

What is Text to Cypher?

With the rise of large language models (LLMs), interacting with graph databases has become far more accessible. Traditionally, writing Cypher queries or understanding pattern-matching constructs required specialized expertise, limiting who could explore graph data. Text to Cypher removes this barrier by translating natural-language questions into executable Cypher, allowing users to query connected data without writing code.
Modern graph engines now ship with LLM-powered Text to Cypher as a built-in capability, using prompt engineering, schema grounding, and structured output formats to guide large language models toward generating safe, accurate Cypher. Instead of relying on handcrafted rules or classical NLP pipelines, the system provides the model with schema context, behavioral constraints, and examples so it can reason about user intent and produce valid queries deterministically. A full Text to Cypher pipeline combines schema ingestion, controlled prompting, semantic framing, and automated validation, ensuring that the generated Cypher is both executable and aligned with the underlying graph structure.
What is Text to Cypher
Text to Cypher is an auxiliary tool of graph query clients. Instead of writing complex pattern-matching statements, users can describe their questions in plain English, such as “Which customers purchased product X this quarter?” The system then generates the precise Cypher query needed to retrieve the relevant results.
At its core, Text to Cypher combines three key capabilities: understanding natural-language intent, grounding that intent in the database schema, and generating syntactically correct, safe, and efficient Cypher.
As a built-in helper feature of graph databases, Text to Cypher enhances usability by expanding access to connected-data insights. It allows domain experts, who may not be familiar with query syntax, to explore relationships, perform aggregations, and search paths across the graph efficiently. By bridging the gap between human intuition and formal query construction, Text to Cypher transforms how users interact with graph data.
How Text to Cypher works
The Modern Text to Cypher pipeline leverages LLMs as a black-box engine to transform natural-language questions into safe, executable Cypher queries. Every stage of the pipeline is designed to guide the model with structured context, prompt templates, and controlled output formats, ensuring accuracy, consistency, and reliability. Rather than relying on traditional NLP techniques, the pipeline focuses on engineering effective prompts, providing schema grounding, and defining strict response formats that can be parsed and validated automatically.
1. Schema ingestion and context preparation
Before any query generation, the system ingests the graph’s schema, including node labels, relationship types, property names, and representative sample values. This information is formatted into structured context, often as JSON or embedded in a prompt template, that the LLM can reference during generation. By including enumerations (e.g., product SKUs, country names) or sample data, the model is guided to use correct labels, relationships, and properties. Schema context can be dynamically fetched from the database or provided as a maintained snapshot, and it is always presented in a machine-readable format to ensure the LLM can interpret it reliably.
2. Prompt engineering and natural-language intake
The user’s question is injected into a carefully designed prompt template, which combines several elements:
- The user query in natural language.
- The structured schema context.
- Instructions on output formatting and constraints.
- Optional examples of input questions and corresponding Cypher queries.
This prompt template is the primary lever for controlling the LLM’s behavior. It ensures that the generated query aligns with schema definitions, adheres to Cypher syntax, and produces results in a predictable format.
3. Semantic framing via LLM
The LLM interprets the user query within the context provided by the prompt. Rather than exposing internal NLP processes, the system treats the model’s output as a structured semantic frame: a JSON object or another machine-readable format containing the intended query structure, target entities, filters, and aggregations. By defining the expected output format in the prompt, such as a JSON schema with specific fields for MATCH patterns, WHERE clauses, and RETURN projections, the system guarantees that the generated response can be parsed and converted into executable Cypher reliably.
4. Cypher generation and schema alignment
Using the semantic frame produced by the LLM, the system generates the final Cypher query. The prompt template may include example queries to demonstrate correct syntax and handle graph-specific constructs, such as variable-length paths, relationship direction, and aggregation. All property names, node labels, and relationship types are verified against the schema context. The LLM output itself can be directly parsed as structured JSON, from which the executable Cypher is assembled, ensuring that the resulting query is both syntactically correct and semantically aligned with the database schema.
