

Hadoop vs Spark: key differences and comparison

Hadoop and Spark are the two names that come up first whenever a team starts moving work off a single machine and onto a cluster. They are often presented as competitors, as if choosing one rules out the other. That framing is misleading. Apache Hadoop is a full stack for storing and processing large datasets across commodity hardware, built around distributed storage and a disk-based batch processing model. Apache Spark is a distributed processing engine that keeps intermediate data in memory and is designed for speed on workloads that pass over the same data many times. They overlap in the processing layer, but Hadoop also owns a storage layer and a resource manager that Spark does not have, and Spark is frequently deployed on top of exactly those Hadoop components.
So the real question is rarely “Hadoop or Spark.” It is closer to “which processing model fits this workload, and which storage and scheduling layer sits underneath it.” This post walks through what each system actually is, the features that define them, a side-by-side comparison of the dimensions engineers tend to care about, and the situations where one is the clearer fit. The goal is a working mental model of where the two sit in a data platform, not a verdict that one always wins.
What is Hadoop?
Apache Hadoop is an open-source framework for distributed storage and batch processing of very large datasets across clusters of commodity servers. It grew out of Google’s GFS and MapReduce papers and became the foundation of the early big-data era. The design assumption is that hardware fails routinely, so the software handles replication and recovery rather than relying on expensive, reliable machines.
Hadoop is best understood as three core components working together. HDFS (Hadoop Distributed File System) is the storage layer. It splits large files into blocks, distributes them across nodes, and replicates each block (three copies by default) so a node failure does not lose data. MapReduce is the original processing model: a job is expressed as a map phase that transforms records in parallel and a reduce phase that aggregates the results, with intermediate output written to disk between stages. YARN (Yet Another Resource Negotiator) is the cluster resource manager that schedules jobs and allocates CPU and memory across the nodes, allowing engines other than MapReduce (including Spark) to run on the same cluster.
A note on what has aged. MapReduce as a programming model is now largely legacy: few teams write new jobs directly against its API, and engines that ran on it have moved on (Hive, for instance, shifted its default execution from MapReduce to Tez). What endured from Hadoop is the storage and scheduling layers. HDFS and YARN remain widely deployed, with faster engines such as Spark and Tez running on top. So Hadoop’s continued relevance rests less on MapReduce than on being the storage-and-scheduling base that other processing engines build on.
Key features
- Distributed, fault-tolerant storage. HDFS replicates data blocks across nodes, so the cluster keeps serving data through individual node failures without manual intervention.
- Linear scale-out on commodity hardware. Capacity grows by adding ordinary servers rather than upgrading to larger machines, which keeps the cost of storing very large datasets low.
- Disk-based batch processing. MapReduce streams data from disk, processes it, and writes back to disk. This makes memory requirements modest and lets a job process datasets far larger than the cluster’s combined RAM.
- Data locality. Computation is scheduled close to where the data already lives, reducing network transfer for large scans.
- A broad ecosystem. Hive (SQL over Hadoop), HBase (a NoSQL store), Pig, Oozie, and others grew up around HDFS and YARN, so Hadoop is a platform as much as a single tool.
The trade-off that defines Hadoop is durability and scale over speed. Writing intermediate results to disk between every stage is what makes MapReduce robust and memory-light, and it is also what makes it slow for workloads that read the same data repeatedly.
What is Spark?
Apache Spark is an open-source distributed processing engine built for speed and for a wider range of workloads than batch alone. Its foundational abstraction is the resilient distributed dataset (RDD), a fault-tolerant collection of records partitioned across the cluster that Spark can hold in memory. (Most code today is written against the higher-level DataFrame and Dataset APIs, which compile down to RDDs.) By keeping intermediate results in memory instead of writing them to disk between stages, Spark avoids the repeated I/O that dominates MapReduce on iterative work.
Crucially, Spark is a processing engine, not a storage system. It has no equivalent of HDFS. It reads from and writes to external storage: HDFS, Amazon S3, cloud object stores, Cassandra, relational databases, and others. It also does not require Hadoop’s MapReduce; it can run standalone, on YARN, or on Kubernetes. (Apache Mesos was a supported option in older versions but was deprecated in Spark 3.2 and removed in Spark 4.0.) This is why “Spark replaces Hadoop” is imprecise. Spark replaces the MapReduce processing model for many workloads, but it often still relies on HDFS for storage and YARN for scheduling.
