

Knowledge Graph vs RAG: Know the Differences
.png)
Large Language Models (LLMs) can produce fluent answers that are still wrong. This largely comes down to how they are trained. They learn patterns from large, static corpora that quickly lose relevance, so they inherit what those datasets include and what they miss. At inference time, they do not look up your latest truth by default. They predict the next most likely token given the prompt. When there are gaps, the model often fills them with plausible-sounding text, which shows up as hallucinations.
That is the reliability problem Retrieval-Augmented Generation (RAG) aims to address. RAG is a pattern for supplying external context to an LLM at generation time. It retrieves relevant sources and includes them in the prompt so outputs are anchored to evidence. Many RAG systems use semantic search over documents in a vector database. GraphRAG builds on that foundation by adding a graph layer to recover relational context and reduce noise when the question depends on how entities connect.
That graph layer is a knowledge graph. Knowledge graphs serve as a way to organize connected information into a unified view that both humans and machines can use. While they weren’t built specifically for AI systems, their structured, relationship-first format makes them a strong fit for improving GenAI by retrieving context that’s actually connected to the question, not just “similar” in wording.
In this blog, we’ll define both approaches, compare how they improve accuracy and context, and show where each fits best. We’ll also look at modern ways to build knowledge graphs without standing up a separate graph database, such as PuppyGraph, a graph query engine that lets you model and query existing tables as a graph.
What is a Knowledge Graph?
A knowledge graph is a way to represent what your organization knows as a network of connected facts. It’s made up of three core building blocks:
- Nodes represent entities like users, devices, services, and orders.
- Edges represent relationships between entities like PURCHASED, DEPENDS_ON, or OWNS.
- Properties stores attributes as key-value pairs such as risk_score, created_at, or status. Both nodes and edges can have properties.
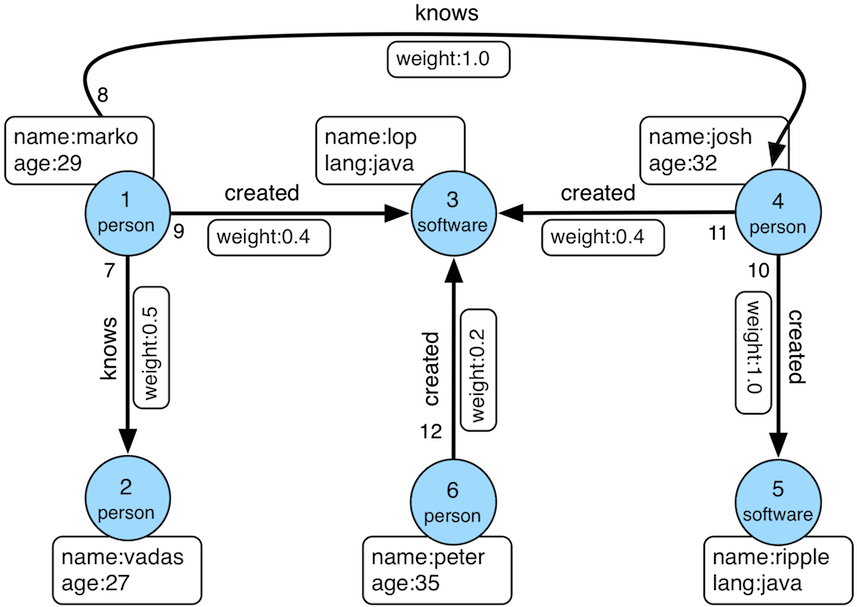
This mix of relationships plus attributes is what adds context. You can ask questions that go beyond simple lookups, like “which customers are two hops away from a churn signal?” or “which public-facing service can reach a sensitive database through misconfigured permissions?” Because relationships are first-class, graph queries can traverse many hops and return paths, neighborhoods, and dependency chains, which is often painful to express and maintain with repeated joins.
Knowledge graphs are also flexible. As your data changes, you can introduce new entity types, new relationships, or new properties without redesigning your entire model. As new records arrive, the graph can be updated incrementally, giving you a unified, current view of how your data connects.