5. Validation, execution, and structured feedback
After the LLM generates a Cypher query, the Text to Cypher system performs external validation before execution. This includes deterministic checks such as syntax parsing, schema matching, cost estimation (e.g., via EXPLAIN), and enforcing safety rules like read-only mode, timeouts, and automatic LIMIT injection.
Only validated queries are executed. Results are returned in a structured format, commonly JSON, so downstream applications can process or log them reliably. If the query is invalid or leads to errors, the system feeds the failed query, error message, or diagnostics back to the LLM for regeneration. This closed-loop design ensures safety, transparency, and repeatability while keeping the LLM as a stateless generator instead of an execution engine.
The Role of Natural Language Processing (NLP) in Text to Cypher
In modern Text to Cypher systems, LLMs serve as the central engine, handling both understanding and generation in a unified, black-box fashion. Instead of relying on separate rule-based NLP components, the system leverages LLMs through carefully engineered prompts, structured context, and controlled output formats to reliably translate natural-language questions into executable Cypher queries.
Prompt engineering as control mechanism.
The user’s natural-language input is framed within a prompt template that provides schema context, behavioral instructions, and output constraints. Prompts include details such as node labels, relationship types, property names, and representative sample values, along with a clear specification of the desired output format. Few-shot examples of nature language to Cypher mappings can be included to guide the model, reinforcing correct patterns for MATCH clauses, aggregations, and filtering. Through prompt engineering, the system directs the LLM to interpret intent, resolve ambiguities, and adhere to the database schema without needing explicit parsing rules.
Structured output formatting.
To guarantee reliability and ease of post-processing, LLMs are instructed to return results in machine-readable structures, typically JSON objects or predefined semantic frames. These outputs explicitly encode MATCH patterns, WHERE filters, RETURN projections, and any aggregations. By constraining the model to produce structured representations rather than free-form text, the system ensures that generated queries can be automatically parsed, validated, and converted into executable Cypher.
Iterative refinement and feedback loops.
LLM outputs undergo validation against schema context and execution constraints. If a query is incomplete, syntactically invalid, or references unknown entities, the system can feed the structured output back into the model for regeneration, optionally adding clarifying context or additional instructions. This closed-loop design allows the LLM to iteratively refine its output, producing accurate, safe, and schema-aligned queries without human intervention.
Black-box semantic reasoning.
By treating the LLM as a black-box reasoning engine, the system benefits from the model’s deep contextual understanding, handling underspecified or ambiguous queries flexibly. The LLM infers user intent, maps it onto the schema, and generates executable Cypher in a single step, all while adhering to prompt-specified constraints. This approach removes the need for traditional NLP components and unifies query comprehension and generation under one adaptable, high-coverage mechanism.
Benefits of Converting Text to Cypher Queries
Adopting Text to Cypher unlocks several high-impact outcomes for organizations seeking to leverage graph data.
- Accessibility and democratization of graph data.
Many business stakeholders understand relationships and insights but cannot write Cypher. Text to Cypher removes the syntax barrier, so analysts, product managers, and domain experts can query complex graphs directly. This democratizes analysis, reduces bottlenecks on specialized teams, and speeds decision loops by putting query power into the hands of those who best understand the business questions. - Faster exploration and iterative insight generation.
Building and refining Cypher queries manually often requires schema familiarity and iterations. Natural-language querying shortens that loop: users can ask successive questions in conversational form, obtaining immediate results and refining queries dynamically. The faster iteration accelerates hypothesis testing, dashboard creation, and exploratory data analysis. - Improved developer productivity.
Developers and data engineers benefit when Text to Cypher handles routine query scaffolding. Instead of writing boilerplate traversal logic, they can focus on performance optimization, integrating results into applications, and designing robust graph schemas. Generated queries serve as a starting point that can be inspected and refined for production use. - Broadening use cases and embedding into conversational workflows.