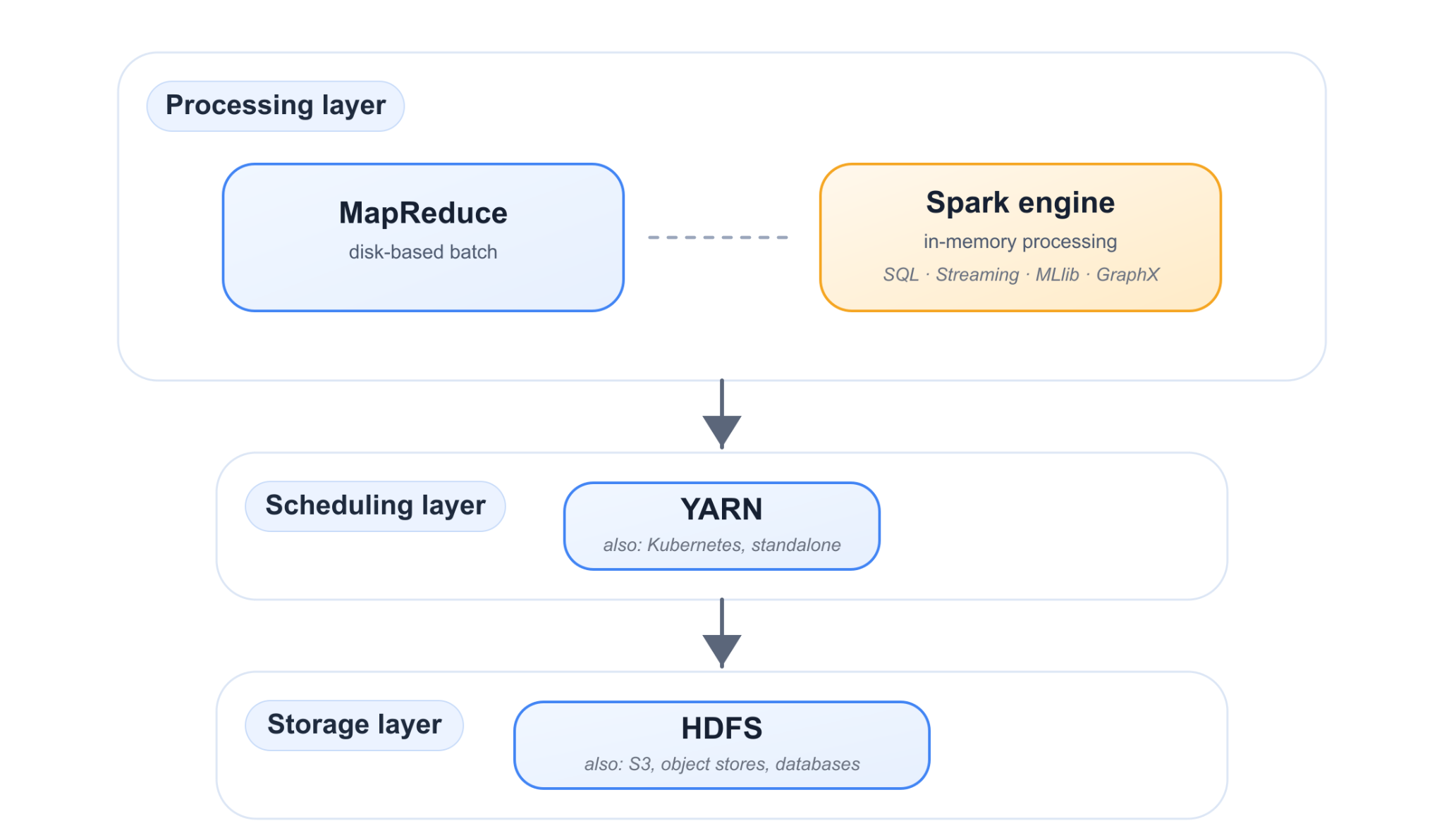
Spark unifies several workloads under one engine. Spark SQL runs SQL and structured queries over DataFrames. Spark Structured Streaming processes near-real-time data with the same API as batch. MLlib provides distributed machine learning. GraphX (and the DataFrame-based GraphFrames library) supports graph processing; GraphX is still labeled alpha and has no Python bindings, but it continues to ship with every Spark release. Running these on one engine means a pipeline can move between SQL, streaming, and ML without switching frameworks or recopying data.
Key features
- In-memory computation. Caching intermediate datasets in RAM removes the per-stage disk writes that slow MapReduce, which matters most for iterative algorithms and interactive queries.
- Fault tolerance through lineage. Rather than replicating data, Spark records the sequence of transformations that produced each RDD, so a lost partition can be recomputed from its inputs.
- A unified, high-level API. The same engine handles batch, SQL, streaming, machine learning, and graph workloads, with APIs in Scala, Java, Python (PySpark), and R.
- Lazy evaluation and a query optimizer. Transformations build a plan that executes only when an action requires a result. The Catalyst optimizer rewrites DataFrame and SQL queries before execution.
- Storage-agnostic. Spark connects to many sources, so it slots into an existing data platform rather than dictating where data must live.
The trade-off that defines Spark is speed and flexibility at the cost of higher memory demand. Holding working sets in RAM is what makes it fast, and it is also why a Spark cluster is typically provisioned with more memory, and costs more per node, than a Hadoop cluster sized for the same data.