Creating knowledge graphs start by mapping existing identifiers and relationships from structured sources like relational tables, event logs, and APIs into a graph model. They can also incorporate unstructured sources like documents, tickets, and webpages by extracting entities and relationships using NLP pipelines or LLMs, then linking those extractions back to nodes and edges in the graph.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is a pattern for grounding LLM outputs in external, up-to-date sources. Instead of retraining a model every time your data changes, you retrieve the most relevant context at query time and pass it into the prompt. This is often faster to iterate on, cheaper to operate, and easier to keep current than fine-tuning or full retraining.
Traditional RAG
Traditional RAG has two stages: retrieval and generation.
In the retrieval stage, the user’s query is converted into an embedding and compared against embeddings for documents (or document chunks) in your system. Using approximate nearest neighbor (ANN) search, the system pulls back the k most similar items and concatenates them into the prompt
In the generation stage, the LLM answers using this enriched prompt, ideally grounding its response in the retrieved sources rather than relying on whatever it “remembers” from training.
Although, it’s important to note that RAG still has its limitations:
- Similarity isn’t relevance: Embedding similarity can return text that matches the query’s wording, but still misses the user’s real intent.
- Vectors are isolated: They’re good at finding nearby text, but they don’t encode the relationships that connect entities across systems, so deeper context gets lost.
- Too much raw text: Traditional RAG often dumps large passages into the prompt, which adds noise and can push important details out of the LLM’s limited context window.
Knowledge Graph RAG
Knowledge Graph RAG, often called GraphRAG, adds a graph layer to the RAG pipeline so retrieval captures not just similar text, but also the relationships that connect the data behind that text. This is useful when the question requires joining context across systems, following dependencies, or reasoning over multi-hop chains. It shifts the focus from “Which document mentions X?” to “How does X relate to Y?”
One way to think about GraphRAG is a dual-channel retrieval setup:
- Text channel (traditional RAG): embed the query and retrieve the most similar passages from a vector index.
- Graph channel (knowledge graph): run entity linking to map query mentions to graph nodes, then pull relevant subgraphs, neighbor nodes, multi-hop relationships, and graph metadata.
These two channels run in parallel, and a context merger combines the results into a single prompt. The LLM gets documentary evidence (retrieved text) plus relational structure (subgraph context), which makes answers more grounded and easier to reason about than either channel alone.
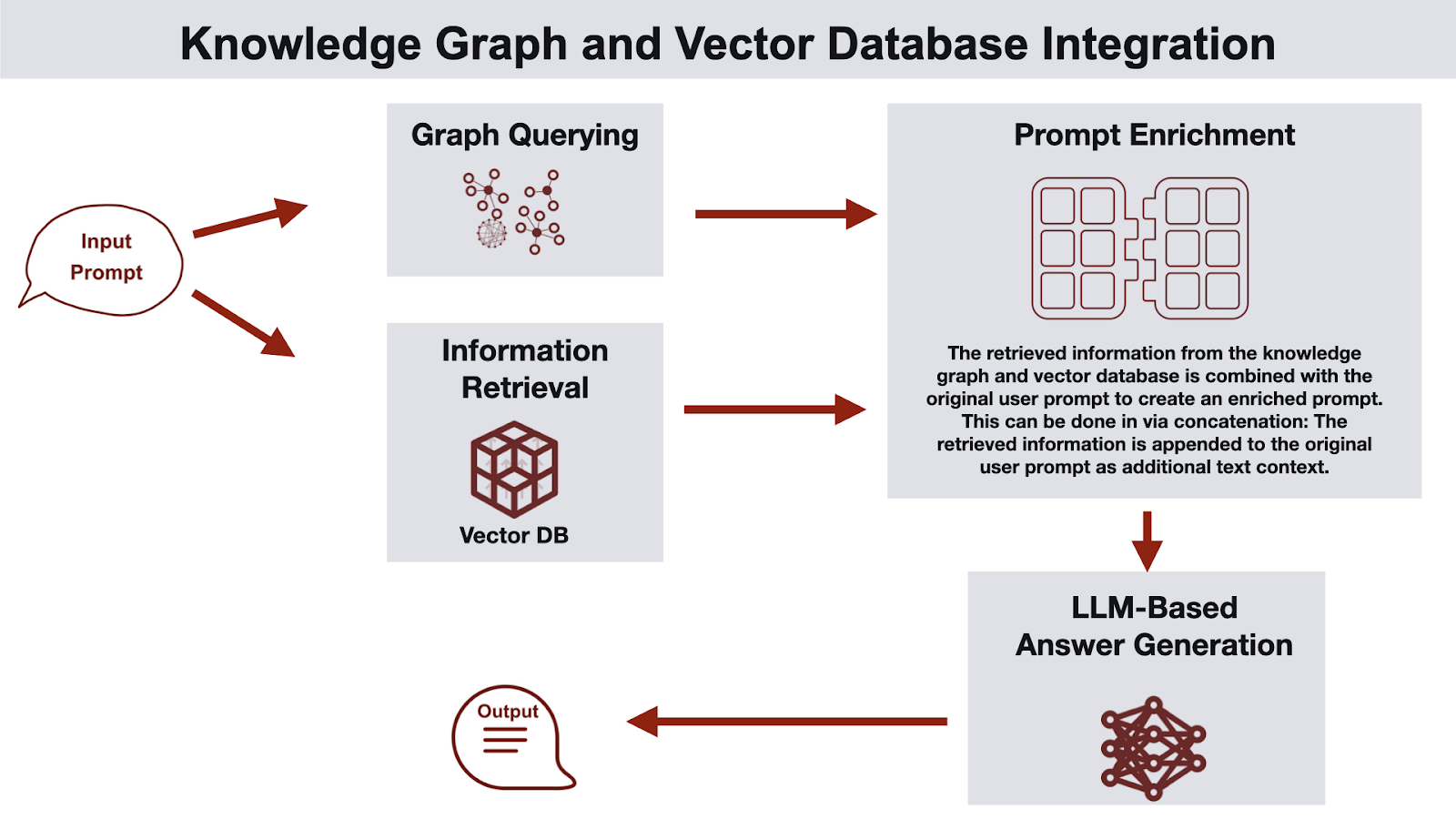
