

What Is KuzuDB?

KuzuDB (officially styled Kuzu, originally Kùzu) is an embedded property graph database: a graph engine that runs inside your application process the way SQLite or DuckDB does, rather than as a server you connect to. It implements the Cypher query language, stores data in a columnar disk format, and was designed from the ground up for analytical graph workloads such as multi-hop traversals and pattern matching. It is open source under the MIT license.
Anyone evaluating KuzuDB in 2026 also needs the second half of the story: in October 2025 the project was archived after Apple acquired the company behind it, and maintenance has passed to community forks. This post covers the technology itself, which remains worth understanding because it lives on in those forks: the data model, the Cypher dialect, the analytical architecture, and the AI use cases that became its main audience.
What is KuzuDB?
KuzuDB is an in-process graph database management system. There is no server to deploy, no cluster to size, no connection pool to manage: you import a library, point it at a database file (or run it fully in memory), and issue Cypher queries from your application code. It occupies the same position relative to graph databases that DuckDB occupies relative to analytical SQL databases.
The project came out of the Data Systems Group at the University of Waterloo, led by associate professor Semih Salihoğlu. It was introduced publicly in late 2022 alongside a CIDR 2023 paper that laid out the design rationale: graph applications need storage and query processing optimized for many-to-many joins, cyclic join patterns, recursive joins, and semi-structured data. Kùzu Inc. was founded in Ontario in 2023 to commercialize the research, and over the next two and a half years shipped a steady cadence of releases that added a full-text search index, a native vector index, lakehouse interoperability, and a WebAssembly build.
What happened to KuzuDB?
The GitHub repository was archived on October 10, 2025, the same day version 0.11.3 shipped as a final release, with a note saying the team was “working on something new”. The explanation surfaced in February 2026, when an EU Digital Markets Act filing showed that Apple had agreed on October 9, 2025 to acquire Kùzu Inc.; Apple has not said what it plans to do with the technology. Upstream is now read-only: released versions keep working, and 0.11.3 bundles the most commonly used extensions, which previously downloaded from a Kuzu-hosted server, but there will be no further fixes or features from the original authors. The documentation survives at kuzudb.github.io. Because the code is MIT-licensed, the community forked quickly.
The practical guidance is short: existing deployments can pin 0.11.3 safely for now, with a fork migration as the durable path.
KuzuDB’s property graph data model
KuzuDB implements the property graph model, the same conceptual model used by Neo4j, Amazon Neptune, and most modern graph systems: nodes and relationships, each carrying typed key-value properties, with relationships directed and first-class. But it makes one decision that sets it apart from most of its peers: the schema is structured and declared up front.
Data is organized into node tables and relationship tables. The documentation is explicit that it uses the word table rather than label “because Kuzu is ultimately a relational system” under the hood. Creating a graph starts with DDL:
CREATE NODE TABLE User (
name STRING PRIMARY KEY,
age INT64,
reg_date DATE
);
CREATE REL TABLE Follows (
FROM User TO User,
since DATE
);Node tables require a primary key (string, numeric, date, or blob), which gets an automatic index. Relationship tables declare which node tables they connect and can carry multiplicity constraints (MANY_MANY, ONE_MANY, MANY_ONE, ONE_ONE) that the engine enforces. Properties are strongly typed.
This is a real departure from Neo4j’s schema-optional approach, where any node can take any label and property at any time, and the trade-off runs both ways. Declared structure is what enables the columnar layout described in the architecture section: the engine knows every User has an INT64 age, so ages can live in a dense typed column. The cost is upfront modeling and ALTER statements when the data’s shape changes. For analytical work over data whose structure is known (often originating in relational tables anyway), the structured model is mostly an advantage; for exploratory ingestion of messy data, it is friction that schema-optional systems do not impose.
KuzuDB and the Cypher query language
KuzuDB adopted Cypher rather than inventing a query language, so existing graph practitioners could be productive immediately. The core read syntax is standard:
MATCH (a:User)-[f:Follows]->(b:User)
WHERE a.age > 30
RETURN b.name, count(*) AS followers
ORDER BY followers DESC
LIMIT 10;Variable-length and recursive traversals use the familiar star syntax (-[:Follows*1..3]->), with shortest-path support. Around the standard core, KuzuDB adds statements its embedded, analytics-oriented design demanded. The most used is COPY FROM, a bulk loader that ingests CSV and Parquet files (or attached external tables) far faster than row-at-a-time CREATE statements:
COPY User FROM "users.parquet";
COPY Follows FROM "follows.parquet";The DDL above is also KuzuDB-specific, and a query referencing a nonexistent table or property is rejected outright rather than silently matching nothing. The dialect differences sit almost entirely at the edges (loading, DDL, administration); the MATCH-WHERE-RETURN core carries over unchanged, so queries written for KuzuDB stay portable to other Cypher systems and to its own forks.
