

AI Graph Database: What Is it?

For many AI applications, the bottleneck isn't model reasoning since models have become extremely capable in the last few years. The biggest factor is relationship context. LLMs can read whatever's in their context window and answer fluently over it, but the way most applications feed them data, such as embedding similarity over a vector store, doesn't reliably expose how entities are connected. Two accounts can sit on the same fraud ring and still look like unrelated documents. That gap is where AI graph databases come in: they make relationships first-class, queryable, and auditable. The practical question isn't whether graphs are useful for AI; it's whether your workload needs a dedicated graph store, a graph layer over existing warehouse data, or no graph layer at all. This guide covers what an AI graph database is, why graph structures fit artificial intelligence workloads that need explicit relationships and multi-hop retrieval, how they work, the architectural patterns teams use, and the tools in the category today. Let’s start by looking a bit closer at what an AI graph database is.
What Is an AI Graph Database?
An AI graph database is a graph database. The AI piece comes into play in how it's used, namely using the graph database as the structured data, retrieval, and evidence layer for AI applications. The underlying graph data model is the same one that graph systems have used for years. What changes is the workload sitting on top: retrieval augmented generation, AI agents, recommendation systems, fraud detection pipelines, and knowledge graphs that ground large language models in real, verifiable connections.
Nodes, edges, and properties: the building blocks
Every graph database stores data as nodes and edges with properties on both. Nodes are the data points representing entities such as users, accounts, documents, or devices. Edges are typed connections like OWNS, PURCHASED, REPORTED_FRAUD, or LIVES_IN. Both entities and relationships are first-class data points that the engine can traverse. That vocabulary models almost any domain where relationships matter, from a social network of connected entities to a supply chain of suppliers and shipments.
How an AI graph database differs from traditional databases
Relational databases organize data in rows and tables and join them through foreign keys. Document databases store data as JSON-like documents and rely on flexible schemas. Graph databases store data as nodes and edges with first-class connections, so traversing related data is a native operation rather than a chain of complex joins.
The “AI” part does not mean the database itself is intelligent. It means the graph database is being used to give AI systems structured context: entities, relationships, paths, and source-backed facts that an LLM or agent can retrieve before answering. Some graph databases add AI-specific features such as vector search or framework integrations, but the core value to an AI use case is simpler: they make connected data queryable for AI workloads that need more than similar text chunks.
Why Graph Databases Matter for AI
Vector search is how most teams started doing RAG. This process looks like: embed documents, embed the query, return the nearest neighbors, and pass the result to an LLM. That works well for many unstructured retrieval tasks. Vector similarity alone is a poor fit, though, when the question depends on explicit multi-hop relationships across data points.
It doesn’t mean that vector search is not the right fit sometimes, but the value of a graph database for AI shows up in three places where vector queries come up a bit short: relationship-aware retrieval, bounded multi-hop traversal, and evidence paths.
Relationships are first-class. In a graph database, the connection between two entities is its own object with a label, direction, and properties. Vector indexes and relational databases can both represent relationships, but variable-length, path-oriented traversal is usually less natural there than in a graph model. AI systems reasoning about people, transactions, devices, or claims are reasoning about relationships, not just embeddings.
Multi-hop retrieval becomes explicit. A doozy of a question, like "which customers purchased a product that was reviewed by a user who later filed a fraud report?" can be expressed as a graph pattern when those entities and relationships are modeled. The database isn't reasoning for the LLM; it returns a structured path the application can inspect, rank, and pass to the model. With bounded hops and the right indexes, complex queries on highly connected data stay interactive; without constraints, multi-hop traversal can get expensive fast.
Provenance is easier to expose. If nodes and edges carry source metadata, timestamps, and confidence signals, the application can return the path behind an answer. That makes graph-backed answers easier to audit than opaque vector matches, but only when provenance is modeled intentionally.

Microsoft Research's GraphRAG work reported "substantial improvements" over baseline RAG on complex queries when LLM answers are grounded in a knowledge graph. The common pattern across implementations is that graph structure gives the retriever more than semantic similarity: entities, relationships, communities, and source-backed paths all become retrieval signals.
There's also a hallucination angle. Vector retrieval surfaces passages that look relevant, but it can't really check whether two entities are linked in the source data. A graph traversal can. When the model claims "Account A funded Account B," the application can return the path or a "not supported by available graph data" response. That's not the same as proving the claim false (the graph may be incomplete or stale), but it's a meaningful upgrade over a confidently fabricated answer.
