

SQL Query Optimization: Techniques and Steps
SQL query optimization is a fundamental aspect of database management that focuses on improving the efficiency of SQL statements. As modern applications generate and process increasing volumes of data, poorly performing queries can lead to slow response times, excessive resource consumption, and reduced user satisfaction. Effective optimization helps database systems retrieve and manipulate data more efficiently while maintaining high performance and reliability.
This article explores the principles and importance of SQL query optimization, explains how database optimizers generate execution plans, and examines common causes of slow queries. It also discusses key optimization techniques, including indexing strategies, query design improvements, execution plan analysis, and ongoing performance monitoring, providing practical guidance for building scalable and efficient database systems.
What Is SQL Query Optimization?
SQL query optimization refers to the process of improving the efficiency of SQL statements so that the database engine can retrieve and manipulate data with minimal resource consumption. The primary goal is to reduce execution time, lower CPU and memory usage, and minimize disk I/O operations.
When a SQL query is submitted, the database management system (DBMS) does not simply execute the statement as written. Instead, it analyzes the query and determines the most efficient execution strategy. This process involves evaluating possible access paths, selecting indexes, determining join methods, and estimating costs associated with different execution plans.
Modern database systems such as MySQL, PostgreSQL, SQL Server, and Oracle include sophisticated query optimizers. These optimizers automatically generate execution plans based on available statistics and metadata. However, even advanced optimizers cannot always compensate for poorly written queries, missing indexes, or outdated statistics.
SQL query optimization combines automated database mechanisms with manual tuning practices. Developers and database administrators often work together to identify inefficient queries and refine them for better performance.
Understanding optimization is especially important in environments where thousands of users access the database simultaneously. Small inefficiencies can quickly accumulate and impact overall system responsiveness.
Why SQL Query Optimization Matters
Database performance directly affects application performance. Slow queries can lead to delayed page loads, poor user experiences, increased server costs, and reduced productivity. As organizations collect more data, optimization becomes increasingly important.
One of the most significant benefits of SQL query optimization is reduced response time. Faster queries allow applications to retrieve information quickly, creating smoother interactions for end users. In e-commerce systems, even a slight delay in database response can negatively affect conversion rates and customer satisfaction.
Optimization also improves resource utilization. Efficient queries require fewer CPU cycles, less memory, and reduced disk activity. This allows organizations to support more users and larger workloads without continuously investing in additional hardware.
Another important benefit is scalability. As data volumes grow from thousands to millions or billions of rows, optimized queries maintain acceptable performance levels. Without proper optimization, systems that initially perform well may become unusable under increasing demand.
Furthermore, optimized queries contribute to system stability. Poorly designed SQL statements can create locks, consume excessive resources, and affect other users. By reducing query execution times, organizations can minimize contention and improve overall database reliability.
How SQL Query Optimization Works
Query optimization involves multiple stages that occur between the moment a SQL statement is submitted and the moment results are returned. Understanding this process helps developers identify potential performance bottlenecks.
The first stage is query parsing. During parsing, the database validates the syntax of the SQL statement and converts it into an internal representation. If syntax errors are detected, execution stops immediately.
Next comes query rewriting. The optimizer may transform the query into an equivalent form that is easier to execute efficiently. For example, redundant conditions may be removed, or subqueries may be rewritten as joins.
The optimizer then evaluates multiple execution strategies. It considers factors such as table sizes, available indexes, data distribution, and estimated costs. Based on these estimates, the optimizer selects the most efficient execution plan.
