

What Is an Ontology? Definition & Types

Understanding data is no longer just about storing and querying it: it is about interpreting meaning across increasingly complex and distributed systems. As modern applications rely on diverse data sources, schemas alone are insufficient to ensure consistency, accuracy, and shared understanding. This is where ontologies become essential, providing a structured semantic layer that defines how concepts relate and interact within a domain.
This article explores the role of ontologies as the foundation for meaningful data interpretation and intelligent systems. From their philosophical roots to their practical application in computer science, ontologies enable interoperability, reasoning, and explainability. They are especially critical in AI-driven environments, where precise semantics help bridge the gap between human intent and machine understanding.
What Is an Ontology?
An ontology is a structured framework that defines how concepts within a domain are related to each other. At its core, an ontology answers three fundamental questions: what entities exist, what properties they have, and how they are connected. Instead of merely storing data, it provides a semantic layer that gives meaning to that data, making it understandable to both humans and machines.

In practical terms, an ontology organizes knowledge into categories such as entities (e.g., “Author” or “Book”), relationships (e.g., “hasAuthor” or “worksWith”), and attributes (e.g., “name” or “email address”). These elements together form a coherent model of a domain, enabling systems to interpret data in a consistent and meaningful way.
Unlike simple data schemas, ontologies capture real-world semantics rather than just structural constraints. This distinction is what makes them especially valuable in modern data systems, where integration, interpretation, and reasoning across diverse sources are essential.
Ontology Meaning in Philosophy vs Computer Science
The concept of ontology originates in philosophy, where it refers to the study of being and existence. Philosophical ontology seeks to understand what kinds of things exist in the universe and how they can be categorized. Questions such as “What is reality?” or “What kinds of entities fundamentally exist?” are central to this discipline.
In computer science, ontology takes on a more practical and applied meaning. Rather than exploring abstract existence, it focuses on modeling a specific domain of knowledge in a structured and formal way. Here, an ontology defines a shared vocabulary that can be used by systems to communicate, interpret, and reason about data.
While philosophical ontology is concerned with universal truths, computational ontology is domain-specific and purpose-driven. For example, a healthcare ontology might define concepts like “Patient,” “Diagnosis,” and “Treatment,” along with their relationships. This enables different systems to exchange and interpret medical data consistently.
Despite their differences, both interpretations share a common goal: creating a structured understanding of the world. In computer science, this structured understanding becomes the foundation for intelligent systems and data interoperability.
What Are The Types of Ontologies
Ontologies can be classified into several types based on their scope and level of abstraction. Understanding these types helps clarify how ontologies are applied in different contexts.
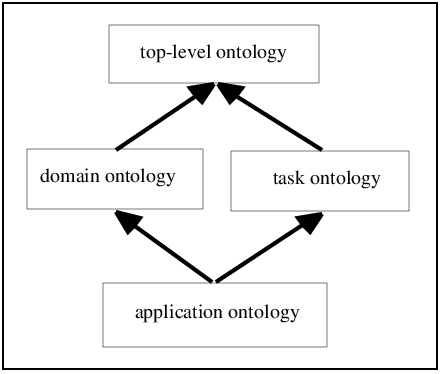
A top-level ontology, also known as an upper ontology, defines very general concepts that are universal across domains, such as “Entity,” “Event,” or “Object.” These ontologies provide a foundation that can be reused across multiple applications and industries.
Domain ontologies, on the other hand, are tailored to specific fields such as finance, healthcare, or cybersecurity. They define concepts and relationships that are relevant within a particular domain, making them more detailed and specialized.
Task ontologies focus on specific activities or processes, such as diagnosis, planning, or recommendation. They describe how tasks are performed and what concepts are involved, rather than modeling an entire domain.
Finally, application ontologies are designed for specific use cases or systems. They often combine elements from domain and task ontologies to address particular requirements, such as fraud detection or supply chain optimization.
Each type serves a distinct purpose, but in practice, they are often layered together to create a comprehensive knowledge model.
Key Components of an Ontology
An ontology is composed of several fundamental components that work together to represent knowledge in a structured way. These components form the building blocks of any ontology, regardless of its domain or complexity.
Entities, also known as classes or concepts, represent the primary objects within a domain. For example, in a retail ontology, entities might include “Customer,” “Product,” and “Order.” These classes define what kinds of things exist.