How AI Graph Databases Work
Under the hood, a graph database does three things well: it stores data as nodes and edges so traversals are fast, it speaks one or more graph query languages, and it exposes APIs and SDKs that the rest of the stack uses.
Storage and traversal
Traversals are the core operation. When a query asks “find all accounts connected to this user within three hops, then return the riskiest counterparties,” the graph database follows relationships rather than treating each entity as an isolated record. Native graph databases usually store graph structures directly, so the engine can traverse relationships from node to node.
Graph query engines such as PuppyGraph take a different approach: they map existing warehouse, lakehouse, or relational data into a graph model and execute graph queries over that mapped data without requiring teams to copy it into a separate graph store. Either way, the system is designed around relationship traversal, not just row lookup or document similarity.
Query language support
Most graph databases support at least one of two graph query languages:
- Cypher, originally created by Neo4j, is one of the most widely used declarative property-graph query languages. The openCypher project made much of the language available as an open specification, and newer standardization work is converging around ISO GQL. The Cypher query language reads almost like ASCII art for graph patterns, and LLMs are reasonably good at producing it given a clear schema and examples.
- Gremlin (part of Apache TinkerPop) is a traversal-style query language popular in enterprise environments and supported by AWS Neptune, JanusGraph, and others.
Graph query languages matter because they give AI applications a structured way to ask relationship-heavy questions. PuppyGraph supports openCypher and Gremlin, two common graph query languages for traversing connected data. That matters for AI teams because LLMs and agent frameworks can generate or call graph queries when they have a clear schema, examples, and guardrails.
Property graphs vs RDF graphs
Within graph databases, two data models dominate. Property graphs attach key-value properties to nodes and edges and are the common choice for AI workloads; Neo4j, Memgraph, TigerGraph, FalkorDB, and PuppyGraph all use them. RDF graphs model the world as (subject, predicate, object) triples from the semantic web tradition and work well with vocabulary-heavy ontologies. Around the query layer sit indexes, flexible schemas, and increasingly native vector indexes, so semantic search and graph traversal run inside a single query.
AI Graph Database Architecture
There are two main architectural patterns when it comes to enabling LLMs and agents with graph query capabilities, and the choice between them is often the most consequential decision a platform team makes.
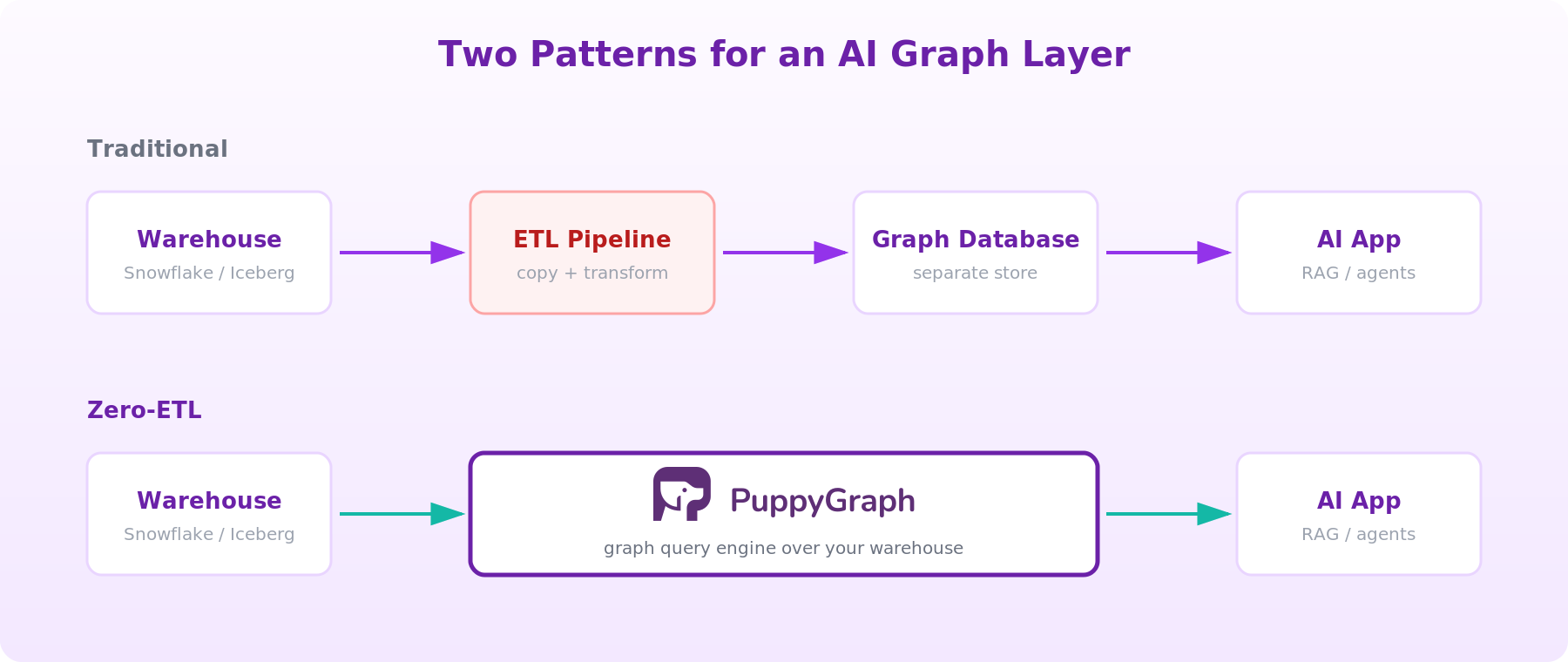
Pattern 1: A dedicated graph database
