

What Is Graph AI? How Does It Work?
Artificial intelligence has traditionally focused on processing independent data points, such as images, text, or numerical features. However, real-world systems are rarely isolated. People interact with other people, documents reference other documents, transactions connect accounts, and biological entities influence each other in complex networks. These relationships form structures that cannot be fully understood through conventional machine learning approaches.
Graph AI emerges as a response to this challenge. Instead of treating data as isolated records, Graph AI models the world as interconnected entities and relationships. By combining graph-based data representations with advanced AI techniques, it enables machines to reason about structure, context, and dependencies in ways that were previously difficult or impossible.
Today, Graph AI is becoming a foundational paradigm in modern AI systems. It integrates graph neural networks, graph-enhanced retrieval, graph databases, and large language models into a unified framework for reasoning over relationships. From recommendation systems and fraud detection to knowledge discovery and AI agents, Graph AI is reshaping how intelligent systems understand complex environments.
What is Graph AI?
Graph AI can be defined as a set of techniques that apply artificial intelligence to graph-structured data. Graph AI models entities as nodes and relationships as edges, allowing AI systems to capture structural and relational information.
At its core, Graph AI is not a single algorithm or model. It is an ecosystem of methods that operate on graphs to support reasoning, learning, and retrieval. Among these techniques, two representative approaches stand out as fundamental: Graph Neural Networks (GNNs) and Graph Retrieval-Augmented Generation (GraphRAG). GNNs focus on machine learning directly on graphs, while GraphRAG enhances generative AI and information retrieval using graph structures.
Beyond these two, Graph AI also includes graph algorithms, graph embeddings, knowledge graphs, and graph-based workflows. Together, these approaches enable AI systems to integrate symbolic knowledge with statistical learning, bridging the gap between structured reasoning and data-driven intelligence.
How Graph AI Works
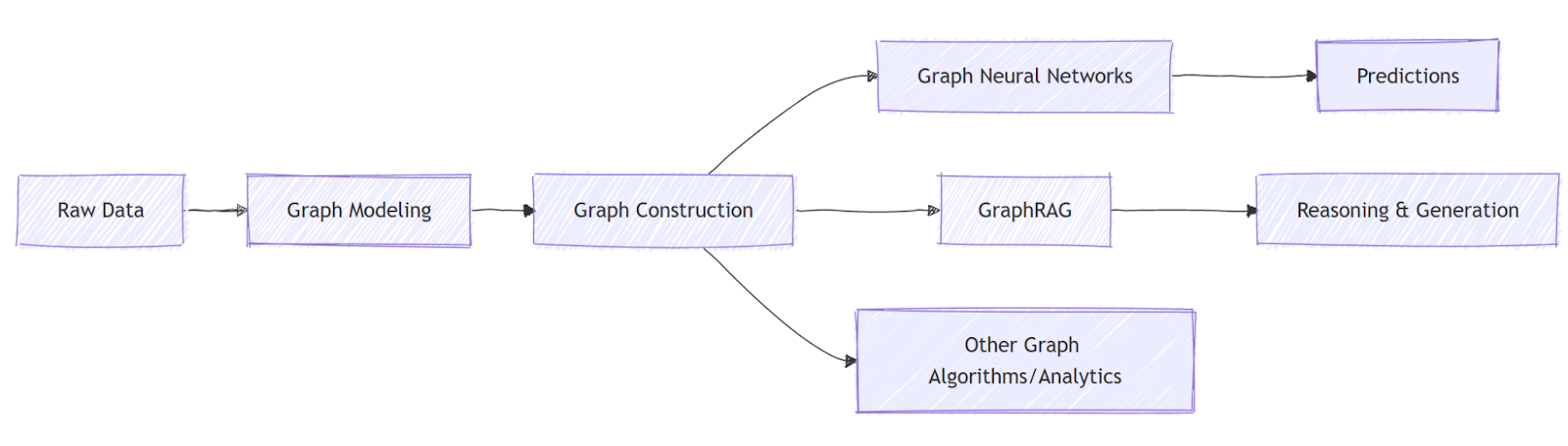
Graph AI operates through a multi-layered workflow that integrates graph modeling, graph computation, and AI-driven reasoning. The process begins with transforming raw data into a graph structure, where entities become nodes and relationships become edges. This graph can represent diverse domains, such as social networks, knowledge bases, transaction systems, or biological interactions.