Text to Cypher integrates naturally with chatbots, BI tools, and dashboards that accept natural language. This enables conversational analytics, automated reports, and embedded assistants that surface network patterns without requiring users to learn query languages. Such integration multiplies the value of existing graph investments.
Example of Text to Cypher Query Transformations
Text to Cypher relies heavily on prompt engineering to ensure that natural-language inputs are converted into safe, accurate, and schema-aligned graph queries. In graph query clients, such as G.V(), these capabilities are already embedded internally.
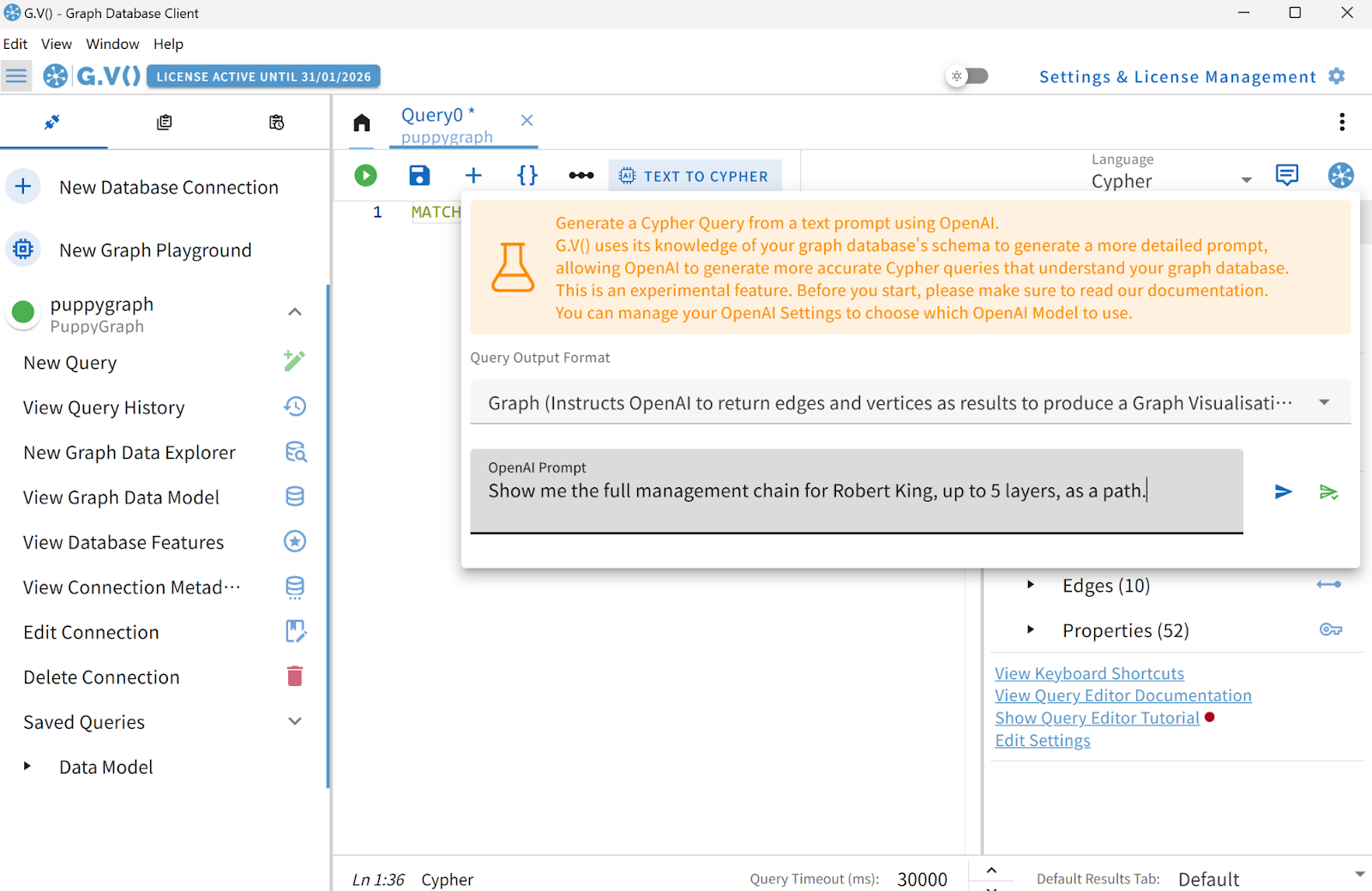
Let’s take G.V() as an example. It comes with built-in prompt templates as well as automatically extracted schema information from the graph. Users simply provide a natural-language query, which is then sent to the LLM (with an OpenAI API key) for processing.