Relationships describe how entities are connected. For instance, a “Customer” may “places” an “Order,” and an “Order” may “contains” a “Product.” These relationships are essential for capturing the structure of the domain.
Attributes provide additional details about entities. A “Customer” might have attributes such as “name,” “email,” and “age.” Attributes help enrich the ontology with descriptive information.
Constraints and rules define logical conditions that must be satisfied. For example, an ontology might specify that every “Order” must be associated with exactly one “Customer.” These constraints ensure data consistency and enable reasoning.
Together, these components create a rich and expressive model of knowledge that goes beyond simple data storage.
How Ontologies Represent Knowledge
Ontologies represent knowledge by combining structure with semantics. They do not merely define data formats; they encode meaning in a way that allows systems to interpret and reason about information.
One common way to represent ontologies is through graph structures, where nodes represent entities and edges represent relationships. This graph-based representation aligns naturally with how knowledge is interconnected in the real world.
In addition to structure, ontologies can be represented using formal frameworks such as RDF (Resource Description Framework) and OWL (Web Ontology Language), which enable logical reasoning over knowledge through well-defined semantics.
Alternatively, ontologies can also be implemented using Labelled Property Graph (LPG) models, where entities and relationships are represented as nodes and edges enriched with properties. While LPG-based approaches emphasize flexibility and performance for graph traversal and querying, RDF/OWL-based models provide stronger support for formal reasoning and inference.
For example, if an ontology defines that all “Managers” are “Employees,” and a specific individual is a “Manager,” a system can infer that this individual is also an “Employee.” This ability to derive new knowledge from existing definitions is a key strength of ontologies.
By combining structured representation with logical reasoning, ontologies provide a powerful way to model and understand complex domains.
Why Ontologies Are Important in Data and AI
Ontologies play a critical role in modern data systems and artificial intelligence by providing a consistent and meaningful framework for interpreting data. As data becomes increasingly distributed and heterogeneous, the need for shared understanding becomes more pressing.
One of the main benefits of ontologies is interoperability. When different systems use the same ontology, they can exchange data without ambiguity. This is particularly important in environments where data comes from multiple sources with different schemas and formats.
Ontologies also enhance data quality by enforcing consistency and constraints. By defining clear relationships and rules, they reduce the risk of errors and inconsistencies in data.
In AI applications, ontologies provide context that helps models interpret data more accurately. For example, a natural language processing system can use an ontology to understand that “bank” in a financial context differs from “bank” in a geographical context.
Moreover, ontologies support explainability. Because they explicitly define relationships and rules, they make it easier to understand how decisions are made, which is increasingly important in AI systems.
How Ontologies Enable Shared Understanding Across Systems
In complex environments where multiple systems interact, shared understanding is essential. Ontologies serve as a common language that bridges the gap between different data models and interpretations.
When systems rely solely on schemas, they may interpret the same data differently. For example, one system might use “Client” while another uses “Customer,” even though they refer to the same concept. An ontology resolves this by defining a unified concept and mapping both terms to it.
This shared semantic layer allows systems to integrate data without requiring extensive transformation or duplication. It also enables more seamless collaboration between teams, as everyone operates with the same conceptual framework.
Ontologies are particularly valuable in data federation scenarios, where data remains in its original location but is accessed through a unified interface. By providing a consistent interpretation layer, ontologies make it possible to query and analyze data across sources as if it were a single dataset.
Ultimately, ontologies reduce ambiguity and improve communication, both between systems and among humans.
Ontology vs Taxonomy vs Knowledge Graph
Although often used interchangeably, ontology, taxonomy, and knowledge graph refer to distinct concepts with different levels of complexity.
A taxonomy is a hierarchical classification system. It organizes concepts into parent-child relationships, such as categories and subcategories. While useful for organization, it does not capture rich relationships beyond hierarchy.
An ontology, by contrast, provides a more comprehensive model. It includes not only hierarchical relationships but also various types of associations, attributes, and rules. This makes it more expressive and suitable for complex domains.
A knowledge graph is a data structure that represents information as a graph of entities and relationships. It often uses an ontology as its underlying schema. In other words, the ontology defines the structure and meaning, while the knowledge graph contains the actual data.
These three concepts are complementary rather than mutually exclusive. A taxonomy can be part of an ontology, and an ontology can underpin a knowledge graph. Understanding their differences helps in choosing the right approach for a given problem.
How Ontologies Are Used in Artificial Intelligence
In the era of Large Language Models (LLMs), ontologies have transitioned from static classification tools to "semantic anchors" that provide structure, truth, and reasoning capabilities to otherwise "black-box" neural networks.