The following diagram illustrates the optimization workflow:
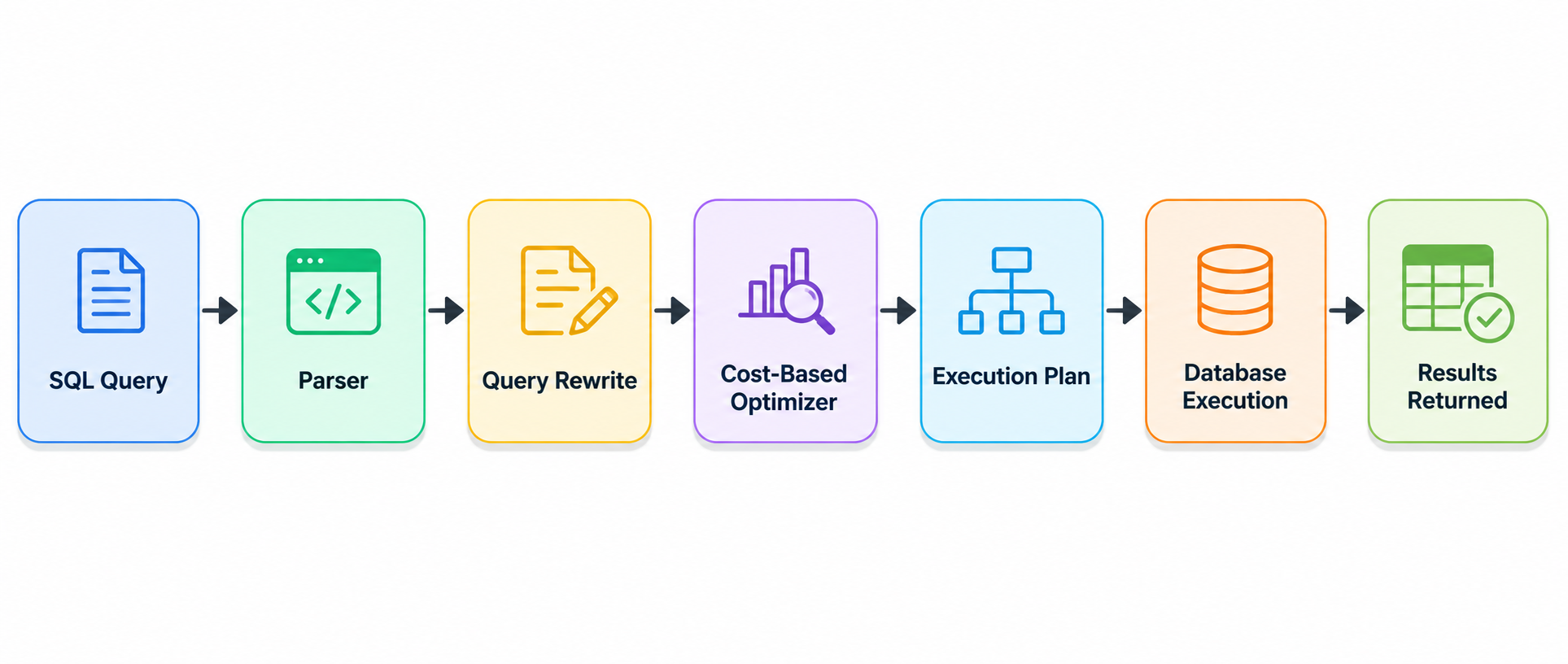
Once an execution plan is chosen, the database engine executes the operations specified in the plan. This may involve scanning tables, accessing indexes, performing joins, sorting data, and aggregating results.
The effectiveness of optimization depends heavily on accurate statistics. Database systems rely on metadata about table sizes, value distributions, and index selectivity. Outdated statistics can lead to poor execution plan choices and degraded performance.
Common Causes of Slow SQL Queries
Many database performance problems originate from common query design mistakes. Identifying these issues is often the first step toward effective optimization.
One frequent cause is full table scanning. When no suitable index exists, the database may need to examine every row in a table to locate matching records. This becomes increasingly expensive as tables grow larger.
Another common problem is retrieving unnecessary data. Queries that use SELECT * often fetch more columns than required. This increases memory consumption, network traffic, and processing overhead, especially when large datasets are involved.
Poor join conditions can also significantly impact performance. Joining large tables without appropriate indexes may force the database to perform expensive operations. Complex multi-table joins often become major bottlenecks in enterprise systems.
Subqueries and nested queries sometimes contribute to inefficiencies. While modern optimizers can improve many subqueries automatically, certain patterns may still generate expensive execution plans.
Functions applied directly to indexed columns can prevent index usage. For example, wrapping a date column in a function may force the optimizer to scan the entire table rather than use an available index.
Outdated statistics represent another major issue. If the optimizer has inaccurate information about data distribution, it may select inefficient execution strategies that increase query execution times dramatically.
Understanding SQL Execution Plans
An execution plan is a detailed roadmap that shows how a database engine intends to execute a query. Learning to read execution plans is one of the most valuable skills in SQL performance tuning.
Execution plans reveal the sequence of operations performed by the database. These operations may include index seeks, table scans, joins, sorts, aggregations, and filtering steps. By analyzing the plan, developers can identify inefficient operations and optimization opportunities.
Most database platforms provide tools for viewing execution plans. Examples include EXPLAIN in MySQL and PostgreSQL, Execution Plans in SQL Server, and EXPLAIN PLAN in Oracle.
Consider the following simple query:
SELECT customer_name
FROM customers
WHERE customer_id = 1001;
If an index exists on customer_id, the execution plan will likely show an Index Seek operation. This allows the database to locate the target row quickly without scanning the entire table.
