

What is Software Supply Chain?
The software supply chain refers to the entire set of processes, tools, components, people, and systems involved in developing, building, delivering, and maintaining software. Much like a physical supply chain moves raw materials into finished products, a software supply chain moves source code and dependencies from conception to deployment. Modern applications depend on open‑source packages, third‑party libraries, commercial tools, and automated build systems, which means the surface area for risk grows as complexity increases. Understanding these supply chains is now essential to protect software against malicious threats, accidental vulnerabilities, and compliance failures.
What Is the Software Supply Chain
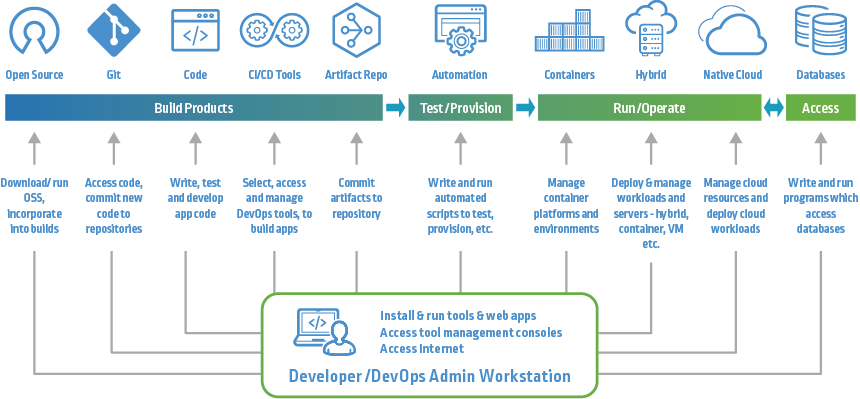
A software supply chain encompasses more than just code. It represents the entire lifecycle of a piece of software, from ideation through development, testing, deployment, and ongoing maintenance. This system includes developers, repositories, compilers, build servers, libraries, APIs, containers, and distribution mechanisms. Software teams rarely create every component from scratch, instead relying on third‑party open‑source and commercial software packages. These dependencies are integrated into applications and must be secured throughout their lifecycle. The concept extends to continuous integration/continuous delivery (CI/CD) pipelines and automated tooling, where automated processes help deliver software at speed but also introduce unique vulnerabilities if left unchecked. At its core, the software supply chain is about trust: trusting every component and tool that participates in creating and delivering software to end users.
Modern software supply chains are global, distributed, and highly automated, making them effective but complex. Each connection between tools and systems introduces risk, and attackers increasingly exploit these intricate linkages to gain unauthorized access, manipulate code, or introduce malware. Software supply chain security, therefore, is not just a buzzword, it’s an essential discipline for any organization that relies on software to run its business or deliver services. With attacks on well‑known projects making headlines, understanding how supply chains function and where they fail is key to protecting digital assets and reputations.