Stand up a graph database such as Neo4j, TigerGraph, Memgraph, or FalkorDB, ETL data from operational systems and the warehouse into the graph store, maintain the schema, and query it from your AI application. This pattern fits when the workload is graph-native end to end: deep IP-graph fraud detection, write-heavy operational graphs, or applications where the graph is itself the source of truth. The cost of this approach is the pipeline: every new source is another ingestion path, every schema change coordinates two stores, and you end up paying for storage and operations twice. There is also going to be some latency in getting data from store to store, leading to stale graph data, which can then degrade AI answers in ways that are hard to debug.
Pattern 2: Zero-ETL graph engine on existing data
This is the pattern we like the most and what PuppyGraph was built for. This architecture allows you to keep the source of truth as your data lakehouse or warehouse and run a graph query engine on top that maps tables to nodes and edges and translates Cypher or Gremlin queries into pushed-down operations against the underlying store. PuppyGraph takes this approach as a real-time, zero-ETL graph query engine. It plugs into Snowflake, Databricks, Apache Iceberg, Delta Lake, Postgres, MySQL, DuckDB, BigQuery, and S3-backed formats and exposes them as a unified graph queryable in Cypher and Gremlin against the same governed data, in place. Zero-ETL removes the copy step, not the modeling step: teams still need to define which tables become nodes, which columns become relationships, how IDs join, and how to handle ambiguous or many-to-many joins.
For teams whose data already lives in a lakehouse, this collapses the pipeline and means no separate graph store, no second source of truth. Our graph query engine allows teams to execute 10-hop queries in seconds at petabyte scale, with everything deployable in under 10 minutes. The proof that this approach is easy to see as some of the world’s largest companies (including Coinbase, AMD, Netskope, and Palo Alto Networks) use us to power their most pressing use cases.
Choosing between them
Dedicated graph databases optimize for graph-native workloads at the cost of an additional operational system. Graph query engines optimize for time-to-graph at the cost of pushing work onto the underlying store. Most AI teams sitting on a warehouse will get to a working GraphRAG or AI agent prototype faster with the engine pattern; for greenfield, write-heavy graph workloads, a native graph database may still fit better. Freshness is a separate decision: a dedicated graph database takes a lot of work to set up and ETL data too, while a zero-ETL engine inherits the freshness and latency profile of the underlying warehouse natively.
Role of AI in Graph Databases
AI shows up inside graph databases in two ways: as the workload the graph database powers, and as the technology used to interact with it. On the workload side, five patterns dominate.
GraphRAG: retrieval augmented generation over graphs
Instead of retrieving similar text chunks for an LLM, graph RAG retrieves a connected subgraph: the entities mentioned in the query, their neighbors, and the relationships between them. The LLM gets structured context with attributable paths instead of a bag of paragraphs. In practice, graph retrieval often complements vector retrieval rather than replacing it; embeddings are still useful for fuzzy matching, entity linking, and candidate discovery. PuppyGraph's GraphRAG vs knowledge graph guide walks through the pattern in detail.