Once a graph is constructed, different Graph AI techniques can be applied depending on the task. GNNs learn representations of nodes, edges, and entire graphs by propagating information across connections. GraphRAG, in contrast, retrieves relevant subgraphs or paths to augment large language models with structured knowledge. Other graph algorithms/analytics, such as label propagation, PageRank, or community detection, can be used either independently or in combination with learning-based methods to provide explicit structural insights.
Together, these techniques form a layered and modular workflow in which graph data supports both predictive and generative intelligence. Graph databases store and query relationships efficiently, while AI models extract patterns and generate insights from graph structures. This synergy enables Graph AI systems to reason about relationships rather than merely processing isolated data points.
In practice, Graph AI systems are iterative. Graph structures evolve as new data arrives, and AI models continuously refine their understanding of relationships. This dynamic nature makes Graph AI particularly suitable for complex, real-world environments where relationships are constantly changing.
Key Technologies Behind Graph AI
Graph AI is built on a technology stack that aligns with its workflow from data to reasoning. The first step is graph storage, which can take different forms depending on system requirements. In scenarios where relationship queries and traversal efficiency are critical, graph databases are used to store and manage graph structures directly. When data volume is large or highly heterogeneous, raw data is often stored in data lakes.
Graph modeling and construction define how raw data is transformed into nodes, edges, and attributes. Depending on the underlying graph storage architecture, graph data can be obtained directly from graph databases, or raw data can first be ingested from data lakes and then converted into graph structures using graph databases. Apache Spark supports graph analytics through libraries such as GraphX, which model graphs on top of distributed datasets and execute graph algorithms within Spark’s batch-oriented dataflow framework, rather than serving as dedicated graph engines.
On constructed graphs, Graph AI can apply graph learning methods, with GNNs as a representative approach. GNNs learn representations by propagating information across graph structures, enabling tasks such as node classification, link prediction, and graph embedding. Alongside GNNs, Graph AI also leverages other graph algorithms/analytics. Techniques such as PageRank, label propagation, and community detection uncover structural patterns and relational properties of graphs, providing interpretable insights into connectivity, influence, and group structures.
GraphRAG extends Graph AI from representation learning to explicit relational reasoning by using graphs as the primary retrieval and context modeling mechanism. For a user’s natural language query, the GraphRAG system first analyzes the information required to answer the question and generates a corresponding graph query. This query is then executed over the underlying knowledge graph to retrieve relevant subgraphs, entities, relationships, and aggregation information. The system combines these structured results with any additional computations or aggregations needed, creating a rich, context-aware representation. Finally, the retrieved graph-based context is fed back into the agent of the GraphRAG system. The GraphRAG system performs multi-hop reasoning, infer dependencies, and generate accurate, well-grounded responses that reflect both textual knowledge and relational structure
Together, these technologies form a hybrid Graph AI architecture in which storage, modeling, algorithms, and AI models work in coordination.