Key Components of the Software Supply Chain
The software supply chain comprises components that interact in layers, often graphically represented as a chain or ecosystem of interconnected tools and artifacts:
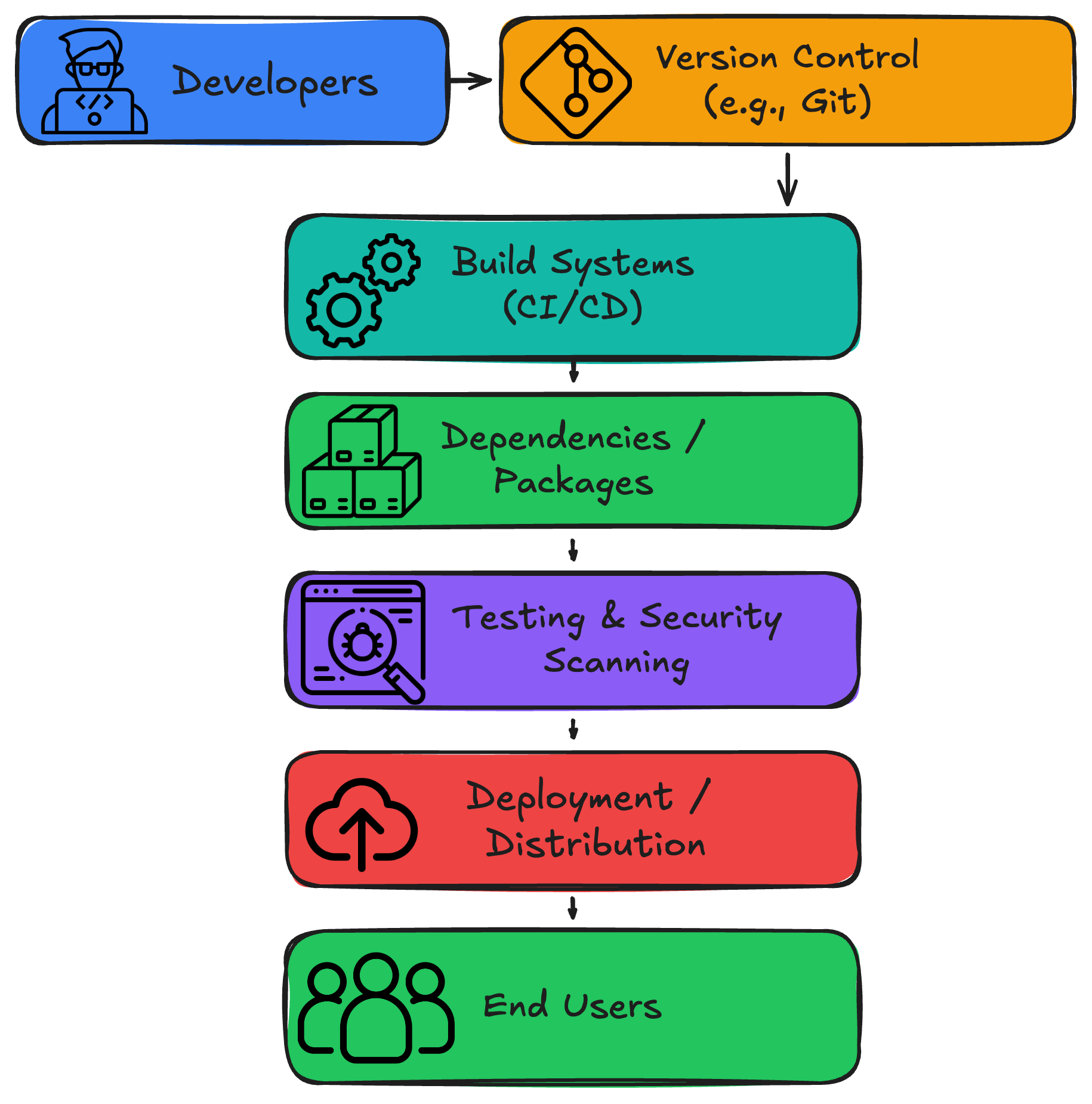
At the foundation are developers, who write code and define requirements. Their work lives in version control systems such as Git repositories, where changes are tracked and shared. Build systems and CI/CD pipelines automatically compile, test, and package code to prepare it for release. During this process, the software consumes dependencies, external libraries and frameworks essential to functionality. These dependencies are often pulled from public repositories (npm, PyPI, Maven Central, etc.), and each represents a potential risk point. Once built, code is subject to testing and security scanning, where tools check for known vulnerabilities, license issues, and hidden malware. Finally, artifacts are deployed and distributed to production environments or delivered to customers, where end users interact with the final product.
Hidden within these components are numerous micro‑interactions and integrations. For example, a CI/CD pipeline might include automated unit tests, static analysis tools, container builders, artifact repositories, and deployment scripts. All of these interact in automated workflows, and each interaction must be monitored and secured to prevent unauthorized access or malicious code injection. The software supply chain encompasses both the logical life cycle (code changes) and the physical infrastructure (servers, pipelines, cloud services) that execute it.
