

What is Streaming Database? How Does It Work?
Modern digital systems generate data continuously rather than in isolated batches. User clicks, financial transactions, sensor readings, application logs, and machine metrics all arrive as uninterrupted streams of events. Traditional databases were designed to store and analyze static datasets, typically after data has already been collected and processed. As organizations increasingly require real-time insights and immediate responses, this batch-oriented approach becomes a bottleneck. Decisions delayed by minutes or hours can mean lost revenue, security risks, or degraded user experiences.
A streaming database addresses this challenge by treating data as something that is always in motion. Instead of waiting for data to be written, indexed, and queried later, a streaming database ingests, processes, and queries events as they arrive. This enables real-time analytics, low-latency dashboards, instant alerts, and continuous decision-making. From fraud detection to recommendation systems, streaming databases are becoming a foundational component of modern data architectures.
This article explains what a streaming database is, how it works internally, and how it differs from traditional database systems. We will explore its architecture, real-time query capabilities, benefits, and limitations, helping you understand when and why streaming databases are used in production systems today.
What is a Streaming Database?
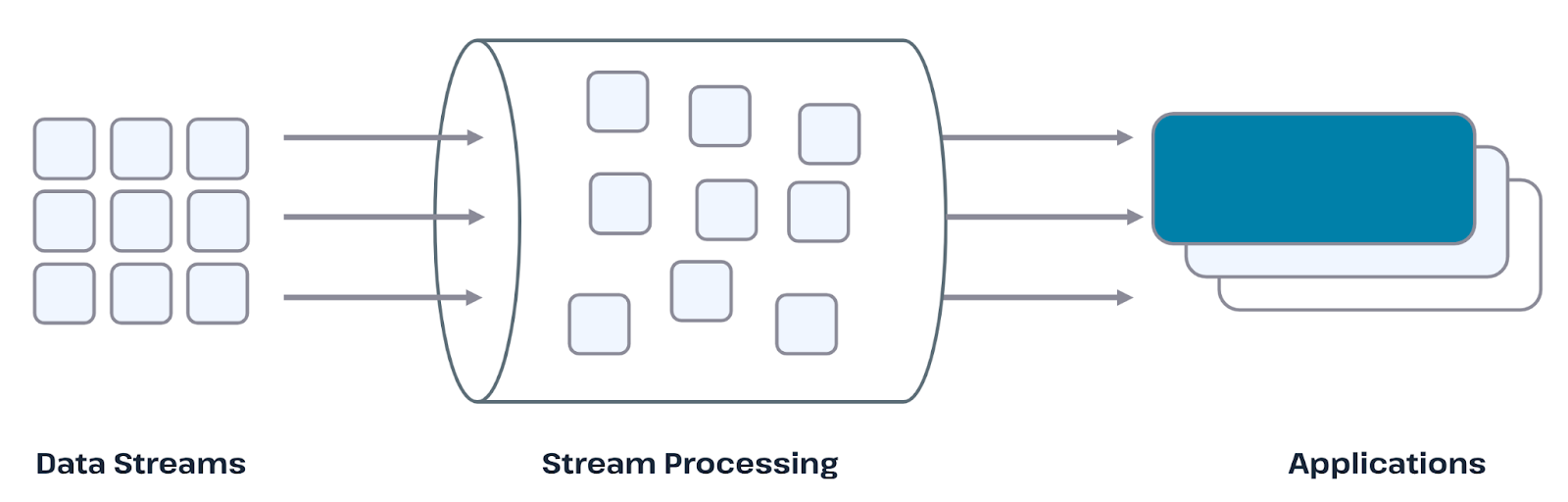
A streaming database is a database system designed to ingest, process, and query continuous streams of data in real time. Unlike traditional databases that operate on static tables populated through batch inserts or periodic updates, streaming databases treat data as an ever-growing, time-ordered sequence of events. Each event is processed as soon as it arrives, allowing queries to produce continuously updated results rather than one-time snapshots.
At its core, a streaming database combines elements of stream processing engines and database systems. It provides declarative query languages, often SQL-like, while operating on unbounded data streams instead of finite datasets. Queries are typically long-running, meaning they remain active and update their results as new data flows through the system. This allows applications to react instantly to changes in underlying data.
Streaming databases are commonly used when low latency is critical. Examples include monitoring user behavior in real time, detecting anomalies in network traffic, processing IoT sensor data, or computing live financial metrics. In these scenarios, waiting for batch processing would be impractical, making streaming databases an essential tool for real-time data-driven systems.
