

Vector Database vs Graph Database: Key Differences
There are a lot of database options out there, and the list seems to continue to grow. Choosing the right database is a critical choice when it comes to managing data and building scalable and powerful applications. While traditional relational databases, which primarily handle structured data, have long been the standard, specialized database technologies are emerging to handle vast amounts of both structured and unstructured data and complex queries. Among these new types of databases are graph and vector databases, both highly specialized and designed for specific tasks. Although there is some potential overlap in use cases, such as the fact that both are frequently used in AI applications for RAG (retrieval augmented generation) capabilities, they are fundamentally different in their approach.
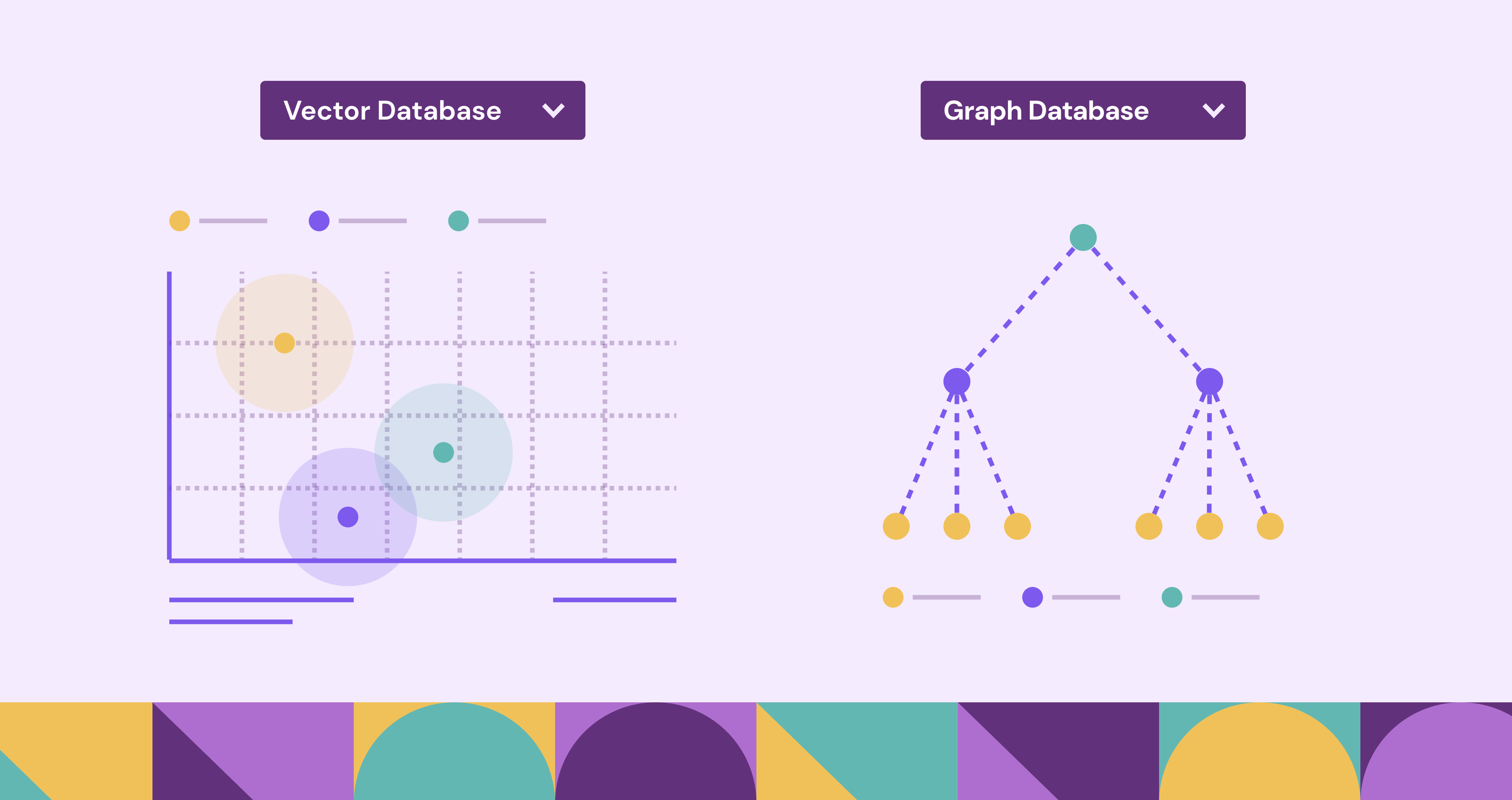
Vector databases excel at finding similarities within large datasets. They do this based on underlying meaning or characteristics, often powered by machine learning embeddings that are stored in the database. Graph databases, on the other hand, are built to map and query intricate relationships between data points. No machine learning embedding is required to understand the relationships within a graph database. Understanding the core differences between these two database types is essential for developers and data scientists looking to leverage either tool for their use case, whether it's powering semantic search, building recommendation engines, analyzing social networks, or detecting sophisticated fraud patterns. Let's begin by looking a bit deeper at each individual type of database and comparing how each works.