Mitigating Hallucinations through Symbolic Grounding
"Hallucination", the tendency of models to invent facts, remains a core challenge in GenAI. Ontologies act as a symbolic foundation to constrain model outputs:
- Fact Verification: Systems can cross-reference generated text against the formal entities and constraints defined in the ontology.
- Logical Consistency: In high-stakes domains like medicine or law, ontologies ensure the AI adheres to strictly defined rules, preventing it from suggesting logically impossible relationships.
Powering GraphRAG
While traditional Retrieval-Augmented Generation (RAG) relies on vector similarity (finding text that looks similar), modern SOTA systems utilize GraphRAG. By mapping unstructured data onto an ontology-based knowledge graph, AI can perform contextual retrieval. Instead of simple keyword matching, the system follows logical paths (e.g., "Find all subsidiaries of Entity X") to execute multi-hop reasoning, connecting disparate data points to answer complex queries.
Neuro-symbolic AI and Explainability
This frontier research combines the pattern recognition of deep learning with the formal logic of ontologies.
- Explainable AI: When a model uses an ontology to reach a conclusion, it provides a transparent "trace" of its logic, making the decision-making process auditable.
- Few-shot Learning: By providing a structured semantic framework, models require significantly less data to master a new domain, as the underlying rules are already explicitly defined.
How to Build an Ontology (Step-by-Step)
Building an ontology is a systematic process that involves both domain expertise and technical design. The goal is to create a model that accurately represents a domain while remaining usable and scalable.
The process typically begins with defining the scope and purpose of the ontology. This involves identifying the domain, the intended use cases, and the key questions the ontology should answer.
Next, relevant concepts and entities are identified. This step often involves collaborating with domain experts to ensure accuracy and completeness. These concepts are then organized into a hierarchical structure.
Relationships between entities are defined to capture how concepts interact. This includes both hierarchical relationships and more complex associations.
Attributes and constraints are added to enrich the model and ensure consistency. At this stage, the ontology can be encoded using formal languages such as OWL for logic-based validation and inference, or implemented using Labelled Property Graph models, where constraints and semantics are enforced through graph structure, schema design, and application-level logic.
Finally, the ontology is tested and refined. This involves validating it against real-world data and use cases, and making adjustments as needed.
Building an ontology is an iterative process that evolves over time as new requirements and insights emerge.
Equips AI Agents with Ontology
Applying an ontology transforms data interaction from low-level, structure-centric access into a semantics-driven model. Instead of manually navigating tables and fields, both humans and AI agents operate through clearly defined concepts, relationships, and constraints.
On top of this foundation, Ontology Enforcement adds a layer of real-time query validation. It serves as a gatekeeper, ensuring that both human-authored and AI-generated queries adhere to the structural and logical rules defined within the domain.
Why Ontology Enforcement
- Eliminating Semantic Hallucinations: In complex data environments, AI agents may produce queries that are syntactically correct yet semantically flawed. For instance, an agent might successfully join two tables but base that join on a relationship that does not exist in reality. Ontology enforcement acts as a safeguard by restricting queries to a validated representation of how data is truly connected, helping to prevent these subtle but significant errors.
- The "Feedback Loop" for Self-Correction: Standard database error messages often provide limited semantic insight. With ontology enforcement, invalid operations instead return structured, LLM-friendly explanations that clearly indicate why a query violates the data model. This allows the agent to refine its behavior and gradually internalize the system’s underlying logic through fine-tuning or reinforcement learning.
Data Access with AI Assistant
Building on these capabilities, PuppyGraph offers a seamless, agent-driven interface for directly interacting with data through its built-in AI assistant. This assistant enables both developers and business users to navigate complex datasets using intuitive, conversational queries.