Without an index, the execution plan may display a Table Scan operation. In this scenario, every row must be examined until the matching record is found, resulting in significantly higher execution costs.
When reviewing execution plans, pay particular attention to estimated costs, row counts, and scan operations. Large discrepancies between estimated and actual row counts often indicate inaccurate statistics or data distribution issues.
Understanding execution plans enables database professionals to move beyond guesswork and make optimization decisions based on measurable evidence.
Importance of Indexing in SQL Query Optimization
Indexing is one of the most powerful techniques for improving SQL query performance. An index is a data structure that allows the database engine to locate rows efficiently without scanning entire tables.
A useful analogy is a book index. Instead of reading every page to find a topic, readers can consult the index and navigate directly to the relevant section. Database indexes serve a similar purpose by providing fast access paths to data.
The most common index type is the B-tree index, which organizes values in a hierarchical structure. This structure enables rapid searches, insertions, and updates while maintaining balanced performance characteristics.
Indexes are particularly effective for columns frequently used in WHERE clauses, JOIN conditions, ORDER BY operations, and GROUP BY statements. Queries involving these columns often experience dramatic performance improvements after appropriate indexing.
However, indexing is not without trade-offs. Each additional index consumes storage space and increases maintenance overhead during INSERT, UPDATE, and DELETE operations. Excessive indexing can actually reduce overall system performance.
Choosing the right indexing strategy requires understanding workload patterns and query behavior. Composite indexes, covering indexes, and filtered indexes can provide substantial benefits when designed carefully.
For example:
CREATE INDEX idx_customer_email
ON customers(email);
This index allows the database to locate customer records by email much more efficiently than performing a full table scan.
SQL Query Optimization Techniques
Write Selective Queries
One of the simplest optimization techniques is retrieving only the data that is actually needed. Avoiding unnecessary columns reduces memory usage, network traffic, and processing overhead.
Instead of writing:
SELECT *
FROM orders;
Consider specifying only required columns:
SELECT order_id, order_date, total_amount
FROM orders;
This approach becomes especially valuable when tables contain dozens of columns or large text fields.
Optimize WHERE Clauses
Efficient filtering conditions help reduce the number of rows processed during query execution. Highly selective predicates allow the optimizer to leverage indexes more effectively.
Avoid applying functions directly to indexed columns whenever possible. Consider rewriting conditions to preserve index usability and improve performance.
For example:
WHERE YEAR(order_date) = 2024can often be rewritten as:
WHERE order_date >= '2024-01-01'
AND order_date < '2025-01-01'
This version is more likely to utilize an index on the date column.
Use Proper Joins
Joins are essential in relational databases, but inefficient joins can become performance bottlenecks. Ensuring that join columns are indexed often leads to significant improvements.
When joining large tables, verify that the join conditions are appropriate and that indexes support the relationship. Poorly designed joins can generate massive intermediate result sets and increase execution times dramatically.
It is also important to select the correct join type. Using INNER JOIN instead of OUTER JOIN when appropriate can reduce processing costs.
Avoid Unnecessary Subqueries
Nested subqueries sometimes force the database to perform repetitive calculations. In many cases, rewriting subqueries as joins improves readability and performance.
For example:
SELECT *
FROM employees
WHERE department_id IN
(
SELECT department_id
FROM departments
);
may perform similarly to a join, but joins often provide better optimization opportunities and clearer execution plans.
The best approach depends on the database engine and data distribution, making execution plan analysis essential.
Limit Returned Rows
Large result sets increase resource consumption and network traffic. When users only need a subset of records, limiting returned rows can significantly improve performance.
Examples include:
LIMIT 100in MySQL and PostgreSQL, or:
TOP 100in SQL Server.
Pagination strategies are particularly important for web applications displaying large datasets.
Maintain Database Statistics
Accurate statistics help the optimizer make informed decisions. As data changes over time, statistics may become outdated and reduce optimization effectiveness.
Most database platforms provide automated mechanisms for updating statistics. However, administrators should monitor critical tables and ensure statistics remain current.
Regular maintenance improves cardinality estimates and increases the likelihood of efficient execution plans.
Use Query Caching When Appropriate
Caching reduces the need to repeatedly execute identical queries. Frequently accessed data can often be served from memory rather than recalculated each time.
Many database systems support query caching mechanisms, while application-level caching solutions such as Redis provide additional performance benefits.
Effective caching strategies reduce database load and improve response times for high-traffic applications.