How to get started with KuzuDB
The released packages remain installable and functional. Given the archived status, pin the final version explicitly:
pip install kuzu==0.11.3
A minimal session, using an on-disk database (pass :memory: instead of a path to run fully in memory):
import kuzu
db = kuzu.Database("example.kuzu")
conn = kuzu.Connection(db)
conn.execute("CREATE NODE TABLE User(name STRING PRIMARY KEY, age INT64)")
conn.execute("CREATE REL TABLE Follows(FROM User TO User, since INT64)")
conn.execute('COPY User FROM "users.csv"')
conn.execute('COPY Follows FROM "follows.csv"')
result = conn.execute(
"MATCH (a:User)-[:Follows]->(b:User) RETURN a.name, b.name"
)
while result.has_next():
print(result.get_next())The Cypher reference and client API guides remain at kuzudb.github.io/docs. For anything beyond learning and experimentation, start from one of the community forks; it preserves the data model and Cypher surface, so everything in this post applies with minor version differences.
How KuzuDB works: an architecture for analytical graph workloads
Graph workloads split roughly the way relational ones do. Transactional (OLTP-style) workloads look up a record, walk a hop or two, and write, in milliseconds, from many concurrent clients. Analytical workloads scan large portions of the graph, traverse many hops, and aggregate along the way; recommendations, fraud-pattern mining, dependency analysis, and graph data science all live here.
Most well-known graph databases grew up serving the first side: record-oriented storage, point-lookup indexes, tuple-at-a-time execution. KuzuDB’s designers made the opposite bet and imported ideas from analytical (OLAP) database research. Four of them do most of the work.
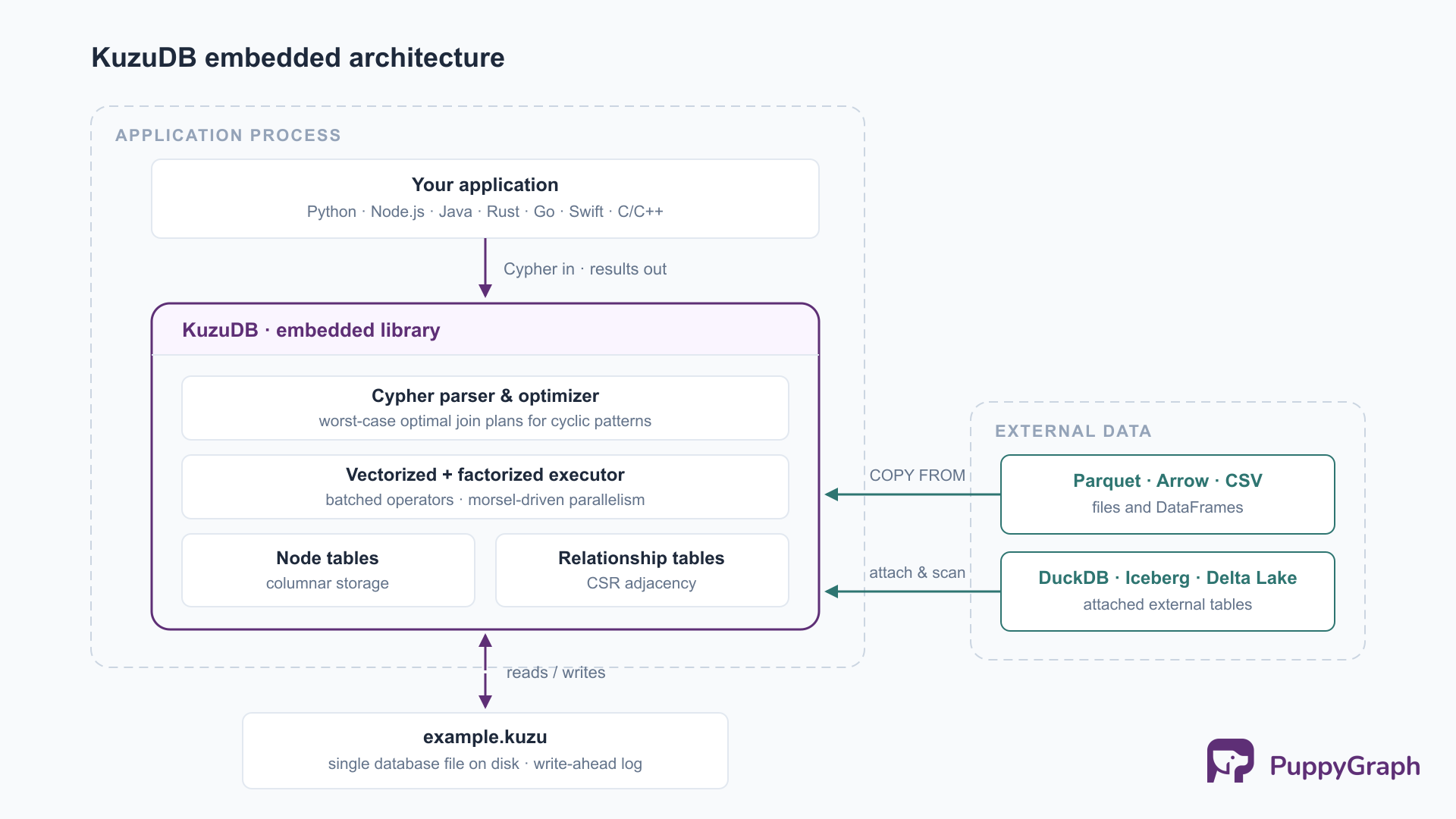
Columnar storage on disk. Node properties are stored column by column, so a query needing two properties out of twenty reads only those two columns. Relationships live in compressed sparse row (CSR) structures, a compact adjacency representation that makes “all neighbors of this node” a sequential scan rather than an index lookup per edge. The storage is disk-based by design: the CIDR 2023 paper describes a system meant for graphs larger than memory.