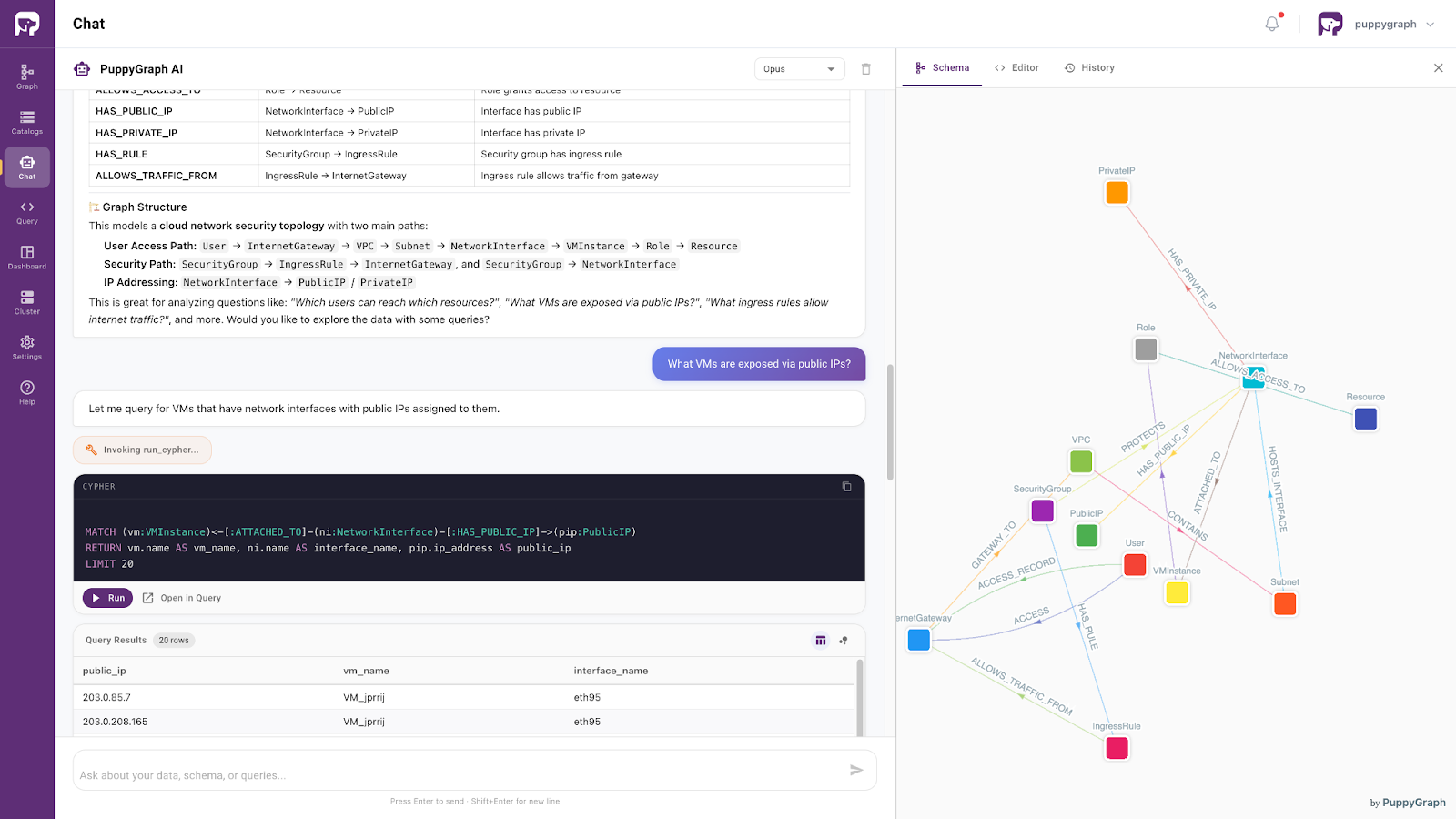
Built on an ontology-enforced foundation, the assistant supports precise, natural language-driven data access. By interpreting user intent within a clearly defined semantic framework, it consistently retrieves relevant information with high accuracy. As a result, the database evolves from a static and technically complex system into an interactive, responsive knowledge layer, one that preserves semantic integrity while delivering clear, human-readable insights.
Conclusion
Ontologies transform data from isolated structures into interconnected knowledge, enabling systems to reason, integrate, and communicate effectively. By explicitly defining entities, relationships, and constraints, they reduce ambiguity and provide a reliable foundation for both data management and AI applications. Their role becomes even more significant as systems scale and data complexity grows.
In the context of modern AI, ontologies are not just supportive tools but essential components for ensuring accuracy, consistency, and explainability. When combined with enforcement mechanisms and intelligent agents, they enable a shift toward semantic, trustworthy data interaction. As a result, ontologies are poised to play a central role in the evolution of data systems and AI-driven decision-making.
Start building with the forever-free PuppyGraph Developer Edition, or book a demo to see how to leverage ontologies for reliable, AI-driven data access.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install