The harder part isn't the graph query; it's building a graph that's complete enough to trust. Teams underestimate entity resolution, duplicate nodes, conflicting facts, extraction errors, and graph refresh cadence. If the graph is generated from documents via LLM extraction, store extraction confidence and source spans on each edge so the application can tell verified facts from inferred ones.
AI agent memory and long-term context
Long-running AI agents need to remember prior actions, established facts, and the entities they've encountered. Storing that as a graph makes those relationships explicit. The hard parts are entity resolution (is "Acme Corp" and "Acme, Inc." the same node?), deciding what becomes a durable memory, pruning stale facts, and retrieving only the subgraph relevant to the next action. The graph is the structured part of memory that should outlive any single context window.
Knowledge graphs for unstructured data
Healthcare, life sciences, legal, and knowledge management teams build knowledge graphs to encode entities, terminology, and relationships LLMs would otherwise hallucinate around. The graph becomes a structured knowledge layer AI applications can query, ideally with links back to the source documents or systems of record. It often starts life as unstructured data; modern pipelines use LLMs to extract entities and relationships from documents, web pages, and contracts, then load them into a graph database where graph analytics queries surface indirect connections flat search misses.
Fraud detection across connected entities
Fraud detection is the canonical example of why relationships matter for AI. Fraud rings are easier to miss when each account is scored in isolation. A graph model lets investigators ask whether accounts share devices, payment instruments, addresses, IP ranges, or behavioral patterns. A query walking from a flagged account to its shared devices, then to the other accounts on those devices, then to the customers behind them, can expose relationship patterns that row-level scoring or rule-based review may miss. Credit card fraud teams use graph analytics for community detection over the transaction graph to surface hidden patterns among fraud rings. This doesn't eliminate false positives, but it gives the detection system relational features a row-level model can't see; the same data points show up in cybersecurity, anti-money-laundering, and supply chain risk.
Graph machine learning
Graph Neural Networks (GNNs) learn directly from graph structure, capturing patterns that flat embeddings miss. Recommendation systems and drug discovery models use GNNs, often trained on data exported from a graph database. Data scientists pair GNNs with classical graph algorithms like PageRank and shortest-path, run them through graph analytics pipelines, and use linear algebra over the adjacency matrix to compute features that improve model accuracy. PuppyGraph's primer on graph AI goes deeper.
On the interaction side, AI is increasingly writing the queries itself. LLMs are now used to translate natural language queries from users into Cypher or Gremlin, which is what the next section is about.
AI-Powered Querying and Reasoning
The most visible recent change in graph databases is that many complex queries no longer need to be hand-written. Given a clear schema, examples, and reasonable guardrails, an LLM can often generate useful Cypher for common investigative questions. That collapses the skill barrier between "I have a question" and "I have a query." In production, teams still need query validation, permission boundaries, and fallbacks for ambiguous questions, since LLM-generated queries aren't reliable enough to run unsupervised.
Natural language to Cypher
Here's a concrete example. Imagine a fraud-investigation graph with Customer, Account, Transaction, and Device nodes. A natural-language question like "Which customers shared a device with an account flagged in the last 30 days?" can be theoretically translated by an LLM into a single Cypher query:
MATCH (flagged:Account {status: 'flagged'})
-[:USED]-(d:Device)-
[:USED]-(other:Account)-[:OWNED_BY]->(c:Customer)
WHERE flagged.flagged_at > datetime() - duration({days: 30})
AND flagged <> other
RETURN DISTINCT c.id, c.name, count(d) AS shared_devices
ORDER BY shared_devices DESC
LIMIT 25That single graph query does three hops, an aggregation, and a filter. It returns ranked, auditable results an investigator can act on. A vector store could find "similar" accounts, but it can't answer the actual question without a separate retrieval and ranking pipeline bolted on top.
A quick safety note: As with any natural-language-to-query implementation, you shouldn't run LLM-generated Cypher with broad production credentials. Use read-only roles, tenant filters, query allowlists or validators, timeout and hop caps, and schema-level permissions. Natural-language-to-query is useful, but it makes query generation an application security boundary; prompt injection or ambiguous questions can otherwise turn a generated traversal into a data leak or a runaway scan.
Hybrid retrieval: combining graph and vector search
The strongest AI systems often combine both approaches. Vector search handles fuzzy semantic search over unstructured text and returns candidate entities; the graph database takes those entities as starting points for graph traversal, walking out to related data the LLM needs. Hybrid retrieval gets you semantic recall from embeddings and structured relational evidence from the graph in the same query.