Vectorized query processing. Like DuckDB, KuzuDB’s operators process batches of values (on the order of a thousand tuples) instead of one row at a time, amortizing interpretation overhead and keeping the working set in CPU cache.
Factorized intermediate results. The signature technique. Graph queries produce exploding intermediates: if one user follows 1,000 people who each follow 1,000 more, a naive two-hop query materializes a million rows. Factorization keeps intermediates in a compressed, Cartesian-product form, so aggregations and projections push through without materializing the explosion. The Kuzu team wrote an accessible explanation of factorization; the technique comes from database theory and is rare in production systems. It pays off exactly where traversals are wide and many-to-many, which is where record-at-a-time engines drown.
Worst-case optimal joins. Cyclic patterns such as triangle finding are pathological for pairwise join planning, because every join order produces intermediates far larger than the final result. Worst-case optimal join algorithms match such patterns one variable at a time across all relations simultaneously, with output bounded by theory. KuzuDB uses them selectively for cyclic subqueries.
On top of these, the engine parallelizes across cores with morsel-driven scheduling and provides serializable ACID transactions. A database opens in on-disk mode (a single file with write-ahead logging) or in-memory mode (gone with the process; convenient for tests and ephemeral work).
The same bet shows in what KuzuDB does not try to be: a single-node library with no distributed execution, no replication, and no built-in server for concurrent remote clients. Scale comes from the disk-based design and from using one machine’s cores well, not from adding machines. That is a coherent scope, not a gap; a great many real graphs fit on one modern machine, and the coherence is why an embedded library could be credible on workloads usually pitched as needing a cluster.
Key features beyond the core engine
Native vector index. Version 0.9.0 (April 2025) added an HNSW-based vector index for similarity search over embeddings. It is disk-based rather than memory-resident, built on Kuzu’s own storage, and supports predicate-agnostic filtered search: nearest-neighbor search over an arbitrary query-defined subset of vectors. The design was published as the NaviX paper at VLDB.
Full-text search. Added in version 0.8.0, so keyword relevance, vector similarity, and graph traversal combine in one Cypher statement against one embedded database.
Built-in graph algorithms. PageRank, shortest paths, connected components, and others, callable without exporting the graph to a separate framework.
Columnar-ecosystem interoperability. Reads and writes Parquet and Arrow, attaches and scans DuckDB databases, and scans Iceberg and Delta Lake tables. Query results convert to Pandas or Polars DataFrames without a serialization step.
Broad language bindings. Python, Node.js, Java, Rust, Go, Swift, C, and C++ officially, community bindings for .NET, Ruby, Nim, and Elixir, plus a WebAssembly build that runs the full database in a browser.
KuzuDB for AI applications: knowledge graphs and RAG
KuzuDB’s later releases and most of its community growth coincided with the rise of LLM applications, and the embedded design fit that world unusually well.
Knowledge graphs and agent memory
A knowledge graph gives an AI application explicit structure: entities, typed relationships, and properties, queryable with a precision embedding similarity cannot offer. The traditional obstacle is operational, since a graph database server is a heavy dependency for one application’s knowledge graph. An embedded engine removes it: the knowledge graph is a file inside the application, created at runtime. That made KuzuDB popular for per-session and per-user graphs, for example as structured memory for an agent, where each conversation gets a small graph that is cheap to create and discard.
The structured schema earns its keep here too. When an LLM generates Cypher (the text-to-Cypher pattern), a declared schema is a compact, accurate description of what the graph contains, and strict validation rejects queries referencing tables or properties that do not exist instead of silently returning nothing. The ecosystem reflected the fit: the langchain-kuzu package supports building graphs from text and running question-answering chains over them, LlamaIndex shipped Kuzu integrations for its property graph index, and the team’s own LLMs-and-graphs series remains a useful survey of the design space.