What is a vector database?
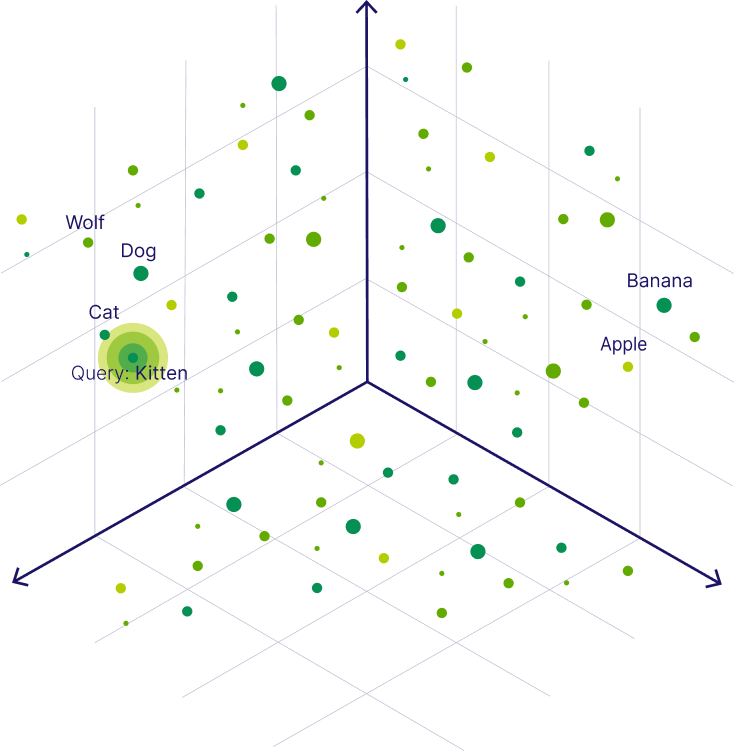
A vector database is a specialized database designed to store, manage, and search high-dimensional vector embeddings efficiently. The vectors stored within the database are mathematical representations of data (like text, images, audio, or other complex types) generated by machine learning models. Depending on the model used to create the embedding, the resulting value will be different. The key idea is that similar items will have vectors that are close to each other in a multi-dimensional space.

Instead of querying based on exact matches or predefined fields like in traditional databases, vector databases use various search algorithms, such as Approximate Nearest Neighbor (ANN) to find relevant search results. These algorithms allow for incredibly fast searches to find the vectors (and thus the original data items) that are most similar to a given query vector, even across millions or billions of entries. This makes them ideal for applications driven by similarity and meaning, such as semantic search, image recognition, recommendation systems, and anomaly detection.
What is a graph database?
On the other hand, a graph database is a similar type of NoSQL database that uses graph structures for storing data, focusing on the relationships between entities. This means that data itself is stored in the graph database and can be searched based on fields and properties, not based on comparison to another vector embedding. It leverages graph theory principles, representing data as nodes (entities, like people or products) and edges (relationships or connections between nodes, like 'friend of' or 'purchased').