The LLM interprets the prompt, generates the corresponding Cypher query. Finally, the user could decide whether to execute the query. No manual prompt crafting is required.
For the purpose of demo, we use G.V() and the Northwind dataset to illustrate the process.
We assume the environment is already configured appropriately, then a natural-language question can be passed to the backend directly:
“Show me the full management chain for Robert King, up to 5 layers, as a path.”
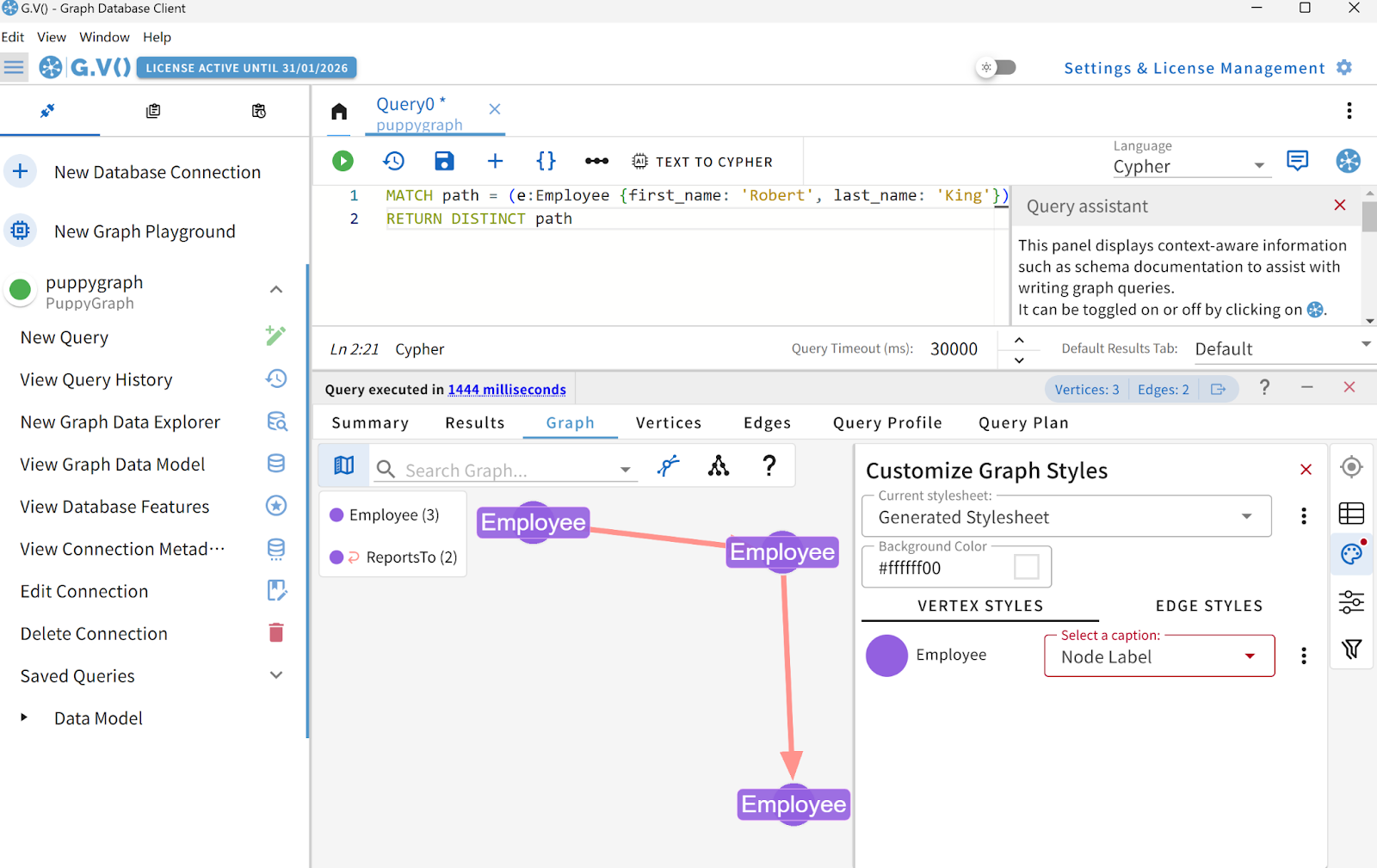
The backend then emits the final query under the enforced “Cypher-only” output rule, ensuring that the result is a clean, deterministic, and immediately executable Cypher query:
MATCH path = (e:Employee {first_name: 'Robert', last_name: 'King'})-[:ReportsTo*..5]->(manager:Employee)
RETURN DISTINCT pathRun this query against the Northwind graph, the produced result is as follows:
Challenges in Automating Text to Cypher Translation
Implementing Text to Cypher at scale requires addressing several hard problems that influence accuracy, safety, usability, and performance.
- Ambiguity in user language.
Natural language is often vague: “customers in the US” could refer to billing, shipping, or residence. Systems must either ask clarifying questions, adopt consistent defaults, or communicate assumptions explicitly. Failure to handle ambiguity leads to misleading results and loss of user trust. - Lack of Iterative Clarification & Missing Explanations
Most Text to Cypher systems operate in a single-turn mode: the user provides one natural-language request, and the system returns one Cypher query.
This creates two limitations:
- No multi-turn correction: Users cannot refine or clarify their question through back-and-forth interaction, increasing the risk of incorrect intent interpretation.
- Query-only output lacks transparency: If the system returns only the Cypher query, users receive no intuitive explanation of why the system chose a particular traversal, assumptions, or filters.
