

What is Semantic Knowledge Graph?
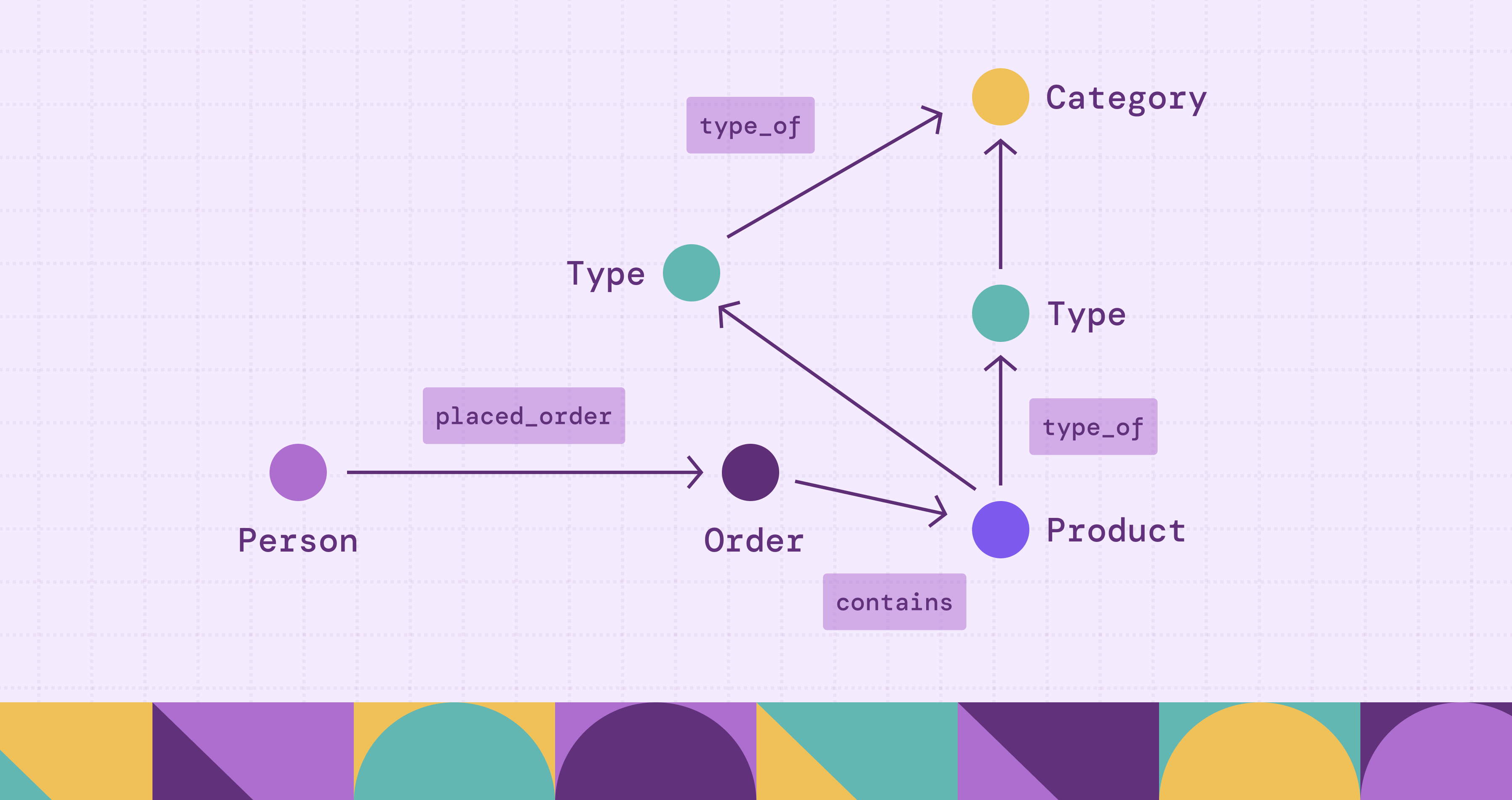
A Semantic Knowledge Graph (SKG) unifies instance-level data about entities with an ontology of abstract concepts, forming a graph that encodes both factual relationships and semantic meaning. The instance graph captures concrete entities, people, organizations, locations, and the edges between them, while the ontology graph defines concepts, types, hierarchies, and constraints. Explicit links between instances and ontology concepts ensure that every fact is grounded in shared meaning, enabling consistent interpretation, automated reasoning, and cross-system integration.
This article examines the key components and workings of SKGs, including entities, concepts, relationships, and schemas. It explains how data from heterogeneous sources can be integrated, enriched, and queried, and how inference allows implicit knowledge to be derived from explicit facts. The discussion also compares Semantic Knowledge Graphs with traditional knowledge graphs, highlighting their benefits, practical applications, and challenges in modeling, governance, and performance. By the end, readers will understand both the conceptual foundation and practical considerations for building and using SKGs effectively.