Graphs also offer a more compact representation of meaning. A small subgraph, or a set of graph-derived facts and paths, can capture key context with fewer tokens than long passages of text. This helps fit within the LLM’s context window while preserving the relationships that drive reasoning, like dependencies, ownership, access paths, and sequences of events.
How is a Knowledge Graph Different from RAG?
In this section, we compare knowledge graphs with traditional RAG. While both can ground LLM outputs, they do it in fundamentally different ways. That’s not to say that they’re mutually exclusive techniques. In practice, you can combine their strengths in GraphRAG.
Domain Model vs Prompt Context
A knowledge graph is a representation layer for your domain. It structures what your organization knows as entities and relationships, so both humans and machines can understand how things connect. The goal is to make knowledge navigable, queryable, and reusable across many applications.
RAG is a delivery pattern for LLMs. Its job is to retrieve external context at query time and inject it into the prompt so the model can answer with evidence, without retraining.
A simple way to remember it: knowledge graphs structure knowledge, RAG fetches and feeds knowledge to an LLM.
Structure-First vs Text-First Responses
Knowledge graphs typically return structure-first results: paths, neighborhoods, dependency chains, and subgraphs. Instead of just “what matches,” you can ask “how is X connected to Y?” and get back a traversable explanation, often with the exact relationships that justify the answer.
RAG returns text-first results: retrieved documents or chunks that look relevant to the query. The LLM then synthesizes a response from those passages, which works well for summarization, Q&A over documentation, and pulling facts from written sources.
Optimizing for Relationships vs Relevance
Knowledge graphs optimize for explicit context. They encode relationships directly, which makes multi-hop reasoning easier and keeps meaning consistent as you follow connections across systems.
RAG optimizes for fast relevance and grounding. It focuses on finding the most useful supporting context quickly and attaching it to the prompt, so the LLM can respond with fewer hallucinations and better coverage of domain-specific details.
Knowledge Graph vs Traditional RAG: Side-by-Side Comparison
Below is a side-by-side comparison of knowledge graphs and traditional RAG to make the differences easier to see at a glance.
A Brief History: Knowledge Graph and RAG
Knowledge graphs and RAG come from two very different origins. Here’s a brief timeline of how both approaches developed.
Knowledge Graphs
Knowledge graphs grew out of efforts to organize information so it’s understandable and usable by both humans and machines. In the late 1990s through the 2000s, Semantic Web research pushed this forward with standards like RDF for describing linked data and SPARQL for querying it with consistent semantics. The idea reached a broader audience in 2012, when Google popularized the term “Knowledge Graph” as a way to connect entities and improve search with richer context.