Graph Perspective
The software supply chain can be represented as a connected graph, where nodes correspond to components: developers, code repositories, libraries, build servers, deployment pipelines, and end users, and edges represent interactions or dependencies between them. Visualizing the supply chain as a graph helps teams understand how a change or vulnerability in one component can propagate through the system, enabling more effective risk assessment, impact analysis, and security planning.
Why Software Supply Chain Security Matters
Software supply chain security is critical because modern applications depend on open-source libraries and third-party services developed outside an organization’s control. While these components accelerate development, they also introduce hidden vulnerabilities and trust risks. A single compromised dependency can spread malicious code across thousands of systems, leading to data breaches, ransomware, and unauthorized access to critical infrastructure.
Supply chain weaknesses also create regulatory and operational risks. Frameworks such as the U.S. Executive Order on Cybersecurity and the EU NIS2 Directive require organizations to manage third-party risk. Even secure in-house code can be undermined by insecure dependencies, resulting in compliance failures, downtime, financial loss, and reputational damage. Because supply chain attacks often exploit trusted systems, they can remain undetected for long periods, amplifying their impact.
Given the complexity of modern development, supply chain security must be addressed early in the software lifecycle. Proactive investment reduces exposure to evolving threats and is essential across both regulated industries and consumer applications.
Common Software Supply Chain Attacks
Common software supply chain attacks typically exploit trust, automation, and hidden dependencies across the development lifecycle. Key attacks include:
- Compromised third-party dependencies
Attackers inject malicious code into widely used open-source libraries or package repositories. Once developers unknowingly import these dependencies, the malicious code propagates into many downstream applications, often without immediate detection. - Credential theft and CI/CD pipeline abuse
By stealing developer or CI/CD credentials, attackers gain access to build systems and insert unauthorized code during automated builds. Because the process appears legitimate, the malicious artifacts can pass tests and be distributed unnoticed. - Dependency confusion and typosquatting
Dependency confusion attacks exploit misconfigured package resolution, causing systems to pull malicious public packages instead of internal ones. Typosquatting similarly relies on naming mistakes, where developers install malicious packages with names resembling popular libraries. - Build infrastructure compromise
Build servers often run with high privileges and minimal oversight. If compromised, attackers can modify build artifacts directly, making the attack difficult to detect through traditional code reviews or logging. - Insider threats and insufficient monitoring
Developers or administrators with privileged access may intentionally or accidentally introduce vulnerabilities. Without strong access controls and continuous log monitoring, such actions can remain undetected for long periods.
Software Supply Chain Security Best Practices
Securing the software supply chain requires a holistic approach that embeds security into every stage of development, from planning to deployment. A clear, step-by-step strategy ensures both visibility and control while integrating best practices along the way:
- Inventory and Visibility: Start by cataloging all components, libraries, and dependencies using a Software Bill of Materials (SBOM). SBOMs provide a complete view of what your software includes, enabling teams to quickly spot vulnerabilities, license risks, or malicious code before they affect production. Complement this with dashboards and observability tools that track build health, dependency status, and compliance in real time.
- Integrate Security in CI/CD: Adopt a DevSecOps mindset, embedding automated security checks directly into CI/CD pipelines. Use static and dynamic analysis, container scanning, dependency monitoring, and policy enforcement to block risky code early. Policy‑as‑code ensures rules are applied consistently, reducing human error and aligning with organizational risk standards.
- Access and Secrets Management: Enforce least‑privilege identity and access management (IAM) for build systems, repositories, and deployment tools. Secure credentials with secrets management systems and encryption to prevent unauthorized access to critical infrastructure.