What Is a Semantic Knowledge Graph
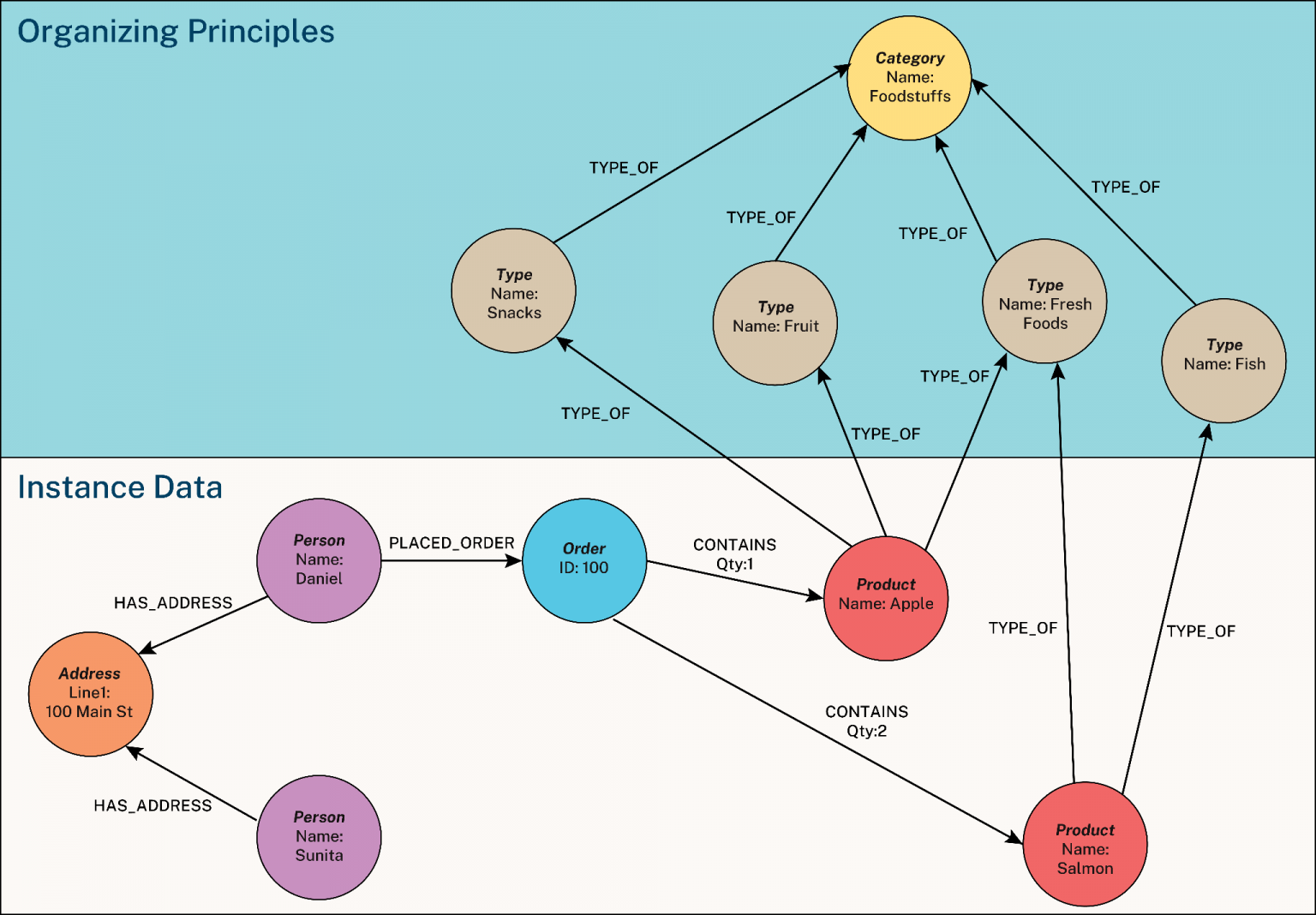
A Semantic Knowledge Graph is a unified knowledge representation that combines two interconnected graphs into a single coherent system:
- An instance graph, formed by relationships between concrete entities (instances)
- An ontology graph, formed by relationships between abstract concepts, types, and schemas
Together, with explicit links between them, they constitute a complete Semantic Knowledge Graph.
At the instance level, the graph captures real-world facts. Nodes represent specific entities such as Alice, Company A, or Berlin, and edges represent concrete relationships such as worksFor, locatedIn, or producedBy. This part of the graph answers “what exists” and “how things are connected in reality.”
At the ontology level, the graph defines meaning. Nodes represent concepts such as Person, Organization, or City, while edges describe semantic relationships like subClassOf, domain, range, or other logical constraints. This layer explains “what kinds of things exist” and “how concepts relate to each other.”
What makes the graph semantic is the explicit connection between these two layers: instance nodes are linked to ontology concepts (e.g., Alice → Person). These cross-layer edges ensure that every fact in the instance graph is grounded in shared meaning defined by the ontology.
For instance, entities like Alice and Company A form the instance graph, while concepts such as Person and Organization form the ontology graph. The edges connecting instances to concepts integrate factual data with semantic definitions, enabling consistent interpretation, reasoning, and reuse across systems.