These gaps reduce usability and make errors harder to diagnose.
- Security and Information Leakage Risks
Automatically executing generated queries against production data carries risks: long-running scans, unauthorized data access, or accidental writes.
When external LLMs are involved, an additional threat emerges:
Text-to-Cypher systems typically send schema information, example queries, and sometimes user prompts to the model. This creates a potential information-leakage vector if the external model provider, logs, or infrastructure are not fully controlled.
Mitigations include read-only enforcement, rate limits, timeouts, query cost caps, schema redaction, and strict data-sharing controls. - Query Correctness Versus Performance
A syntactically correct query can still be semantically wrong or terribly inefficient. Generated queries might omit necessary indexes or produce expensive cartesian products. Balancing correctness with performance requires validation, heuristics, and sometimes automated rewriting or cost-aware generation. - Data sparsity for training and fine-tuning.
Compared to tables and SQL, nature language to Cypher datasets are smaller and more heterogeneous. Limited training data hampers model generalization across schemas and domains. Combining curated nature language to Cypher pairs with prompt engineering, synthetic data generation, and human-in-the-loop correction helps mitigate this issue.
Best Practices for Building a Text to Cypher System
When designing or integrating Text to Cypher pipeline, follow these five practical guidelines to improve reliability and user experience.
- Always provide schema and sample values to the translator.
Feed node labels, relationship types, property names, and representative values into the model prompt or mapping layer. Schema context drastically reduces misnaming and improves the model’s ability to produce executable queries. Where possible, keep schema caches fresh and refresh them on schema-change events. - Use few-shot examples and explicit instruction in prompts.