Around the same time, property graphs gained momentum in the late 2000s and early 2010s. Graph databases and more approachable query languages made it practical to model connected data in real production systems. This shifted knowledge graphs from a “web of linked data” concept into an everyday tool for problems where relationships are the point, not just retrieval. Common examples include master data management, Customer 360, governance and lineage, fraud detection, and security graphs, where teams need a living map of how entities, systems, and processes relate and change over time.
Today, newer tooling continues to lower the barrier for knowledge graph adoption. For example, graph query engines like PuppyGraph let teams model and query existing relational tables as a graph directly, without standing up a separate graph database or maintaining a second copy of the data.
Retrieval-Augmented Generation (RAG)
RAG was formalized in 2020 with the paper “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” by a team of researchers from Facebook AI Research, University College London, and New York University. The paper proposed a simple but important split. An external retriever fetches documents relevant to a query, then a generator produces an answer conditioned on those retrieved sources. This helped address two persistent weaknesses in LLMs: hallucinations and stale training data. Instead of relying on whatever the model absorbed during training, the system can pull in the specific evidence needed for the question and generate from that context.
This idea builds on decades of work in information retrieval. As transformers pushed language models forward, dense retrieval improved how systems could fetch relevant text using embeddings. Researchers started connecting the dots: retrieval can supply up-to-date knowledge, and generative models can turn that knowledge into fluent answers.
Since then, progress has focused less on the basic idea and more on making it work reliably in production: stronger retrieval and reranking, better chunking and indexing, improved evaluation, scaling to large corpora, and domain-specific pipelines. More recent work also extends RAG beyond plain text, using embedding models for modalities like images, videos, and audio.
Which is Best: Knowledge Graph or RAG?
Knowledge graphs and RAG are often framed as alternatives, but they solve different problems and operate at different layers.
When to Choose Knowledge Graphs
Knowledge graphs have a wider range of use cases because they’re a general-purpose way to organize connected information into a unified view that both humans and machines can use. They excel at:
- Integrating diverse sources: Combine data across systems without identical schemas.
- Unifying entities and definitions: Create shared meaning across teams while allowing definitions to evolve.
- Supporting discovery and multi-hop analytics: Make relationships explicit for traversal, impact analysis, and reasoning.
- Providing provenance and explainability: Trace facts back to sources and show paths that justify outputs.
Knowledge graphs also power use cases beyond AI. Customer 360 can trace user journeys to improve end-to-end experiences, while fraud and cybersecurity graphs help detect anomalous behavior and risky connections quickly.
When to Choose RAG
RAG is designed to improve LLM outputs by retrieving relevant, up-to-date information at query time, so models can use domain knowledge without costly fine-tuning or retraining. This makes it great for:
- Grounding responses in evidence: Reduces hallucinations by anchoring generation to retrieved sources.
- Keeping answers current: Incorporates fresh, domain-specific updates without retraining cycles.
- Unlocking unstructured knowledge: Makes documents, PDFs, emails, and chat logs searchable by converting them into embeddings for semantic retrieval.
- Fast time-to-value: Often quicker to deploy than building a full domain model, and easy to iterate on.
While knowledge graphs and RAG are often pitted against one another, they’re better viewed as complementary. Traditional RAG can struggle to connect the dots across related data points. In this case, techniques like GraphRAG add a knowledge graph layer to scope retrieval, add relational context, and filter out noise.
Unlocking Knowledge Graphs with PuppyGraph
We’ve discussed the value of knowledge graphs for enhancing RAG techniques and beyond, providing a unified graph view for reasoning over connected data. In practice, though, a knowledge graph is only as effective as the graph infrastructure behind it. Traditional graph databases often come with real friction: ETL into a separate store, upfront schema work, and ongoing maintenance to keep the graph in sync. That can slow deployments and add overhead before you see value.
This is where PuppyGraph stands out. PuppyGraph is a graph query engine that runs directly on your existing relational and lakehouse data, enabling real-time, zero-ETL graph querying without standing up a separate graph database.
As a concrete example, we’ll show how quickly you can enhance a RAG pipeline with a knowledge graph modeled directly from relational data using PuppyGraph.