Core Components of a Semantic Knowledge Graph
A Semantic Knowledge Graph is composed of several tightly connected components that together integrate instance-level facts, ontology-level semantics, and the explicit links between them. These components explain how semantic meaning is embedded directly into the graph structure, rather than being maintained as an external or informal layer.
Entities and Concepts
At the instance level, entities represent concrete, real-world objects such as a customer, a research paper, or a medical condition. These entities form the instance graph, where nodes correspond to individual objects and edges represent factual relationships between them.
At the ontology level, concepts represent abstract types or categories, such as Person, Organization, or Location. These concepts are typically organized into classes and hierarchies, forming an ontology graph that captures how concepts relate to one another.
A key semantic feature is the explicit connection between entities and concepts. Each entity is linked to one or more concepts that define its type (for example, Alice → Person). This cross-graph linkage grounds instance data in shared meaning and enables consistent interpretation across datasets and systems.
Relationships and Predicates
Relationships define how entities are connected within the instance graph, such as authorOf, worksFor, or locatedIn. Unlike generic edges, these relationships carry explicit semantic intent. At the ontology level, relationships themselves are also modeled as concepts or predicates, with defined meaning and constraints.
These semantic relationships may include constraints such as allowed source and target types (domain and range), as well as hierarchical relations between predicates. This structure enables validation, consistency checking, and reasoning over both the data and its meaning.
Ontologies and Schemas
Ontologies provide the conceptual backbone of a Semantic Knowledge Graph. They define the vocabulary of concepts, the relationships between those concepts, and the rules that govern how they can be connected. This ontology graph ensures that data from different sources conforms to a shared semantic model.
Schemas describe how concepts are structured and related, often hierarchically. For example, an ontology may specify that Professor is a subtype of Person, or that Book is a subtype of Publication. These relationships allow systems to infer implicit knowledge from explicit facts in the instance graph.
How Semantic Knowledge Graphs Work
Semantic Knowledge Graphs transform raw data into structured, meaningful knowledge by combining data integration, semantic modeling, graph storage, and inference within a single, unified graph. Their operation can be understood as the coordinated evolution of an instance graph, an ontology graph, and the explicit links between them.
Data Ingestion and Integration
The process begins with ingesting data from multiple heterogeneous sources, such as relational databases, APIs, documents, logs, or streaming systems. These sources typically differ in format, schema, and naming conventions, making direct integration difficult.
In a Semantic Knowledge Graph, this challenge is addressed by mapping source data into a shared semantic model. During ingestion:
- concrete records are converted into instance nodes and relationships
- these instances are aligned with ontology-level concepts and predicates
- identifiers are normalized so that the same real-world entity is represented consistently across sources
Rather than simply merging schemas, this step builds an instance graph whose nodes and edges are explicitly linked to the ontology graph, allowing data from different systems to interoperate through shared meaning.
Semantic Annotation and Enrichment
After ingestion, the graph is enriched with semantic annotations that connect instance-level elements to ontology definitions. These annotations make meaning explicit rather than implicit.
For example, a value such as “Paris” can be linked to a specific concept like City rather than treated as a plain string, and further associated with France through ontology-defined relationships.
Enrichment may also involve linking instance nodes to external reference graphs or knowledge bases (such as Wikidata), adding additional attributes, identifiers, or relationships. These external links expand the semantic context without duplicating data.
Storage and Querying
Semantic Knowledge Graphs can be stored and queried using different graph data models. These models differ in how entities, relationships, and ontology concepts are represented, and in how instance-level data is connected to semantic definitions. The following sections describe how Semantic Knowledge Graphs are expressed and queried in RDF graphs, property graphs, and labeled property graphs.
RDF Graphs
In RDF-based systems, all knowledge is represented as triples composed of a subject, a predicate, and an object. Both instance data and ontology definitions use this same triple structure. Nodes represent resources, which may correspond to concrete entities or abstract concepts, while edges are represented by predicates, also referred to as properties.
The type of an instance is expressed explicitly using the rdf:type predicate, which connects an instance node to a class defined in the ontology. For example, the statement that Alice is a Person is modeled as a triple linking the resource Alice to the class Person via rdf:type. Relationships between instances, such as employment or location, are also represented as properties connecting resources.
The ontology in RDF is itself a graph defined using the same syntax. It consists of classes, relationships between classes, and semantic constraints, commonly expressed using vocabularies such as RDFS or OWL. Class hierarchies are modeled using predicates like rdfs:subClassOf, and properties may declare domains and ranges that describe how they can be applied. Because ontology triples and instance triples coexist in the same RDF graph, queries written in SPARQL can traverse seamlessly across instance relationships, type assignments, and ontology hierarchies.