Unlike relational databases that store relationships implicitly through foreign keys and require complex JOIN operations to query connections, graph databases store relationships as first-class citizens directly alongside the nodes. This structure makes traversing and querying complex relationships incredibly efficient and easier to do than with traditional SQL queries. Graph databases excel at exploring connections, finding paths, identifying communities, and understanding network structures. Although not as publicized as traditional SQL and NoSQL platforms, graph databases power a lot of common use cases, including social networks, fraud detection (tracking connections between accounts), knowledge graphs, network and IT operations, and supply chain management.
Vector database vs graph database : how are they different from each other?
While both are non-relational databases designed for specific data challenges, vector and graph databases differ fundamentally in their core purpose, data structure, and query mechanisms:
Core concept
The core concepts between the two platforms differ significantly. For vector databases, these platforms primarily focus on similarity and semantic meaning. Working well to uncover answers to questions like "What items are most similar to this one?" since the underlying features are captured in vectors. Graph databases are more focused on relationships and connections. They can help to easily answer questions like "How are these two items connected?" or "What patterns exist within this network?".
Data structure
One of the largest differences is in how both types of databases store data. A vector database stores data as high-dimensional vectors (arrays of numbers) in a vector space. With a graph database, data is stored as nodes (entities) and edges (relationships connecting nodes). Because of how data is stored, it also differentiates in what queries can be performed.
Primary operation
With vector databases, the primary operation is to perform similarity searches using algorithms like Approximate Nearest Neighbor (ANN). This executes a query to find vectors close to the query vector. A graph database primarily performs graph traversals to explore paths and connections between nodes, allowing users to explore relationships within the data as a query result or graph visualization.
Use cases
Vector databases are almost exclusively used with data generated by Machine Learning models (embeddings) for tasks requiring an understanding of similarity between different points of data. The use cases for graph databases are used for exploring data where the explicit connections and network structure are the most critical aspect.
Querying
Lastly, vector database queries involve finding vectors "nearest" to a given query vector based on distance metrics (e.g., cosine similarity, Euclidean distance). Again, depending on what embedding model is used, different results may be returned. With a graph database, queries involve traversing edges between nodes using specific graph query languages (like Cypher, Gremlin, SPARQL) to find patterns, paths, or related nodes. Graph visualization tools are also frequently used to explore data without explicitly querying it, giving even non-technical members a way to traverse data.
Vector database vs graph database: Side-by-side Comparison
Let's take a brief look at the points above, broken down into a table for a side-by-side comparison:
Although both platforms are often thought of interchangeably, it's easy to see scenarios where each would excel and falter. Graph database capabilities tend to be more broadly known, though, due to the fact that they have been in existence longer than their vector database relatives. Let's dig a bit further into the history of both types of databases next.
A brief history: vector databases and graph databases
The theoretical roots of graph databases go back to graph theory, a branch of mathematics that’s been around for centuries. But as practical database systems, they started to emerge in the early 2000s. The rise of the internet and social media created massive networks of interconnected data that were hard and inefficient to model and query with traditional relational databases. Companies like Neo4j (founded in 2007) were the first to commercialize the graph database market, offering solutions to manage and query these complex relationships. Adoption grew as the value of connections in data became more apparent across industries. The volume of data and interconnectivity between all of it set graph databases up for a spike in adoption that has continued to grow even through recent years.
Vector databases are a much more recent phenomenon, gaining traction in the late 2010s and early 2020s, expedited with the rise of AI and widespread adoption of LLMs (Large Language Models). While the underlying math (vector spaces, distance metrics) is well established, the need for dedicated databases to handle vectors surged with the advancements in deep learning and representation learning. Modern AI models have become good at generating meaningful vector embeddings for complex data like text and images. This led to a need for storing and searching these embeddings at scale, requiring new database architectures, hence the emergence of specialized vector databases like SingleStore, Pinecone, Weaviate, Milvus, and Chroma. Their history is tied to the ongoing AI revolution, with funding and adoption of these platforms growing rapidly.
