separation between resources and values.
Graphs and Datasets (Named Graphs)
RDF supports grouping triples into named graphs to manage context, provenance, or versioning within a larger dataset. Each named graph can represent a specific data source or trust boundary, enabling granular control over how information is referenced or queried. This layered structure makes RDF well-suited for complex environments where data integration, auditing, and multi-domain modeling are essential.
RDF vs Property Graph: Understanding the Differences
When designing a knowledge graph, it’s important to choose the right model based on the project’s goals. RDF and property graphs each have their strengths. The table below summarizes the main differences:
Both models are powerful, but your choice should be guided by whether your priority is semantic richness and interoperability (RDF) or traversal efficiency and flexible property modeling (Property Graph).
Benefits of Using RDF for Knowledge Graph Modeling
RDF offers numerous advantages for knowledge graph modeling, particularly in complex, heterogeneous, and large-scale datasets.
1. Semantic Richness: RDF explicitly represents the meaning of relationships, enabling machines to understand the context and nuances of data. This semantic depth supports advanced reasoning and knowledge inference.
2. Interoperability: By adhering to global standards, RDF facilitates the integration of diverse datasets, regardless of origin or schema differences. This is critical for research, enterprise knowledge management, and linked open data initiatives.
3. Flexibility and Scalability: RDF’s schema-less nature allows knowledge graphs to evolve naturally. Entities, relationships, and attributes can be added without redesigning the entire graph. This adaptability supports dynamic domains such as social networks, scientific research, or e-commerce.
4. Provenance and Traceability: RDF supports metadata and named graphs, which allow tracking the origin, version, and reliability of information. This is particularly valuable in scenarios requiring trustworthiness, such as biomedical research or legal data management.
By combining these benefits, RDF enables organizations to build knowledge graphs that are not only comprehensive and accurate but also capable of supporting intelligent, data-driven applications.
How SPARQL Works with RDF Knowledge Graphs
SPARQL is the standard query language for RDF, designed to retrieve and manipulate data stored in RDF format. It enables users to perform complex queries over the interconnected graph, leveraging the structure and semantics of RDF.
SPARQL queries operate by specifying patterns of triples to match within the graph. For instance, in a scholarly knowledge graph, one could query for all triples where the subject is a researcher named “Alice,” returning their co-authors, affiliated institutions, and published papers. A simple query might look like:
SELECT ?coauthor ?paper WHERE {
?paper :hasAuthor :Alice .
?paper :hasAuthor ?coauthor .
FILTER(?coauthor != :Alice)
}Advanced queries can include multiple patterns, optional matches, filters, aggregations, and reasoning rules, allowing for powerful data extraction and analysis.
SPARQL also supports federated queries, which can access multiple RDF datasets simultaneously. This is particularly valuable when combining data from separate repositories, such as publication databases and grant records. By combining patterns, filters, and joins, SPARQL allows users to extract insights that would be difficult or impossible using traditional database queries.
For example, the query above identifies all researchers who co-authored with Alice, lists the titles of their joint publications, and can be extended to filter results by date or topic. This demonstrates how SPARQL leverages the semantic richness of RDF to provide meaningful, context-aware answers.
Try Knowledge Graph with PuppyGraph
So far, we’ve seen how RDF can power knowledge graphs with semantic richness and reasoning capabilities. Meanwhile, another popular approach is the property graph model, widely used in many graph databases. Property graphs excel at efficiently modeling relationships and performing deep graph traversals, making them a versatile choice for many applications. However, traditional property graph implementations often require complex ETL pipelines, data duplication, and ongoing maintenance, which can slow down development and increase operational costs.

This is where PuppyGraph comes in. By querying your existing relational data sources directly as a unified graph, PuppyGraph eliminates the need for ETL or data migration while still providing the full power of a property graph model. You can define graph schemas on your live data, explore relationships across tables, and even interact with the graph through natural language using the PuppyGraph chatbot.

For example, using the Northwind dataset, you can instantly query customer orders, product relationships, and employee connections. With PuppyGraph’s chatbot, you can type questions in plain English, like “Which suppliers are associated with the products that appear most frequently in customer orders?” and get immediate answers, all without moving or duplicating your data. This hands-on approach demonstrates how PuppyGraph makes property graph-based knowledge graphs accessible, real-time, and easy to explore.