Graph Neural Networks Explained
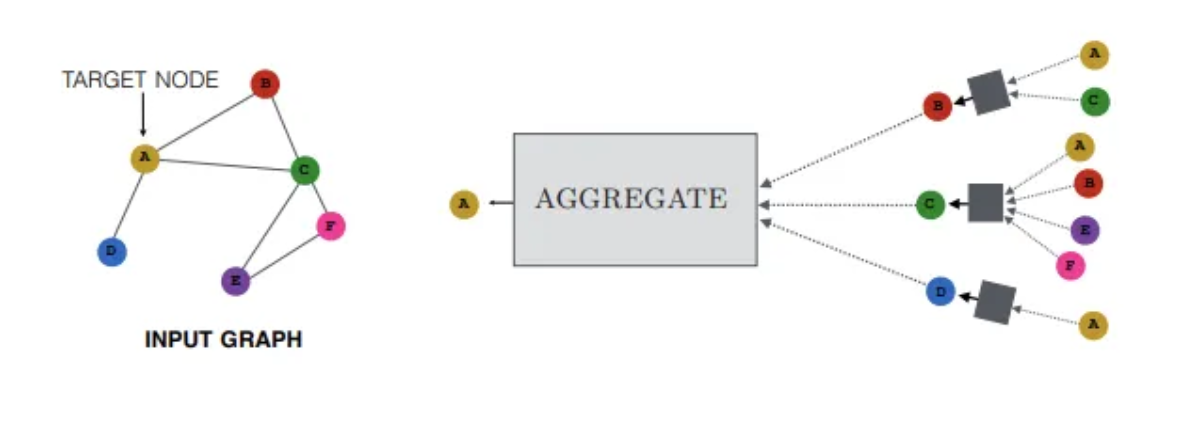
Graph Neural Networks (GNNs) represent one of the most important techniques in Graph AI. Unlike traditional neural networks, which operate on fixed-size vectors or grids, GNNs are designed to process graph-structured data. They achieve this by iteratively aggregating information from neighboring nodes, allowing each node to learn from its local and global context.
The fundamental idea behind GNNs is message passing. Each node receives messages from its neighbors, aggregates them, and updates its representation. Over multiple layers, information propagates across the graph, enabling nodes to capture multi-hop relationships. This mechanism allows GNNs to model complex dependencies that are difficult to represent using traditional machine learning approaches.
GNNs are widely used in tasks such as node classification, link prediction, and graph-level prediction. In social networks, they can identify influential users or predict new connections. In chemistry, they model molecular structures to predict chemical properties. In knowledge graphs, they infer missing relationships and enhance semantic understanding.
One of the key strengths of GNNs is their ability to integrate structural information with node attributes. This combination makes them particularly powerful in domains where relationships are as important as features. However, GNNs also face challenges such as scalability, over-smoothing, and interpretability, which continue to drive research in Graph AI.
Despite these challenges, GNNs remain a cornerstone of Graph AI, providing the machine learning foundation for graph-based intelligence.
Graph AI Use Cases Across Industries
Graph AI has found applications across a wide range of industries, where relationships and networks play a central role. In finance, Graph AI is used for fraud detection, risk analysis, and anti-money laundering. By modeling transactions as graphs, institutions can detect suspicious patterns that involve multiple accounts and complex interactions.
In e-commerce and media, Graph AI powers recommendation systems that understand user-item relationships beyond simple co-occurrence. GNNs identify latent communities and preferences, while GraphRAG enhances content discovery by connecting users to relevant knowledge and products through structured relationships.
In healthcare and life sciences, Graph AI models biological networks, such as protein interactions and gene regulatory networks. GNNs predict drug interactions and disease pathways, while knowledge graphs integrate clinical data, research literature, and patient records. This integration enables more accurate diagnostics and personalized treatments.
In enterprise knowledge management, GraphRAG plays a crucial role. Organizations build knowledge graphs that connect documents, entities, and concepts. Large language models then use graph-based retrieval to generate accurate and context-aware responses. This approach reduces hallucinations and improves explainability in AI-driven decision-making.
Across these domains, Graph AI acts as an enabler of relational intelligence. GNNs provide predictive capabilities on graph structures, while GraphRAG enables reasoning and knowledge integration. Beyond these approaches, other graph algorithms/analytics such as label propagation, PageRank, and community detection play a complementary role by uncovering influence, relevance, and structural patterns within networks. Together, they transform how organizations understand and operate complex systems.