Property Graphs
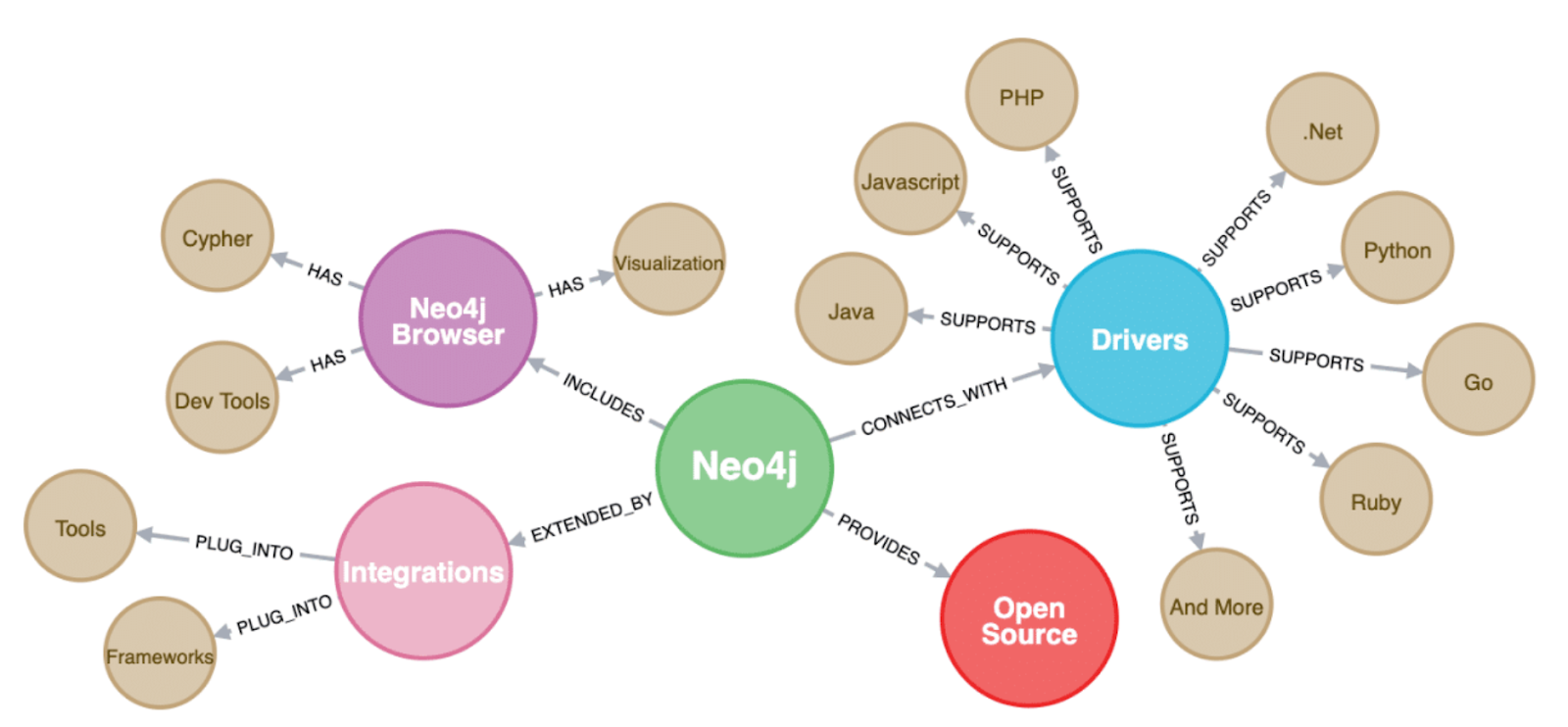
In the property graph model, a Semantic Knowledge Graph is represented using nodes and edges, both of which may carry properties. In this setting, the ontology is modeled explicitly as a graph structure, in the same way as instance data. Ontology concepts such as Person or Organization are represented as nodes, and relationships between concepts, such as subclass or conceptual dependency, are represented as edges between those nodes.
Instance data is also represented as nodes and edges, where nodes correspond to concrete entities and edges represent factual relationships. The connection between the instance graph and the ontology graph is made explicit through edges that link instance nodes to ontology nodes. For example, an instance node representing Alice may be connected to a concept node representing Person through a relationship that expresses type membership.
With this approach, both instance-level facts and ontology-level semantics are part of a single graph, distinguished by their role rather than by their structure. Queries written in graph query languages such as Cypher or Gremlin can traverse instance-to-instance relationships, move from instances to their associated concepts, and continue through relationships within the ontology graph.
Labeled Property Graphs
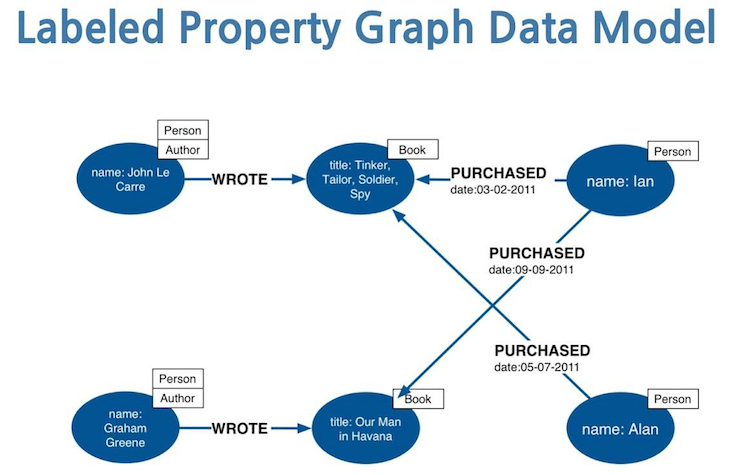
In labeled property graphs, nodes may carry one or more labels, and edges are assigned relationship types. Labels are commonly used to represent the concepts to which an instance belongs. For example, an instance node labeled Person indicates that the entity represented by the node is associated with the concept Person. An instance may have multiple labels, reflecting association with multiple concepts.