How Streaming Databases Work
Streaming databases operate on the principle that data is never complete. Instead of assuming a fixed dataset, they assume that new events will continue to arrive indefinitely. When data enters the system, it is immediately parsed, timestamped, and routed through a processing pipeline. Queries are registered ahead of time and continuously evaluate incoming data rather than being executed on demand against stored records.
Most streaming databases rely on event time or processing time to reason about data. Event time refers to when an event actually occurred, while processing time refers to when the system receives it. This distinction is important because real-world data often arrives late or out of order. Streaming databases incorporate mechanisms such as watermarks and windowing to handle these inconsistencies while still producing accurate results.
Instead of returning a static result set, streaming queries emit incremental updates. For example, a query calculating the average transaction value per minute will continuously update its output as new transactions arrive. These outputs can be written to downstream systems, exposed through APIs, or visualized in dashboards, enabling real-time decision-making across the organization.
Streaming Database Architecture
The architecture of a streaming database is designed to support high-throughput ingestion, low-latency processing, and continuous querying. It typically consists of several loosely coupled components that work together to ensure scalability and fault tolerance. Data enters the system through ingestion layers, flows through processing engines, and is materialized into queryable results or external sinks.
A key architectural feature is the separation between storage and computation. Many streaming databases store raw events in append-only logs while processing queries in parallel across distributed nodes. This design allows the system to scale horizontally and recover from failures without losing data. State management is another critical aspect, as streaming queries often maintain intermediate results over time.
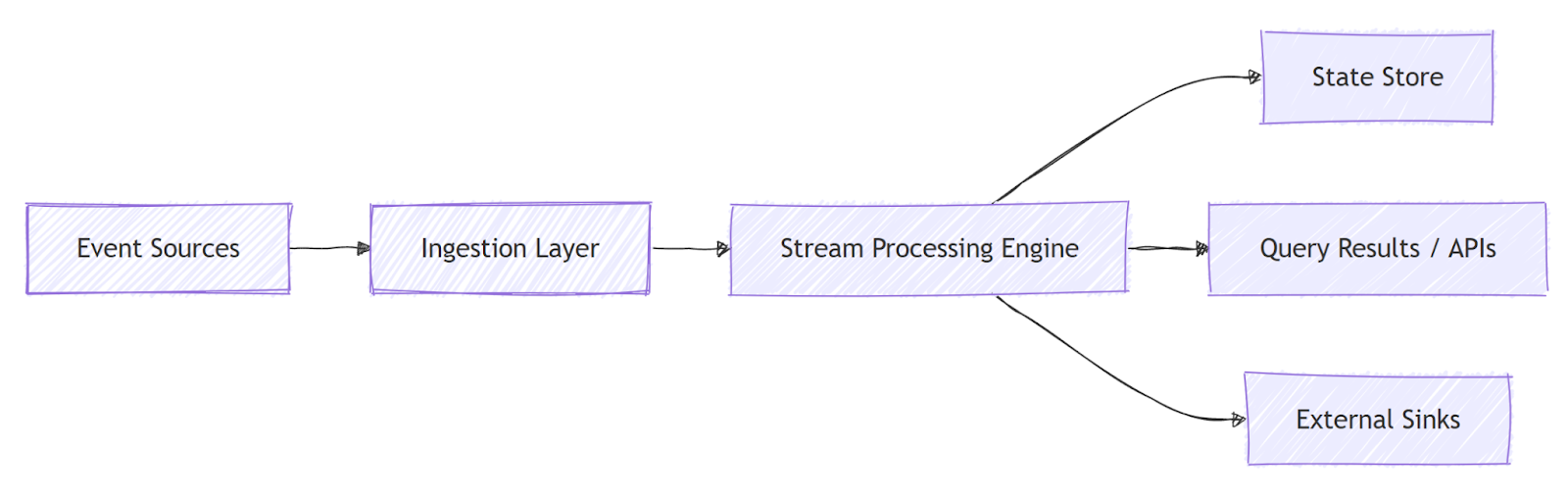
In this architecture, event sources such as applications or devices continuously send data to the ingestion layer. The processing engine executes long-running queries, maintains state, and produces outputs in real time.
Streaming Database vs Traditional Databases
Streaming databases and traditional databases are designed around fundamentally different assumptions about data. Traditional databases assume that data is mostly static once written and that queries are executed on demand. Users issue a query, the database scans stored data, and returns a fixed result set. This model works well for transactional systems and historical analytics but struggles with real-time requirements.
In contrast, streaming databases assume that data is continuously arriving and that queries should run continuously. Rather than pulling data when needed, results are pushed as new events occur. This shift changes how indexing, storage, and query execution are implemented. Streaming databases prioritize low latency and incremental computation, while traditional databases prioritize consistency and durability of stored records.