- Incident Preparedness: Plan and rehearse responses to compromised dependencies or builds. This includes mechanisms for rollback, artifact quarantining, and stakeholder communication. Regular audits, penetration tests, and tracking compliance with emerging standards help detect weaknesses before attackers exploit them.
- Continuous Risk Optimization: Establish governance frameworks that define responsibilities, risk scoring, and approval processes for components. Automate vulnerability scanning, threat intelligence integration, and remediation workflows to maintain security at scale. Train developers to interpret SBOMs, vulnerability reports, and dependency trees so they can make safer design and coding choices.
By following this structured approach, organizations embed security into the supply chain rather than treating it as an afterthought, continuously reducing risk while enabling safe and efficient software delivery.
Challenges in Securing the Software Supply Chain
Securing the software supply chain is a complex task, and organizations face multiple challenges that stem from technical, organizational, and operational factors:
- Dependency Proliferation: Modern applications often rely on thousands of open‑source libraries and transitive dependencies, each with different maintenance and security levels. Tracking these components and assessing their risk profiles is difficult without comprehensive tooling and automation, making vulnerability prioritization a persistent challenge.
- Organizational Silos: Development, operations, and security teams frequently work in isolation, which can lead to misaligned priorities and delayed threat responses. Overcoming these silos requires cultural changes, process restructuring, and improved communication to ensure shared accountability for security.
- Third‑Party Services and Cloud Complexity: The growing reliance on external vendors and cloud-native infrastructure introduces additional layers of risk. Many organizations have limited visibility into their suppliers’ internal security practices, leaving potential blind spots that attackers can exploit despite contractual agreements or compliance certifications.
- Balancing Velocity and Security: Rapid development and deployment cycles put pressure on teams to deliver features quickly, sometimes at the expense of thorough security vetting. Successfully balancing speed and safety requires automation, developer training, and continuous monitoring to maintain both productivity and robust security.
Real-Time Graph Insight for Software Supply Chain Security
As organizations mature their software supply chain security practices, they often come to realize that simply knowing which components exist is only the beginning. Understanding how those components relate, interact, and propagate risk across environments is where real security insight is created. Traditional security tools often operate in silos, vulnerability scanners list affected packages, CI/CD tools log build events, and asset inventories track deployments, but they struggle to explain how these pieces connect into a coherent system.
Modern software supply chains can be represented as interconnected graphs, where components and dependencies form nodes and edges that trace how changes and risks propagate through the system. Dependencies form deep and dynamic graphs, CI/CD pipelines link identities, artifacts, and infrastructure, and a single compromised component can cascade across teams, services, and environments. Answering critical questions: Which applications are impacted by this vulnerable library? How does a compromised build credential propagate to production systems? What is the blast radius of a malicious dependency? requires reasoning across many hops of interconnected data in real time.
This is where graph-based analysis becomes essential. By modeling software supply chains as graphs rather than flat lists or isolated dashboards, security teams can trace attack paths, prioritize risk based on actual exposure, and respond faster to emerging threats. However, traditional graph databases often introduce operational overhead, data duplication, and latency that conflict with the speed and scale of modern DevSecOps workflows.
This is where PuppyGraph comes in.
What is PuppyGraph

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Modern software development relies on complex, distributed supply chains that integrate code, dependencies, tools, and infrastructure across multiple teams and environments. Each component introduces potential risks, from malicious code in third-party libraries to compromised CI/CD pipelines, making supply chain security essential for protecting applications, data, and organizational reputation. Traditional monitoring and vulnerability management approaches often fall short in tracing multi-layered dependencies and dynamic interactions.
PuppyGraph addresses these challenges by providing a real-time, zero-ETL graph query engine that enables teams to model, analyze, and secure their software supply chains without duplicating data. By representing dependencies and interactions as a live graph, organizations can perform multi-hop impact analysis, detect vulnerabilities, and respond to threats faster. Its scalable, in-place querying capability ensures actionable insights across massive datasets, reducing operational overhead while empowering proactive, relationship-aware security management.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install