In this model, the link between an instance and a concept is encoded directly in the node’s labels rather than as an explicit edge to a concept node. This provides a direct way to represent concept membership at the instance level. Queries written in languages such as Cypher or Gremlin can use labels to select and filter instance nodes based on their associated concepts.
Relationships between concepts, such as inheritance or conceptual structure, are not represented by labels alone. To model these relationships, an explicit ontology graph must still be constructed, with concept nodes and edges connecting them, similar to the approach used in property graphs. Queries can then combine label-based instance selection with traversals over the ontology graph when concept-to-concept relationships are required.
Reasoning and Inference
A defining capability of Semantic Knowledge Graphs is inference, where new knowledge is derived from existing facts and ontology definitions.
At the ontology level, relationships such as subClassOf define conceptual hierarchies. When instance nodes are linked to these concepts, inference can be performed either explicitly (by materializing inferred edges) or implicitly (at query time).
For example, if:
- an instance node Alice is linked to Professor
- the ontology defines Professor as a subtype of Academic
then the system can infer that Alice is an Academic, even if that relationship was never directly stored.
In RDF systems, this inference is often handled by dedicated reasoning engines. In property graph-based systems, similar behavior can be achieved through:
- graph traversals over ontology relationships
- query-time inference logic in Cypher or Gremlin
- or precomputed semantic expansions stored as additional edges
The result is the same: queries and analytics can operate over both explicit facts and implied knowledge, enabling more intelligent search, analysis, and decision-making.

Benefits of Semantic Knowledge Graphs
Semantic Knowledge Graphs extend traditional knowledge graphs by integrating an ontology graph with the instance graph, and by explicitly linking the two. This additional semantic layer transforms the graph from a collection of connected facts into a system that encodes shared meaning, structure, and constraints. The benefits of this approach become especially clear when compared to knowledge graphs that model instances and relationships only.
Improved Data Integration through Shared Semantics
Traditional knowledge graphs integrate data mainly through structural links and application-specific conventions. When the same real-world concept is modeled differently across sources, ambiguity and duplicated logic often arise. Without a shared semantic reference, integration depends heavily on manual alignment and fragile assumptions.
Semantic Knowledge Graphs resolve this by introducing an explicit ontology graph. Data from heterogeneous systems is mapped to shared concepts and predicates, enabling meaning-based integration. New data sources can be added incrementally by reusing existing ontology definitions, reducing long-term integration cost and improving architectural stability.
Enhanced Search and Discovery via Conceptual Understanding
Search in traditional knowledge graphs relies on exact labels, properties, or known relationship patterns. This works well for predefined queries but performs poorly when users do not know the underlying schema or terminology used in the data.
Semantic Knowledge Graphs enable concept-level search by linking instances to ontology concepts. Queries can traverse conceptual hierarchies and semantic relationships, not just literal edges. As a result, users can discover relevant entities through shared meaning, even when exact keywords or structures are absent.
Stronger Support for AI and Machine Learning
Ordinary knowledge graphs expose connected data, but much of the semantic intent remains implicit. Machine learning models must infer structure and meaning during training, which limits reuse, interpretability, and consistency across applications.
Semantic Knowledge Graphs make domain knowledge explicit through an ontology graph combined with grounded instance data. This provides semantically rich features for learning, supports explainable AI by tracing reasoning paths, and improves natural language understanding through alignment with shared conceptual models.
More Effective Knowledge Management and Governance
In many organizations, traditional knowledge graphs reflect data storage structures rather than conceptual understanding. Over time, this leads to fragmented representations, hidden assumptions, and growing maintenance complexity.
Semantic Knowledge Graphs separate conceptual definitions from factual instances. The ontology graph captures formal domain knowledge, while the instance graph records evolving facts. Their explicit linkage enables consistency, controlled evolution, and shared understanding, turning the graph into a sustainable foundation for governance and decision-making.
Semantic Knowledge Graph vs Traditional Knowledge Graph
Although the terms knowledge graph and semantic knowledge graph are sometimes used interchangeably, they describe two structurally different approaches. The key distinction is whether the graph contains only instance-level data, or whether it also includes an explicit ontology graph that is connected to those instances.
Traditional Knowledge Graph
A traditional knowledge graph mainly contains an instance graph. Nodes represent concrete entities such as people, companies, or places, and edges represent factual relationships like worksFor or locatedIn. This model is effective for capturing entity connections and is widely used in areas such as recommendation systems, social networks, and fraud detection.
However, semantics are mostly implicit. The meaning of entities and relationships is typically encoded in application logic or documentation rather than in the graph itself. As a result, different systems may interpret similar structures differently, making reuse, interoperability, and cross-domain integration more difficult.