Partition Large Tables
Table partitioning divides large datasets into smaller logical segments. This allows queries to access only relevant partitions rather than scanning entire tables.
For example, a transaction table containing ten years of data might be partitioned by year. Queries targeting recent transactions would only access the latest partitions.
Partitioning can improve performance significantly when implemented correctly, particularly in data warehousing and analytics environments.
Monitor and Tune Continuously
SQL query optimization is not a one-time activity. As workloads evolve and data volumes increase, previously efficient queries may become problematic.
Continuous monitoring helps identify emerging bottlenecks before they affect users. Database monitoring tools can reveal slow queries, resource-intensive operations, and index usage patterns.
Organizations that treat optimization as an ongoing process are better positioned to maintain high performance over the long term.
Beyond Query Optimization: Adding Semantic Understanding to SQL Systems
Optimizing SQL queries is only one part of building an effective data platform. Indexes, execution plans, partitioning, and query tuning help organizations retrieve data efficiently, but performance alone does not solve every data challenge. Even in highly optimized SQL systems, organizations still need a way to make data easier to understand, govern, and access consistently, especially for AI-driven applications.
Most enterprise data continues to reside in SQL databases such as PostgreSQL, MySQL, SQL Server, and Oracle Database. These systems excel at performance, reliability, and transactional consistency, but their schemas often reflect how data is physically stored rather than how the business understands it. Tables, columns, foreign keys, and joins describe data structures, but they do not always communicate the underlying business meaning behind the data.
The Role of a Semantic Layer
A semantic layer sits above existing SQL databases and exposes business concepts directly, such as Customer, Order, Product, or Transaction. Instead of requiring applications or AI systems to navigate complex schemas and join paths, the semantic layer provides a higher-level model aligned with business terminology and intent.
This approach allows developers, analysts, and AI systems to work with data more naturally without changing the underlying database infrastructure. SQL optimization ensures data can be retrieved efficiently, while a semantic layer helps ensure it can be understood correctly.
Ontology and Ontology Enforcement
At the core of many semantic-layer architectures is an ontology, a formal representation of entities, relationships, and business rules across the data environment.
An ontology defines:
- What entities exist
- How entities relate to one another
- Which relationships are valid within the business domain
For example, a Customer may place an Order, an Order may contain a Product, and a Supplier may provide that product.
Ontology enforcement helps ensure that queries and updates across SQL systems respect these rules. Whether data access originates from an application, an analyst, or an AI agent, operations can be validated against the semantic model to prevent inconsistent or logically invalid relationships.
Why It Matters: From Fast Queries to Trusted AI
Traditional SQL optimization focuses on improving performance by reducing execution time, minimizing resource consumption, and increasing scalability. However, as organizations increasingly adopt AI assistants and autonomous agents, correctness becomes just as important as speed.
Large language models can often generate syntactically correct SQL queries, but they may still misunderstand the business meaning behind the data. An AI agent may successfully join tables and retrieve records while creating relationships or assumptions that do not exist in reality.
Ontology enforcement acts as a semantic guardrail. It helps ensure that AI-generated reads and writes follow a validated model of how business entities interact, reducing errors that traditional database constraints alone cannot detect.
It also enables more effective feedback mechanisms. Instead of returning only technical SQL errors, ontology-aware systems can provide semantic feedback that explains why a query or update violates business logic. This allows AI systems to refine their behavior over time and operate with greater reliability.
Data Access with AI Assistants
Moving beyond performance optimization, organizations are increasingly exploring ways to make existing SQL data more accessible to AI systems.
Graph-based semantic approaches, such as PuppyGraph, provide a way to access and query existing SQL data as connected knowledge without requiring organizations to migrate data into a native graph database. By exposing relationships explicitly, these systems enable developers and AI agents to explore enterprise data through graph-style reasoning while continuing to leverage existing SQL infrastructure.