When relying on LLMs, include high-quality nature language to Cypher examples and explicit rules (e.g., “return only read-only Cypher”, “use date() for relative time windows”). Well-crafted prompts and a small curated training set reduce hallucinations and align output with expected structure. - Design UX for transparency and correction.
Show users the generated Cypher alongside results, and allow editing. When ambiguity is detected, prompt users with short clarifying questions rather than guessing. Editable queries empower analysts to refine logic and foster trust in the system’s outputs. - Safeguard production systems and monitor usage.
Enforce read-only defaults, limit result sets, and apply timeouts and resource caps. Monitor acceptance rates, error frequency, and user edits to identify systematic failures. Use telemetry to retrain models, expand synonym maps, and refine prompts based on real usage patterns. - Protect against information leakage when using external LLMs.
If the Text to Cypher pipeline relies on third-party or cloud-hosted language models, be aware that schema, example queries, and even sensitive business logic may be transmitted outside your infrastructure. Apply strict data-sharing policies, redact nonessential details, isolate production schemas from external prompts, and prefer self-hosted or on-prem LLMs when handling confidential datasets.
PuppyGraph with Chatbot
As Text-to-Cypher becomes a standard interaction layer for graph systems, the next step is making this capability feel conversational, immediate, and usable directly on operational data. PuppyGraph takes this further with its Chatbot, which lets users interact with their graph using natural language, no Cypher expertise required.
Users simply send questions to the chatbot in plain language. The bot then generates the corresponding Cypher query, executes it on live relational or lakehouse data (zero ETL), returns the results, and summarizes them in natural language. For full transparency, the exact generated query and execution details are also available in the UI and can be inspected with one click. The upcoming sections include a complete demo of this experience.
What is PuppyGraph

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Text to Cypher Demo: Using PuppyGraph’s Chatbot