Frameworks like LangChain ship Cypher chains for the natural-language-to-graph-query loop, and they work better when the engine speaks standard openCypher and exposes a clean schema. Engines that also support SQL allow the LLM to fall back to SQL on subgraphs that don't require traversal. The reasoning stays with the LLM; the graph supplies the evidence and the path.
Popular AI Graph Database Tools
For AI application teams, the landscape is easiest to evaluate in two groups. The right graph database for a given team depends less on brand and more on how diverse data sets, write volume, and existing cloud infrastructure shape the buying decision.
Graph query engines on existing data
Graph query engines sit on top of relational or lakehouse storage and present existing data as a graph database without copying it.
- PuppyGraph is a real-time, zero-ETL graph query engine that turns Snowflake, Databricks, Apache Iceberg, Delta Lake, Postgres, and similar systems into a unified graph queryable in Cypher and Gremlin against the data already in your lakehouse or warehouse. It supports property graphs and graph analytics workloads in place, without a separate graph store, and counts roughly half of the top 20 cybersecurity companies among its users.
Native graph databases
Native graph databases store graph data in a graph-shaped engine and ship dedicated graph infrastructure.
- Neo4j is the category-defining vendor of graph database technology, with a mature ecosystem, broad Cypher adoption, and a strong AI/GraphRAG story through its Knowledge Graph Builder and GraphRAG SDK.
- TigerGraph focuses on real-time graph analytics and graph algorithms at large scale, positioned around AI agents and fraud detection.
- Memgraph is a high-performance, in-memory graph database with strong streaming support and a documented focus on agentic AI workloads and graph analytics.
- FalkorDB is a newer entrant built on Redis, designed specifically around GraphRAG performance for AI/ML applications.
- AWS Neptune is a managed graph database (not a query engine over existing relational data) with broad protocol support: Gremlin and openCypher for property graphs, SPARQL for RDF graphs. It's a strong fit for AWS-native teams that want managed graph infrastructure rather than a separate operational graph stack.
How to choose
For teams evaluating database types, the right question isn't "which is the best graph database?" It's "what does our data and workload look like, and which architecture fits?" The buyer's checklist usually includes query language support (Cypher, Gremlin), zero-ETL versus dedicated store, native vector search, multi-hop performance at scale, deployment time, and cost model. If your AI application is doing read-heavy traversals over data already in your warehouse, a graph engine over the warehouse minimizes the surface area you operate. If it's doing high-volume writes against a graph with no warehouse source of truth, a native graph database is the cleaner fit. Match the system to the data and queries you'll actually run, then validate with a small load test. A useful prototype tests your top multi-hop questions, worst-case fan-out, freshness requirements, permission boundaries, generated-query safety, and whether returned paths are understandable enough for a human reviewer.
When an AI graph database is overkill
A graph layer is not free. Skip or defer it when your questions are mostly document lookup or summarization, when you don't have reliable entity extraction or stable IDs across sources, when the graph would change faster than ingestion can keep up, when you can't enforce permissions across traversals, or when vector search plus metadata filters already answer what you need. Add a graph layer when relationships, paths, and provenance are doing real work for your application.
Conclusion
AI graph databases aren't a new product category; they're how teams operationalize graph data structures for AI workloads. If a graph database is needed, the most meaningful architectural choice is whether to use a dedicated graph database with an ETL pipeline or a graph query engine over the data you already have. Either pattern can give you multi-hop retrieval, structured evidence, and explainable paths that vector search and traditional databases alone don't, but only when the graph is modeled, refreshed, and governed with the same discipline as the rest of your AI stack.
If your data already lives in a warehouse, start by testing whether a zero-ETL graph layer can answer the relationship-heavy questions your RAG or agent workflow currently can't. For teams aiming to operationalize a graph database for AI use cases, PuppyGraph provides a practical solution: querying existing relational and lakehouse data directly without ETL, enabling live subgraph retrieval, multi-hop reasoning, and seamless integration with text-based evidence. Explore the forever-free PuppyGraph Developer Edition or book a demo to see how it brings graph capabilities to life on your data for agents, LLMs, and developers alike.

Matt is a developer at heart with a passion for data, software architecture, and writing technical content. In the past, Matt worked at some of the largest finance and insurance companies in Canada before pivoting to working for fast-growing startups.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install