Semantic Knowledge Graph
A Semantic Knowledge Graph extends the instance graph with an explicit ontology graph. In addition to concrete entities, it includes concepts such as Person or Organization and conceptual relationships like subClassOf. Instance nodes are explicitly typed and linked to these ontology elements.
This integration makes semantics explicit and machine-interpretable. The graph captures not only which entities are connected, but also what those connections mean, enabling consistent interpretation, shared understanding, and automated reasoning across systems.
Key Differences in Practice
Traditional knowledge graphs are well suited for scenarios where performance and fixed structures matter most. Queries typically rely on known labels and explicit paths, with semantics handled outside the graph.
Semantic Knowledge Graphs support conceptual queries and inference. Ontology definitions allow queries to operate at a higher level of abstraction, such as including subclasses automatically or navigating conceptual hierarchies. The difference is conceptual rather than technical, since both approaches can use the same graph storage and query languages.
Choosing Between the Two
The choice depends on requirements. Traditional knowledge graphs are sufficient for fast traversal within a single application and stable domain. Semantic Knowledge Graphs are preferable when shared meaning, schema evolution, reasoning, and cross-domain integration are important.
A Semantic Knowledge Graph is not a different database technology, but a more disciplined modeling approach. By combining instance data with explicit ontology semantics, it creates a unified graph that is more expressive, reusable, and resilient over time.
Challenges & Limitations
Introducing an ontology graph and explicitly linking it with the instance graph fundamentally changes how a knowledge graph is modeled, queried, and governed. While this enables richer semantics and reasoning, it also introduces a distinct set of challenges that do not typically arise in instance-only knowledge graphs.
Ontology Design and Evolution
The most fundamental challenge lies in ontology design. An ontology graph encodes domain concepts, relationships, and constraints, and therefore requires deep domain understanding and careful abstraction. Poorly designed ontologies can introduce ambiguity, overly rigid structures, or hidden assumptions that propagate throughout the instance graph.
Unlike instance data, ontologies evolve more slowly but have broader impact. Changes to concept hierarchies or relationship definitions can affect queries, inference behavior, and downstream applications. As a result, Semantic Knowledge Graphs often require explicit governance processes for ontology versioning, review, and controlled extension, costs that do not exist in traditional knowledge graphs.
Performance, Scalability, and Architectural Trade-offs
Semantic Knowledge Graphs support inference by traversing ontology relationships (such as subclass hierarchies) and applying semantic constraints across the instance graph. These operations increase query complexity and can impact performance at scale.
In practice, systems must decide how much semantic reasoning to perform, and when. A common architectural pattern is to separate concerns:
- the instance graph is optimized for high-volume data ingestion and fast traversal
- the ontology graph is smaller, more stable, and used for semantic expansion, validation, or query rewriting
Some systems materialize inferred relationships in advance, while others compute them at query time. This is what is meant by combining semantic and non-semantic components: not different databases, but different layers of the same graph with different performance and reasoning characteristics. Balancing semantic depth against latency and throughput is a core design trade-off.
Data Quality and Consistency
Because Semantic Knowledge Graphs integrate data from multiple sources through a shared ontology, data quality issues become more visible, and more impactful. Incorrect mappings between source data and ontology concepts can lead to misleading inferences and inconsistent interpretations across the graph.
Unlike traditional knowledge graphs, where errors are often localized, semantic errors propagate through ontology-based reasoning. Maintaining quality therefore requires validation mechanisms, constraint checks, and continuous monitoring to ensure that instance data remains consistent with ontology definitions.
Skills and Semantic Tooling
Building and operating a Semantic Knowledge Graph requires skills beyond general graph modeling. Teams must understand:
- how to model concepts and relationships in an ontology graph
- how to link instance data to ontology definitions
- how to express semantic queries that traverse both layers
Tooling reflects this distinction. In addition to standard graph database capabilities (storage, traversal, indexing), semantic-specific tools are typically involved in:
- ELT and mapping: transforming source data into instance nodes and aligning them with ontology concepts
- ontology management: editing, versioning, and governing the ontology graph
- semantic querying: expanding or rewriting queries to account for concept hierarchies and semantic relationships
- validation and inference: checking constraints and deriving implied relationships
These capabilities can be implemented using RDF-based stacks, property graph databases with Cypher or Gremlin, or hybrid approaches. Regardless of the technology, the tooling exists to manage meaning, not just connectivity. Selecting and integrating these tools, and building the necessary expertise, requires deliberate investment.
Why PuppyGraph
Semantic Knowledge Graphs can be represented using different graph models and query languages. In RDF, both instance data and ontology definitions are uniformly encoded as triples, with instance-concept links expressed via predicates such as rdf:type, and concept-concept relationships (including subclass/ontology hierarchies) explicitly represented as edges within the ontology and queried using SPARQL. In property graph models, both instances and ontology concepts are represented as nodes in the same graph, with explicit edges linking instances to concepts, as well as edges between concepts to capture ontology hierarchies and semantic relationships. Labeled property graphs encode instance-concept associations primarily through node labels, allowing instances to be typed with one or more concepts, while concept-concept relationships and hierarchies are still modeled explicitly as edges in a separate or integrated ontology graph and traversed using graph query languages such as Cypher or Gremlin.