PuppyGraph includes a native Text-to-Cypher assistant that translates natural-language requests into executable Cypher and runs them directly inside the chatbot. All necessary capabilities, such as schema-aware prompts, strict output constraints, and encoded graph-structural rules, are already embedded inside the system prompt. Users can issue requests in plain English, and the chatbot will reliably generate safe, accurate, and schema-aligned Cypher without requiring manual prompt engineering.
This demo uses the Northwind sample graph to illustrate the end-to-end workflow. You can find all materials in the github repository.
Inside the PuppyGraph chatbot console, the user simply types a question such as:
“Show me the full management chain for Robert King, up to 5 layers, as a path.”
Then click on ‘Send’, the UI appears as:

PuppyGraph Chatbot first shows the query results, so the user immediately sees the answer without needing to inspect the underlying Cypher.
A small button before “Click to view detailed processing steps” allows the user to reveal the generated Cypher afterward.

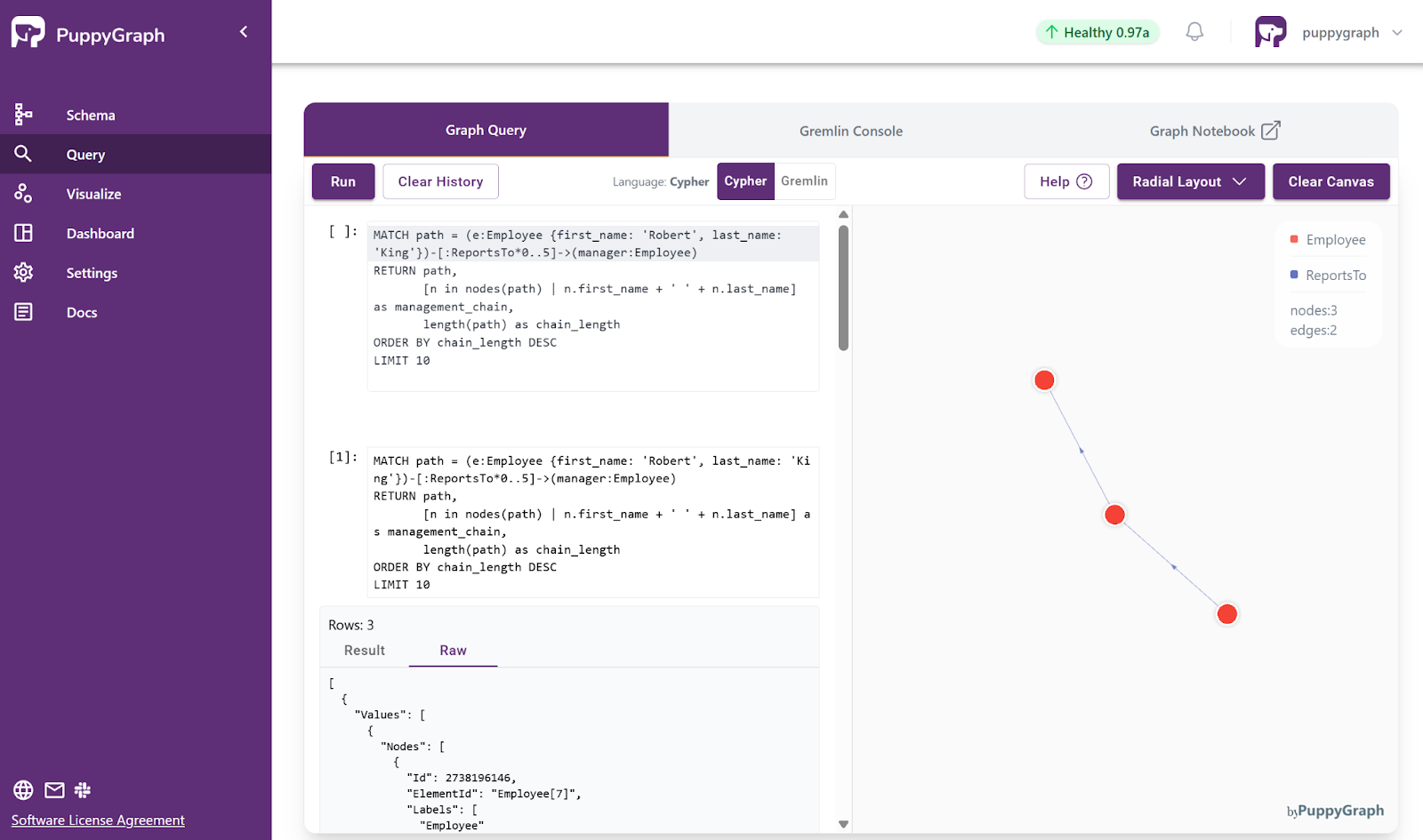
As shown in the figure, the generated Cypher query here is:
MATCH path = (e:Employee {first_name: 'Robert', last_name: 'King'})-[:ReportsTo*0..5]->(manager:Employee)
RETURN path,
[n in nodes(path) | n.first_name + ' ' + n.last_name] as management_chain,
length(path) as chain_length
ORDER BY chain_length DESC
LIMIT 10Although the query is executed inside the chatbot automatically, it can also be visualized directly in the PuppyGraph UI. Users may copy the query to the PuppyGraph UI and run it to see the corresponding management chain in PuppyGraph’s standard graph visualization panel.
Conclusion
Text to Cypher significantly lowers the barrier to graph analytics by transforming natural-language questions into executable Cypher, removing the need for query syntax expertise and accelerating exploratory data analysis. With robust schema grounding, well-designed prompts, and strict output formats, it delivers a reliable and intuitive interface for uncovering complex relationships.
PuppyGraph builds on this foundation by executing Text to Cypher directly on live relational and lakehouse data with zero ETL. Analysts gain real-time, schema-aware Cypher queries on current production data, achieving faster insights while avoiding the cost and complexity of a separate graph database.
If you’d like to explore this capability, try the forever free PuppyGraph Developer Edition or book a demo today to talk with our graph experts about your use case.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install