Vector database vs graph database : Which is best ?
Whenever two types of technologies, especially databases, are put together, it's natural to ask which is better. But as with most cases, neither database type is inherently "better" than the other, and as we covered above, both are designed for different purposes and excel at different tasks. The best choice depends entirely on the use case and the nature of the data you're working with. With that in mind, let's look at how to determine which is the best fit for a particular need.
Choose a vector database if:
- Your primary goal is to find similar items based on complex features or semantic meaning (e.g., "find products similar to this one," "find articles related to this topic").
- You are working heavily with embeddings generated by machine learning models (text, image, audio).
- You need to power applications that require semantic search, recommendation systems based on item similarity, or image/audio retrieval.
- Performance hinges on quickly finding the "nearest neighbors" in a high-dimensional space.
Choose a graph database if:
- Your primary goal is to understand, analyze, and query the relationships between data points (e.g., "find friends of friends," "detect fraudulent transaction rings," "map dependencies in a network").
- The connections and network structure of your data is critical to queries/questions.
- You need to perform complex traversals, pathfinding, or community detection.
- Your application involves social networks, knowledge graphs, fraud detection, or supply chain analysis, where relationships are key.
In some complex scenarios, it's even possible to use both types together. For instance, you might use a vector database to find potentially related users based on their embedding similarity and then use a graph database to explore their explicit connections within a social network. In most cases, organizations still may use both types of databases, but without directly having them interact with each other, instead using the technology that best suits the particular use case.