Traditionally, adopting a graph model requires ETL: data must be copied into a graph database, introducing duplication, latency, and maintenance overhead. This approach also disconnects the graph from live source data.
PuppyGraph, eliminate this need. By supporting Labeled Property Graphs and standard graph query languages, PuppyGraph enables real-time queries over existing relational or lakehouse data, combining semantic expressiveness with zero-ETL, live access, and simplified management.
For the purpose of illustration, let’s deploy the dataset Northwind on PuppyGraph:
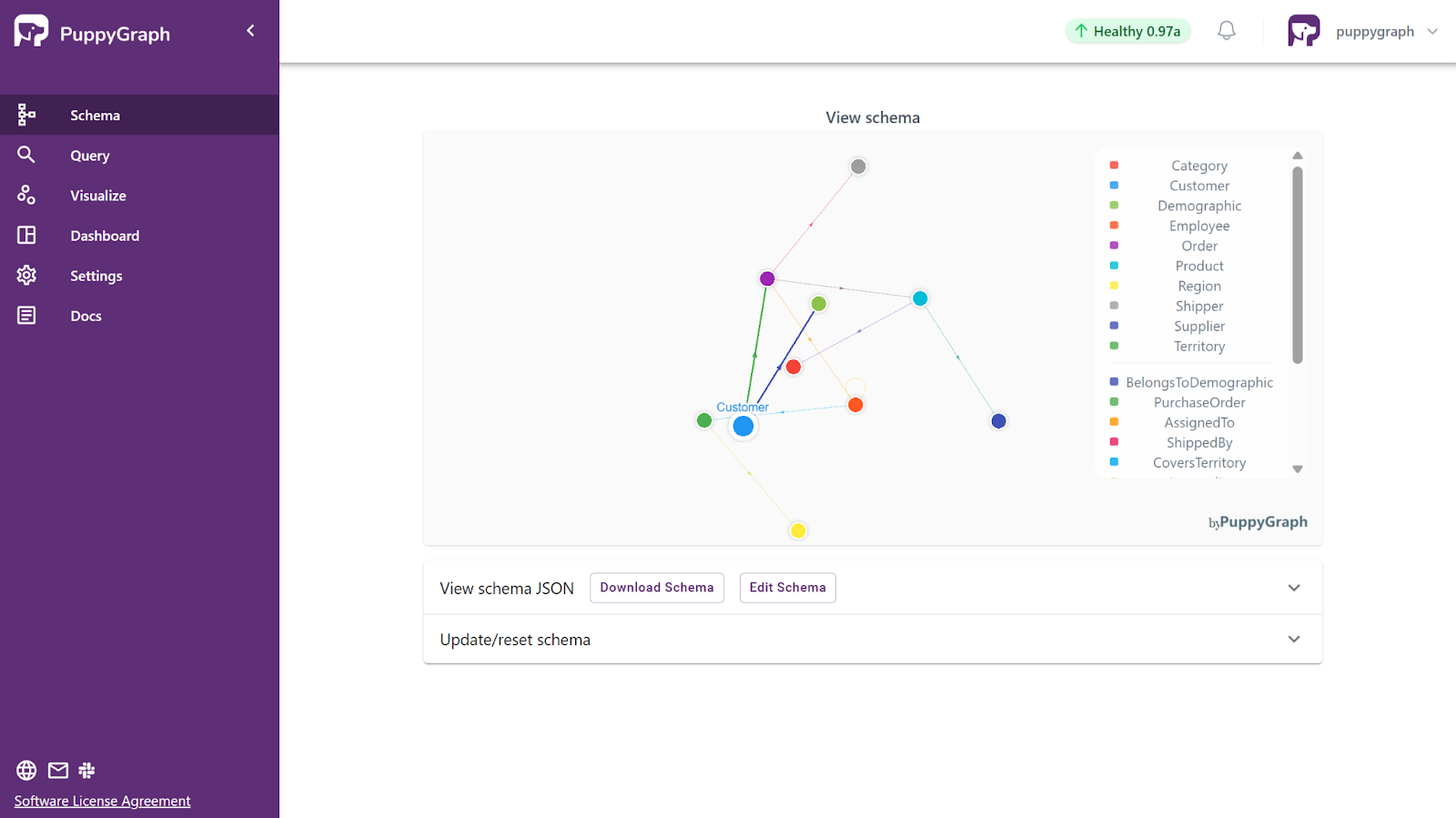
In the screenshot above, you can see how PuppyGraph maps the tables into nodes and edges automatically: customers link to their orders, orders link to products, and employees link to the orders they are responsible for. Once the graph view is defined, you can run a Gremlin or Cypher query against the dataset directly, surfacing insights that would require complex joins or custom pipelines in SQL.

Then we can see how this experience becomes even more intuitive with the PuppyGraph Chatbot. Instead of writing queries, users can simply ask natural language questions like “Which suppliers are associated with the products that appear most frequently in customer orders?” The chatbot interprets the intent, generates the appropriate graph query, and returns structured results. This turns your knowledge graph into an interactive exploration environment where business users, analysts, and engineers can all navigate multi-hop relationships without needing to learn a graph language.