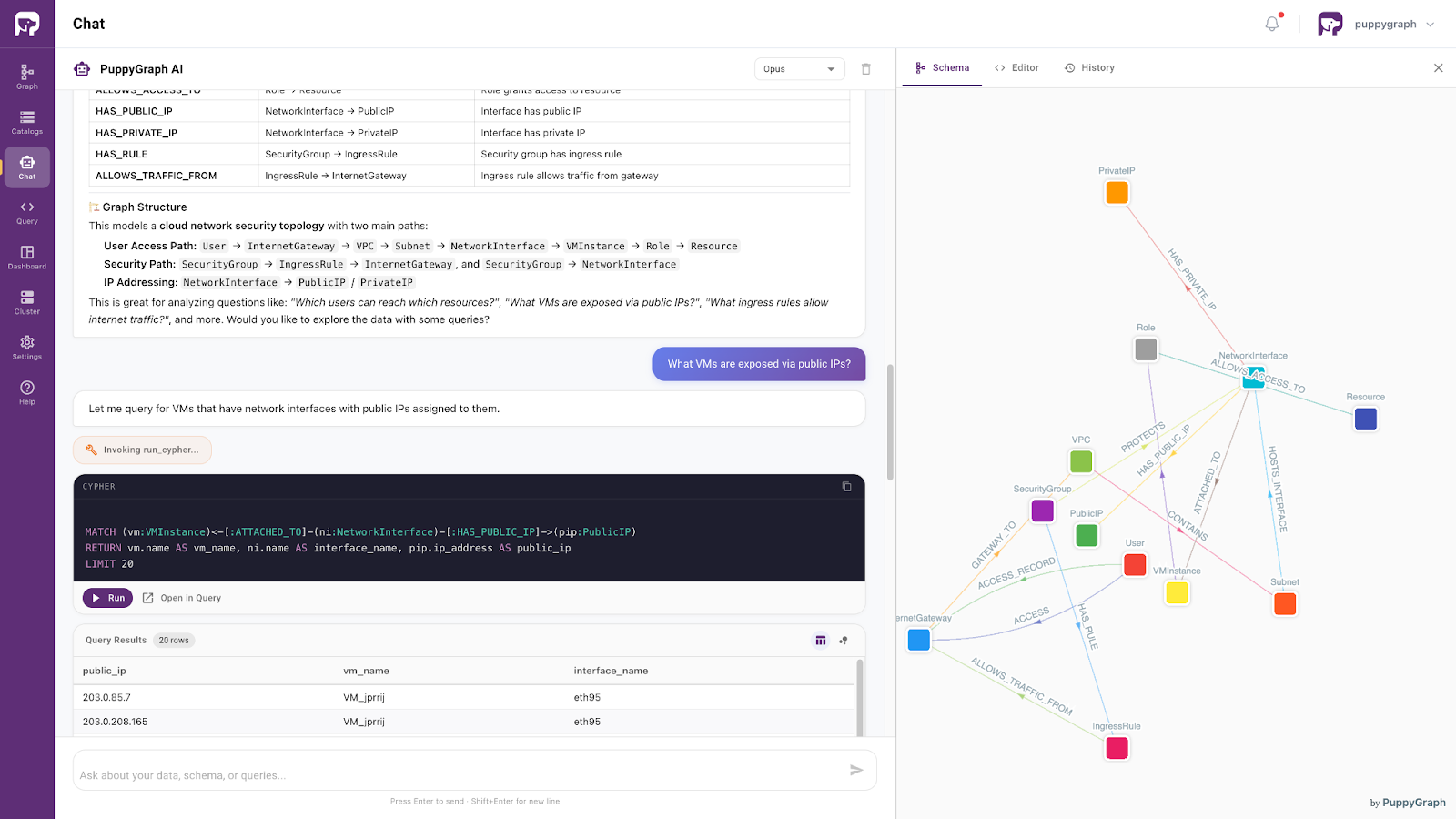
Figure: PuppyGraph AI assistant handling natural language questions
Powered by an ontology-enforced semantic foundation, this approach supports more context-aware access to enterprise data. AI systems can interpret user intent within a well-defined business framework, retrieve relevant information more accurately, and reason across relationships that may be difficult to infer directly from relational schemas.
As a result, enterprise data evolves from a collection of optimized tables into a connected knowledge layer that supports search, analytics, and next-generation AI applications while preserving the performance and reliability benefits of SQL databases.
Conclusion
In summary, SQL query optimization is essential for maintaining fast, scalable, and reliable database systems. By understanding how query optimizers work, analyzing execution plans, designing efficient queries, and implementing appropriate indexing strategies, organizations can significantly reduce response times, improve resource utilization, and support growing workloads. Continuous monitoring and maintenance further ensure that database performance remains consistent as data volumes and business demands evolve.
However, performance optimization alone is not enough in modern data environments. As AI-driven applications increasingly interact with enterprise data, organizations also need semantic understanding and governance. Semantic layers and ontology enforcement complement traditional SQL optimization by providing business context, validating relationships, and improving data accessibility. Together, efficient SQL performance and semantic intelligence enable organizations to build trustworthy, scalable, and AI-ready data platforms.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see how PuppyGraph turns optimized SQL data into AI-ready knowledge.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install