Retrieval-augmented generation
RAG pipelines retrieve context for an LLM before it answers. The baseline embeds document chunks and retrieves by vector similarity; its known weakness is questions whose answers depend on relationships across documents (“which customers are affected by the outage in service X?”) rather than any single similar passage. Graph-augmented RAG (GraphRAG) retrieves through a knowledge graph instead: find entry-point entities, traverse their relationships, and hand the LLM connected context.
KuzuDB’s pitch here was consolidation. GraphRAG needs three kinds of retrieval: vector similarity for entry points, optionally full-text search for keyword grounding, and traversal to expand context. In KuzuDB all three run in one embedded engine and compose in a single Cypher query, where the alternative is wiring a vector store, a graph store, and a search index together and reconciling identifiers across them at query time. Because the vector index is disk-based, embedding collections scale past memory, and predicate-filtered search lets retrieval respect structure (only entities of a given type, only documents a user can access) without post-filtering. For single-tenant or per-session RAG, the all-in-one embedded shape was a genuinely good fit, and the forks inherit it.
Common KuzuDB use cases
Embedded graph analytics inside applications. Shipping graph features (dependency views, impact analysis, network exploration) without making the customer operate a graph database; the database is a file in the application’s data directory.
Graph data science workflows. Loading Parquet or DataFrame data, running traversals and algorithms, and pulling results back into Pandas or Polars, all inside a notebook process.
AI knowledge graphs and RAG. The per-session graphs, agent memory, and GraphRAG patterns covered above, which became the project’s most visible adoption driver.
Local-first and browser deployments. The WebAssembly build runs the engine client-side, querying data that never leaves the user’s machine.
Prototyping graph models. Near-zero setup cost plus Cypher made KuzuDB a fast way to validate a graph model before committing to heavier infrastructure, with queries that port to other Cypher engines.
The common thread: the graph lives close to one process and one user. None of these require a shared, always-on, multi-client graph service, and that boundary is where the limitations begin.
Advantages and limitations of KuzuDB
The advantages: zero operational footprint, strong analytical performance from a columnar, vectorized, factorized engine, a schema that doubles as documentation and validation, first-class Parquet/Arrow/DuckDB/lakehouse interop, vector and full-text search in the same engine, an MIT license, and bindings for most mainstream languages.
The limitations divide into architectural ones and the status one. KuzuDB is single-node and in-process: no distributed execution, no replication, no high-availability story, no built-in server for many clients across processes. It is an analytical library, not a shared transactional service, and the mandatory schema adds friction for heterogeneous, fast-evolving data. These are scope decisions, not flaws, but they mark where the tool stops. The status limitation is the one covered at the top of this post: upstream is archived, the project’s future runs through community forks, and choosing KuzuDB today really means choosing one of them.
The remaining consideration sits outside the tool itself: everything above, forks included, shares the assumption that data gets imported into the engine’s own storage before it can be queried as a graph. Often the underlying requirement behind a KuzuDB evaluation is analytical graph queries over data that already lives in relational systems: warehouse tables, lakehouse formats, operational databases. For a bounded, single-user copy of that data, the embedded import model works well. When the queries need to run over shared, governed, warehouse-scale data, maintaining a separate graph copy becomes the dominant cost, and a different shape fits better. PuppyGraph approaches the same requirement from the opposite direction: a distributed graph query engine that attaches a graph schema directly to existing tables in sources like PostgreSQL, Snowflake, and Iceberg and queries them in place, with no ETL, using the same columnar, vectorized execution approach for traversal workloads that this post has described. It speaks openCypher, so query skills and many queries transfer from KuzuDB directly. The fit is different rather than better: the community forked version continue the embedded, in-process model, while PuppyGraph extends the same analytical approach to data that stays where it is.
Conclusion
KuzuDB demonstrated that an embedded, single-node library could be a serious analytical graph database, by pairing columnar storage and CSR adjacency with vectorized execution, factorized intermediates, and worst-case optimal joins, all behind a Cypher interface and a structured property graph schema. It found its largest audience in AI applications, where per-session knowledge graphs and all-in-one GraphRAG retrieval rewarded exactly the shape it had.
Its story since October 2025 is a familiar open source arc: the company was acquired, upstream went read-only, and the MIT license let the community carry the architecture forward through community forks. The ideas KuzuDB validated live on in those forks for embedded workloads, and the same analytical lineage continues at the other end of the deployment spectrum in engines that query warehouse and lakehouse data in place.
Try the forever-free PuppyGraph Developer Edition and book a demo with the team to see how openCypher and Gremlin queries run over warehouse and lakehouse tables, with no graph-specific ETL, when a graph workload outgrows an embedded engine.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install