Graph AI Tools and Platforms
Graph modeling forms the foundation of Graph AI. Graph databases such as Neo4j and Amazon Neptune are widely used to store and query relationship-centric data. Neo4j is commonly adopted for knowledge graphs and enterprise applications, with built-in graph algorithms for centrality, community detection, and path analysis. Amazon Neptune integrates tightly with the AWS ecosystem and is often applied in cloud-native knowledge graph and semantic workloads. In addition to graph databases, Apache Spark offers graph analytics libraries such as GraphX, which provide graph abstractions over RDDs and allow graph algorithms to be executed within Spark’s distributed data processing framework.
For GNNs, frameworks such as PyTorch Geometric (PyG), Deep Graph Library (DGL), and TensorFlow Graph Nets provide abstractions for message passing, graph convolution, and scalable training of GNNs. These tools are widely used for tasks such as node classification, link prediction, graph embedding, and anomaly detection, allowing models to capture both structural and semantic information embedded in graphs.
In GraphRAG architectures, graph databases and vector stores are combined with large language models (LLMs) to support structured retrieval and relational reasoning. Leading models such as GPT, Claude, and Gemini offer strong reasoning capabilities and are widely used in enterprise-grade GraphRAG systems. Open-source models such as DeepSeek, Qwen, and GLM provide flexible and cost-efficient alternatives, enabling customized graph-aware reasoning pipelines. Agent frameworks further orchestrate multi-step reasoning and tool usage over graph data. Systems such as LangGraph, LangChain, and AutoGen enable LLMs to interact with graph databases, execute queries, maintain memory, and coordinate complex workflows.