Graph the easy way with PuppyGraph
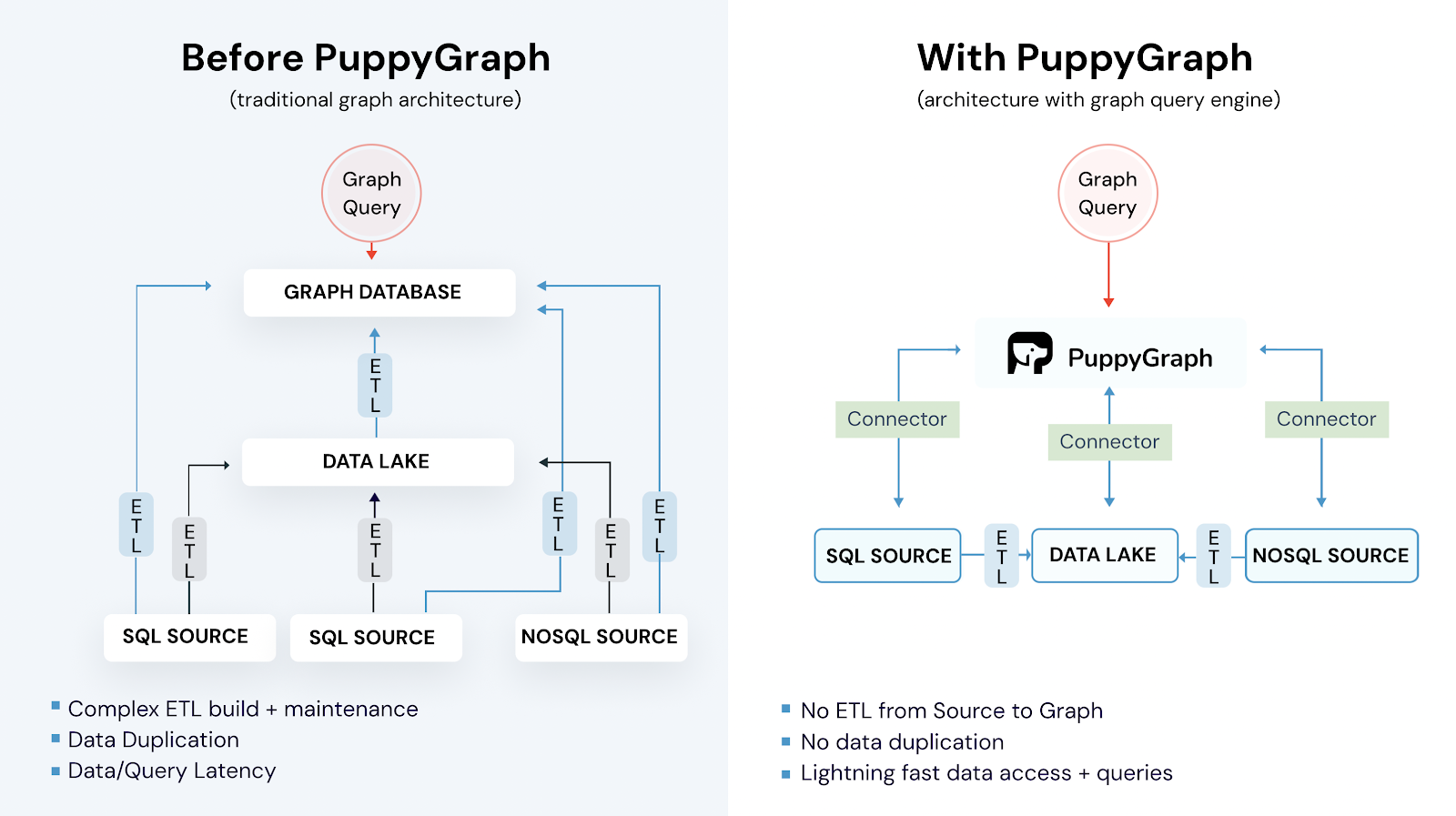
PuppyGraph PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles. It offers a unique advantage by enabling graph queries directly on existing relational databases and data lakes. Unlike traditional graph databases, it eliminates the need for ETL processes. Organizations can start querying their existing data from multiple sources as a unified graph in no more than 10 minutes, without any data migration whatsoever.
PuppyGraph not only reduces setup time and complexity but also preserves the integrity of your existing relational data infrastructure. You can query the same data using both SQL and graph query languages like Cypher and Gremlin at the same time.

PuppyGraph seamlessly integrates with major relational databases like PostgreSQL and MySQL. It also supports data lakes like Apache Iceberg and Delta Lake. PuppyGraph’s native graph analytic engine gives you sub-second query execution. Its high-performance capabilities remain consistent, which helps users achieve petabyte-level scalability in their data systems without costly infrastructure changes.

PuppyGraph’s flexible data model accommodates various data relationships. It gives you a range of both automated and manual graph modeling tools that can efficiently translate SQL data into a graph representation. Additionally, PuppyGraph automatically proposes optimal mapping strategies for data points. You get the best user experience with guided support and automation in model development.
PuppyGraph also gives you a centralized hub for graph data visualization. With its wide array of data sources support, it doesn’t matter where and how your data resides—plain text, databases, or data warehouses. You don’t have to go through the hassle of hopping between tools to visualize and analyze data for different data sources. All data converges into a single graph that becomes the single source of truth for your visualization and analytics processes through PuppyGraph’s user-friendly platform.