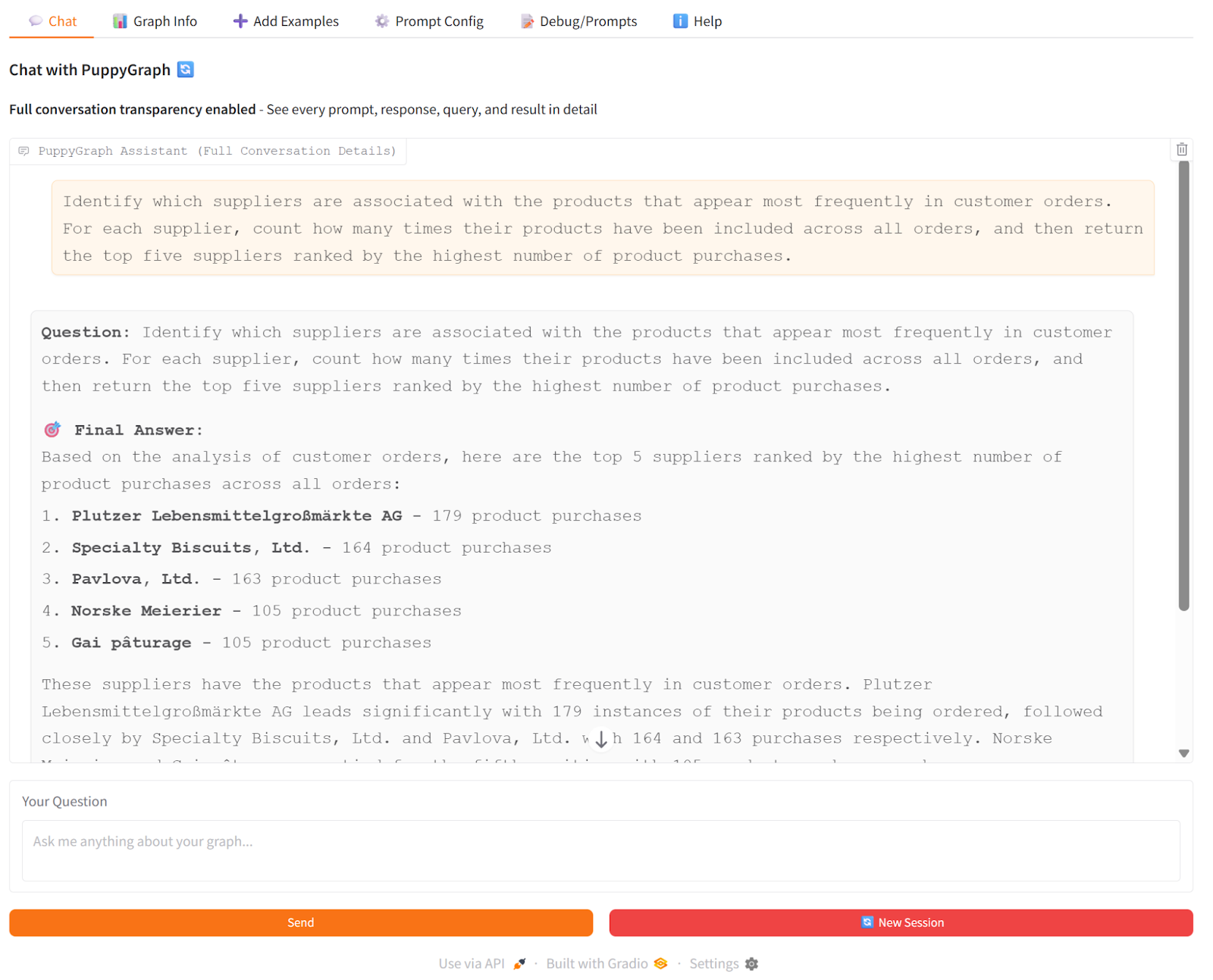
Click on ‘view detailed processing steps’, the UI will display more details of processing, including the generated Cypher query.


PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Semantic Knowledge Graphs extend traditional knowledge graphs by explicitly linking instance data to an ontology, making both entities and their relationships semantically typed and machine-interpretable. This integration enables consistent interpretation, automated reasoning, and inference across datasets. SKGs support richer queries, improved data integration, concept-level search, and more effective knowledge management, turning raw connections into actionable, meaningful insights. By combining factual data with formalized semantics, they provide a resilient and reusable foundation for AI, analytics, and cross-domain applications.
To leverage these benefits in practice, PuppyGraph provides a real-time, zero-ETL graph query engine that operates directly on existing relational and lakehouse data. It allows teams to query live data without duplication or ETL pipelines, supporting multi-hop queries at scale. By integrating instance-level data with semantic structure, PuppyGraph enables fast, scalable, and concept-aware analysis, helping organizations explore complex relationships, reason over connected data, and extract insights efficiently while maintaining consistency and governance.
Download the forever free PuppyGraph Developer Edition, or book a demo with our engineering team to see how you can build and query a real-time Semantic Knowledge Graph in minutes.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install