Another major difference lies in how time is handled. Traditional databases often treat time as just another column, whereas streaming databases treat time as a first-class concept. Windowing functions, event-time processing, and late data handling are built into the query engine. As a result, streaming databases are better suited for real-time analytics, while traditional databases remain essential for transactional workloads and long-term data storage.
Real-Time Querying and Processing
Real-time querying is one of the defining features of streaming databases. Queries are typically defined once and then run continuously, processing each incoming event as it arrives. This allows systems to maintain up-to-date aggregates, detect patterns, and trigger actions with minimal delay. The results are not static tables but evolving views that reflect the current state of the data stream.
To support real-time processing, streaming databases use techniques such as incremental computation and stateful operators. Instead of recalculating results from scratch, the system updates existing state based on new events. For example, a running count or sum can be updated in constant time when a new record arrives. This approach significantly reduces computation costs and latency.
Windowing is another essential concept in real-time querying. Because data streams are unbounded, queries often operate on finite windows of time, such as the last five minutes or the current hour. Streaming databases provide flexible windowing semantics that allow developers to define how data is grouped and aggregated over time, enabling precise and timely insights.
Key Benefits of Streaming Databases
Streaming databases provide several advantages for organizations that need immediate insights from continuously generated data. The most significant benefit is low-latency processing, which enables systems to react to events in real time. This capability is essential for applications where delays can lead to missed opportunities or increased risk.
Another important benefit is scalability. Streaming databases are typically built on distributed architectures that can handle high volumes of data by scaling horizontally. As data rates increase, additional processing nodes can be added without redesigning the system. This makes streaming databases suitable for large-scale deployments across industries.
Streaming databases also simplify real-time analytics by providing declarative query languages. Developers can express complex logic using familiar SQL-like syntax instead of writing custom event-processing code. This reduces development effort and makes real-time data processing more accessible to data engineers and analysts, bridging the gap between streaming systems and traditional databases.
Challenges of Streaming Databases
Despite their advantages, streaming databases introduce several challenges that organizations must consider. One of the most significant challenges is complexity. Designing and operating a streaming database requires careful handling of time semantics, state management, and fault tolerance. Late or out-of-order data can complicate query logic and lead to unexpected results if not handled correctly.
Another challenge is consistency and correctness. Because streaming databases process data continuously, ensuring exactly-once or even at-least-once processing semantics can be difficult. Failures, network partitions, and retries must be managed carefully to avoid data loss or duplication. These concerns often require additional infrastructure and operational expertise.
Finally, streaming databases are not a replacement for all data systems. They are optimized for real-time workloads but may not be ideal for complex transactional operations or long-term archival storage. As a result, organizations often need to integrate streaming databases with traditional databases and data lakes, adding architectural complexity to the overall system.
Realtime Graph Analytics with PuppyGraph
Streaming databases excel at capturing and processing events as they happen, but understanding relationships across entities in real time often requires additional analysis. PuppyGraph complements streaming systems by enabling graph queries directly on live, continuously updated data, allowing organizations to perform deep, multi-entity analytics without waiting for batch processing or materialized graphs.
By integrating with streaming pipelines, PuppyGraph continuously ingests the latest events from streaming databases and updates the graph on the fly. This allows teams to detect patterns, trace connections, and answer complex “multi-hop” questions as data arrives, turning a stream of discrete events into actionable insights about how entities relate to each other in real time.
In practice, this combination enables use cases such as:
- Fraud and security detection: Instantly identify suspicious activity by analyzing relationships across accounts, devices, and transactions.
- Operational intelligence: Monitor systems and workflows dynamically, revealing hidden dependencies or bottlenecks as events occur.
- Cybersecurity and threat investigation: Track lateral movement, uncover coordinated attacks, and correlate alerts across users, hosts, and network activity in real time.
Together, streaming databases handle event flow and time-sensitive computations, while PuppyGraph adds real-time graph analytics, forming a complementary architecture that turns continuous data streams into actionable, connected insights at scale.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Streaming databases have emerged as a critical foundation for modern data architectures, enabling organizations to process and analyze continuously generated events with minimal latency. By treating data as an ongoing stream rather than a static dataset, they support real-time dashboards, alerts, and automated decisions that traditional batch systems struggle to deliver. Their architecture, built around continuous queries, event-time processing, and distributed scalability, allows teams to extract timely insights from fast-moving data.
However, streaming databases are only part of the picture when deeper relationship analysis is required. Combining streaming systems with PuppyGraph enables organizations to move beyond isolated events and understand how entities connect and evolve over time. Together, they create a powerful architecture that transforms continuous data flows into actionable, context-rich intelligence for security, operations, and advanced analytics.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install