Unlocking GraphRAG with PuppyGraph
GraphRAG pipelines typically rely on a massive knowledge graph that captures entities and their multi-hop relationships. In practice, building and maintaining such a large graph with traditional graph databases introduces significant friction. Extracting and transforming data into a separate graph store, designing schemas upfront, and keeping the graph synchronized with constantly changing source data can be slow, fragile, and expensive. This makes real-time reasoning over relationships difficult and often limits the practical deployment of Graph AI applications.
PuppyGraph addresses these challenges by running directly on existing relational and lakehouse data. It provides real-time, zero-ETL graph querying, eliminating the need to duplicate data or maintain separate graph stores. Graph traversals and multi-hop relationships can be computed instantly, allowing LLMs and AI models to access up-to-date relational context without delays.
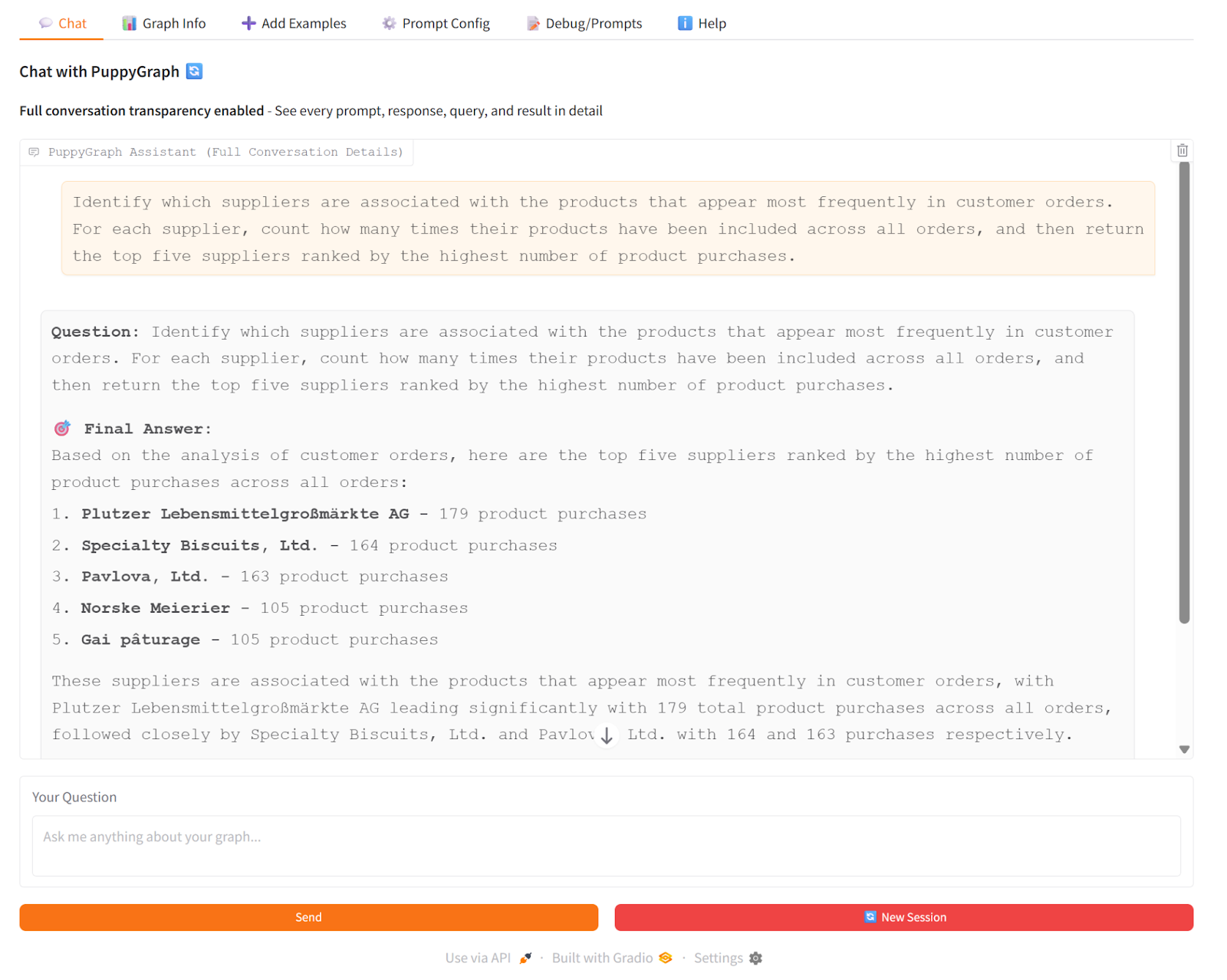
For example, in a GraphRAG workflow, a user might ask: “Which suppliers are associated with the products that appear most frequently in customer orders?” Using PuppyGraph, the system performs live graph traversal from products to suppliers, aggregates order counts, and returns grounded results. The AI model then combines these traversal results to generate a precise answer.
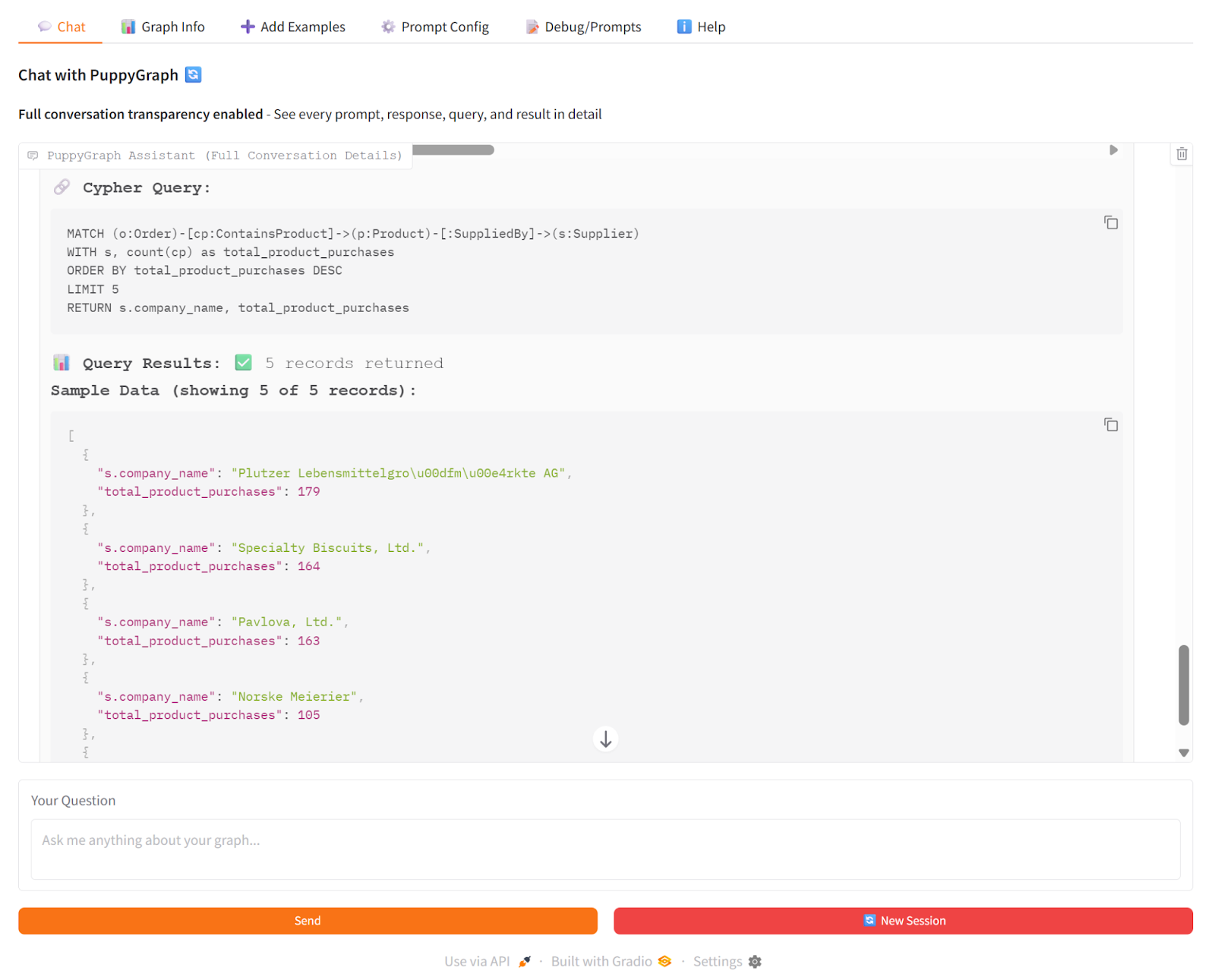
By removing ETL pipelines, enabling live querying, and supporting multi-hop reasoning, PuppyGraph makes GraphRAG, and more broadly, Graph AI applications, practical at enterprise scale. It allows organizations to leverage relational data as a graph without complex infrastructure, ensuring that AI reasoning is always grounded in the current state of the data.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Graph AI represents a paradigm shift in artificial intelligence, moving from isolated data processing to reasoning over complex relationships and structures. By leveraging graph-structured data, techniques like GNNs and GraphRAG enable AI systems to capture dependencies, perform multi-hop reasoning, and integrate relational context with predictive and generative models. Across industries, from finance and e-commerce to healthcare and enterprise knowledge management, Graph AI uncovers insights that traditional approaches cannot, supporting tasks such as fraud detection, recommendation, and knowledge retrieval.
PuppyGraph exemplifies the practical realization of Graph AI at scale, offering real-time, zero-ETL graph querying over existing relational and lakehouse data. By eliminating data duplication, enabling multi-hop traversal, and maintaining up-to-date context, PuppyGraph empowers organizations to deploy GraphRAG workflows and graph-based analytics efficiently. Together, Graph AI and PuppyGraph make relational intelligence actionable, allowing enterprises to reason over relationships and generate insights directly from the data that drives their operations.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install