Hadoop vs Spark: feature comparison
The two systems are easiest to compare when you separate what they each own. Hadoop spans storage, processing, and scheduling; Spark is a processing engine that borrows the other two layers from somewhere else. The table below lines up the dimensions engineers weigh when choosing.
One caveat on reading the table: the Hadoop column pairs MapReduce with HDFS and YARN because the classic “Hadoop vs Spark” comparison is really MapReduce vs Spark, the two systems’ native processing models. In a current deployment, though, the durable parts of that column are HDFS and YARN; MapReduce itself has largely been displaced by Spark and Tez. Read the Hadoop side as “the storage-and-scheduling base plus its original batch engine,” not as a claim that new processing still runs on MapReduce.
The comparison makes the relationship clearer than a winner does. Hadoop’s strengths are durable, cheap storage and a batch model that tolerates datasets larger than memory. Spark’s strengths are speed and a single API across batch, streaming, ML, and graph. The two failure modes are instructive: a Hadoop job rarely falls over, it just grinds slowly through disk; a Spark job is fast until the working set outgrows memory, at which point it spills to disk or fails outright. That difference, not raw throughput on a benchmark, is usually what shapes which one a team reaches for.
When to choose Hadoop vs Spark
Choose Hadoop when the workload is large-scale batch processing where latency is not the constraint. Nightly ETL over terabytes, log archival and processing, and jobs whose datasets dwarf the cluster’s RAM all suit MapReduce well. HDFS is also a reasonable answer to a separate question, “where does the data live,” even when Spark does the computing on top of it. If cost per terabyte of stored data matters more than time to result, Hadoop’s commodity-hardware, disk-based model is hard to beat.
Choose Spark when speed or workload variety drives the decision. Iterative algorithms (most machine learning training, graph traversal, optimization loops) pass over the same data repeatedly, and keeping that data in memory is exactly what Spark is built for. Interactive and ad-hoc analytics benefit from the same property. Near-real-time pipelines call for Structured Streaming. And a team that wants one engine for SQL, streaming, and ML rather than a separate tool per workload will find Spark’s unified API a real simplification.
In practice the two are often deployed together rather than chosen between. A common production shape is HDFS for storage, YARN for scheduling, and Spark as the processing engine running on top, with MapReduce reserved for the heaviest batch jobs that do not fit in memory economically. Reading the choice as strictly either/or misses how most real clusters are built.
Which one is right for you?
Start from the workload, not the brand. Ask three questions. First, how large is the working set relative to memory? If a single pass over data far larger than cluster RAM is the dominant job, MapReduce on Hadoop handles it without expensive memory provisioning. If the job iterates over a set that fits in memory, Spark will be much faster. Second, how sensitive is the result to latency? Batch reporting tolerates slow jobs; interactive analytics and streaming do not. Third, how varied are the workloads? A platform that needs SQL, streaming, ML, and graph processing is simpler on Spark’s one engine than on a patchwork of Hadoop-era tools.
Graph workloads deserve a specific note, because they are a frequent reason teams reach for Spark in the first place. Spark’s GraphX and GraphFrames let you run graph algorithms (PageRank, connected components, traversals) over distributed data, which is attractive when the graph is derived from data already sitting in the cluster. The cost is that you maintain a Spark pipeline to build and query the graph, and a multi-hop graph question becomes a series of joins or iterative jobs rather than a direct query.
That is the gap a graph query engine fills. PuppyGraph adds a graph layer over existing tables in a warehouse, lakehouse, or open table format such as Iceberg, and answers openCypher and Gremlin queries against them directly, with no ETL and no separate graph database to load. Where GraphX or GraphFrames expresses a multi-hop traversal as a series of joins or iterative jobs in a Spark pipeline you maintain, PuppyGraph runs the traversal in its own engine and reads only the columns it needs from the underlying tables. It is not a replacement for Spark’s batch or ML role; it is a more direct path for the specific case where the question is a graph question and the data already lives in tables. If your reason for considering Spark is mostly graph analytics, that case is worth evaluating on its own terms.
For everything else, the decision usually resolves cleanly: Hadoop for cheap, durable storage and very large batch jobs, Spark for speed, streaming, and mixed workloads, and very often both, with Spark computing over data that HDFS stores.
Conclusion
Hadoop and Spark solve overlapping but distinct problems. Hadoop is a storage-and-batch platform built for durability and scale on commodity hardware, with HDFS, MapReduce, and YARN as its pillars. Spark is an in-memory processing engine built for speed and for unifying batch, SQL, streaming, ML, and graph work under one API, while leaning on external systems for storage and scheduling. They compete only in the processing layer, and even there they more often cooperate, with Spark running on the storage and resource management Hadoop provides. Match the choice to the workload’s memory profile, latency tolerance, and variety, and the answer tends to follow directly.
Try the forever-free PuppyGraph Developer Edition and book a demo with the team to see how openCypher and Gremlin queries run over warehouse and lakehouse tables, with no graph-specific ETL, when the graph step would otherwise live in a Spark job.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install