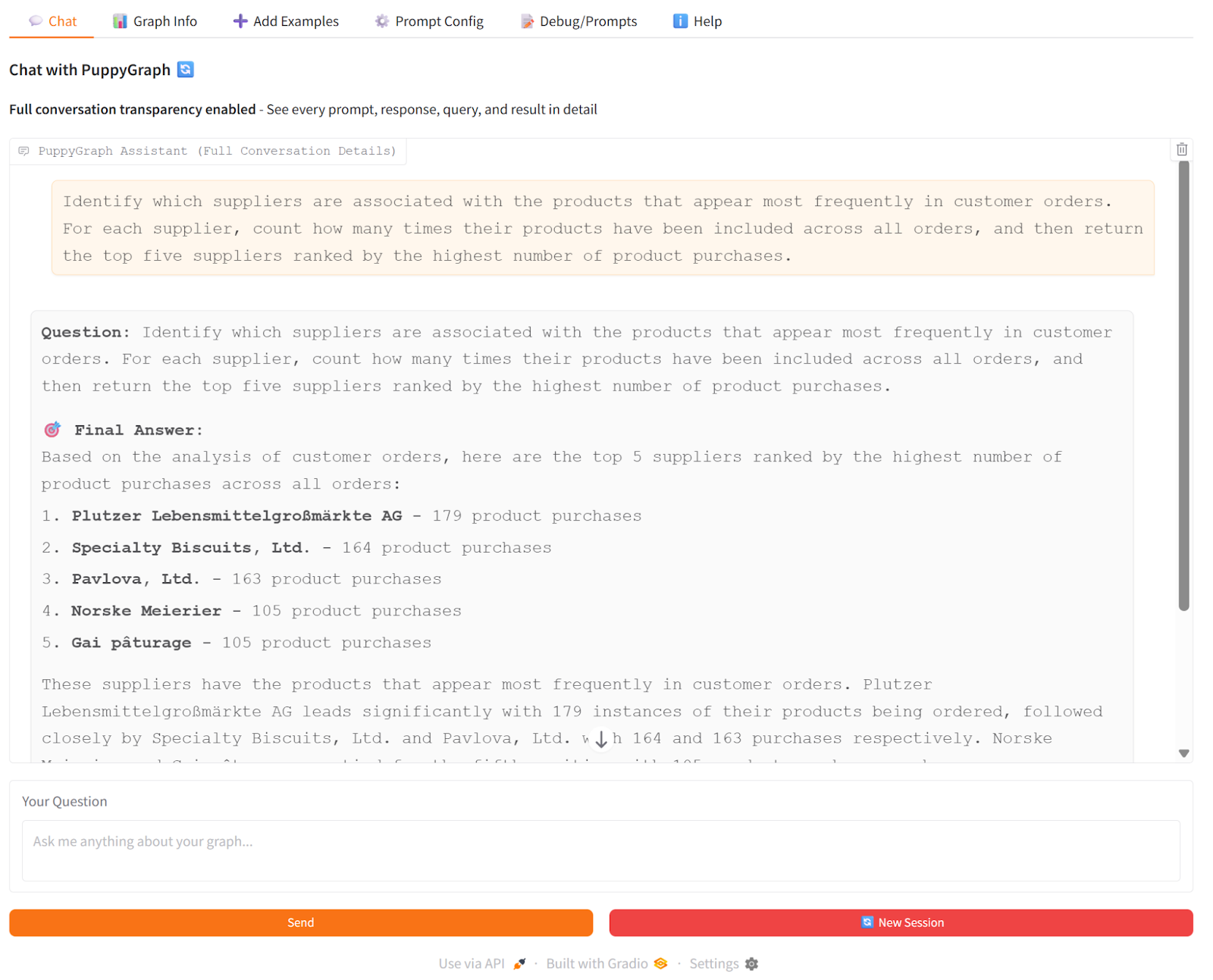
Click on ‘view detailed processing steps’, the UI will display more details of processing, including the generated Cypher query.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
RDF Knowledge Graphs transform how we structure and interpret data. By representing information as triples: subject, predicate, and object, they enable machines to understand both entities and their relationships. This semantic model supports reasoning, flexible evolution of data, and interoperability across diverse datasets, making RDF ideal for areas where context matters, from scientific research to enterprise knowledge management.
Unlike relational databases or property graphs, RDF emphasizes formal semantics and knowledge inference. With ontologies, typed literals, and SPARQL, RDF Knowledge Graphs allow complex queries, uncover hidden relationships, and integrate data from multiple sources. This combination of semantic depth and query power helps organizations extract actionable insights from interconnected information efficiently and accurately.
While RDF Knowledge Graphs offer semantic depth, many applications also benefit from property graphs’ efficiency for multi-hop queries. PuppyGraph applies property graph modeling directly on relational data, no ETL or duplication needed. Try PuppyGraph’s forever-free Developer Edition or book a demo with the team to walk through your use cases live.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install