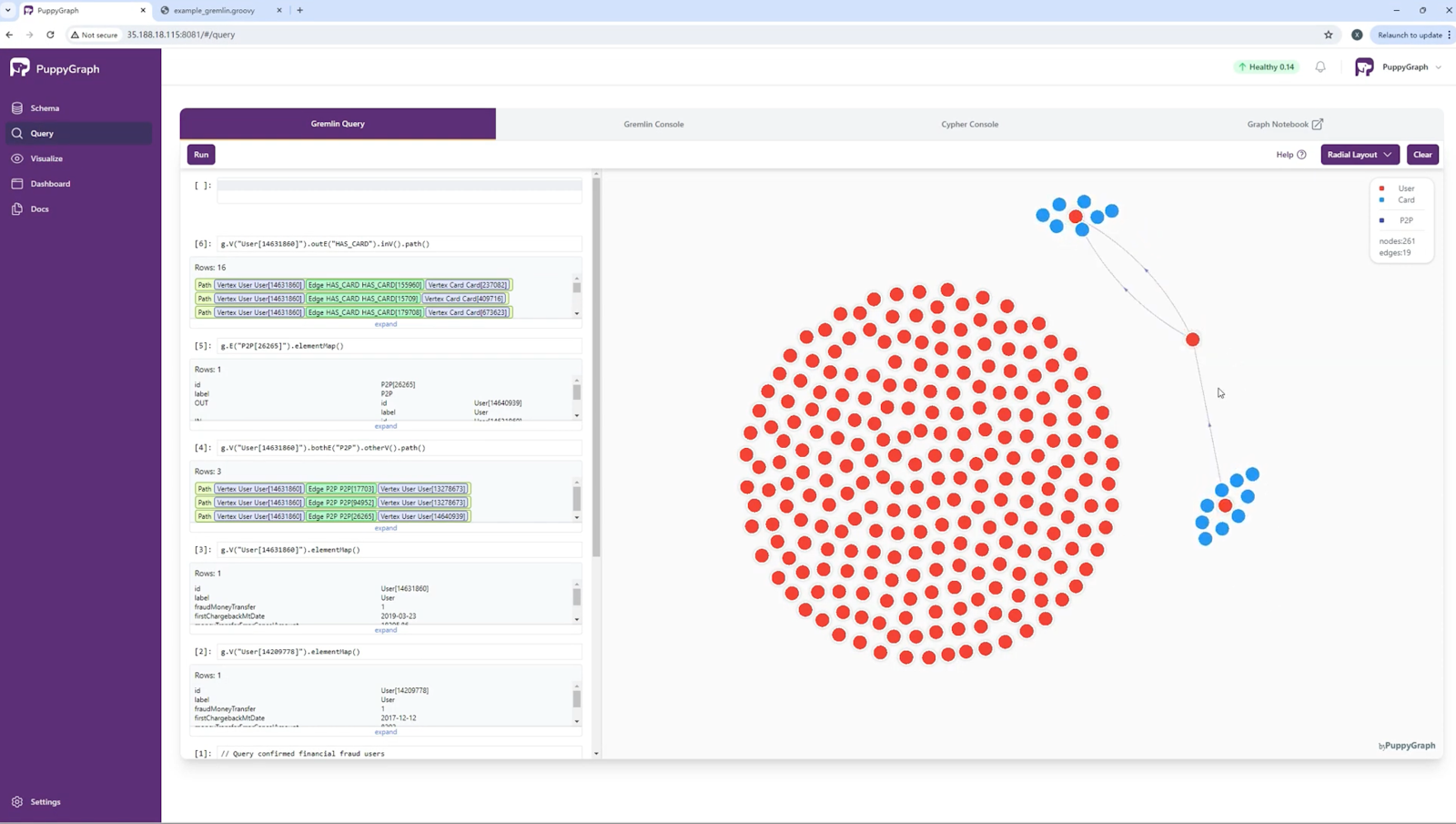
PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


Conclusion
Vector databases and graph databases address very different data challenges. Vectors power similarity search and semantic understanding, making them essential for AI workloads. Graph databases, on the other hand, focus on modeling and querying relationships, uncovering patterns and connections across complex networks. Choosing the right one depends less on which is "better" and more on the specific structure and needs of your data.
If you're exploring graph solutions, PuppyGraph makes it simple to add graph querying and visualization to your existing SQL or NoSQL data sources like MongoDB — with zero ETL, no data migration, and fast setup. Download our free developer edition or book a free demo with our graph expert team.

Matt is a developer at heart with a passion for data, software architecture, and writing technical content. In the past, Matt worked at some of the largest finance and insurance companies in Canada before pivoting to working for fast-growing startups.

Get started with PuppyGraph!


{kind=link}
Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install