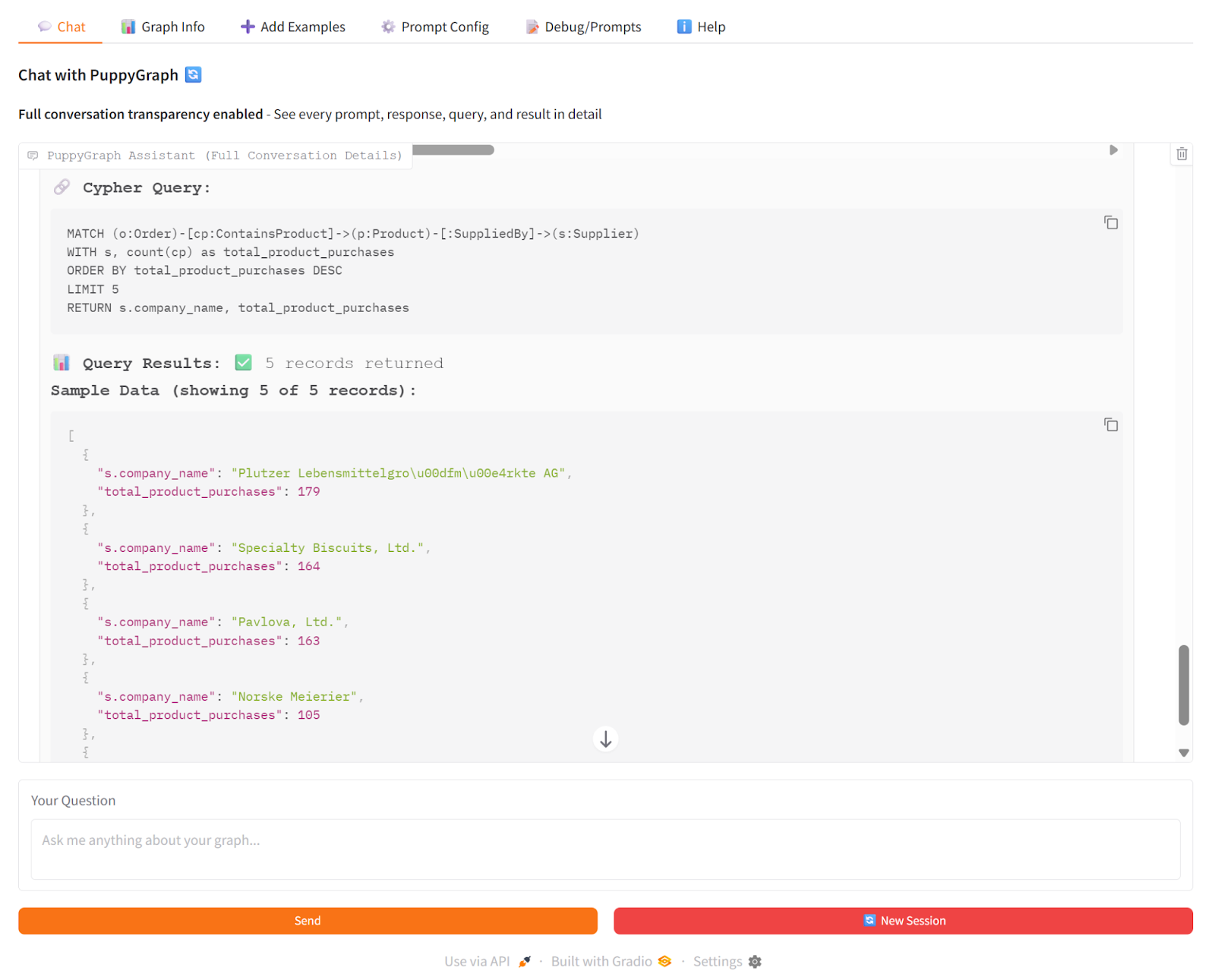
In our demo, we asked the PuppyGraph Chatbot: “Which suppliers are associated with the products that appear most frequently in customer orders?” The chatbot used vector search to enhance the generation of Cypher queries. Then, it used PuppyGraph to traverse the knowledge graph in real time, following connections from products to suppliers and counting orders along the way. The LLM then combined the generated Cypher results to produce a clear answer with the top suppliers, the products driving those orders, and the total order counts.
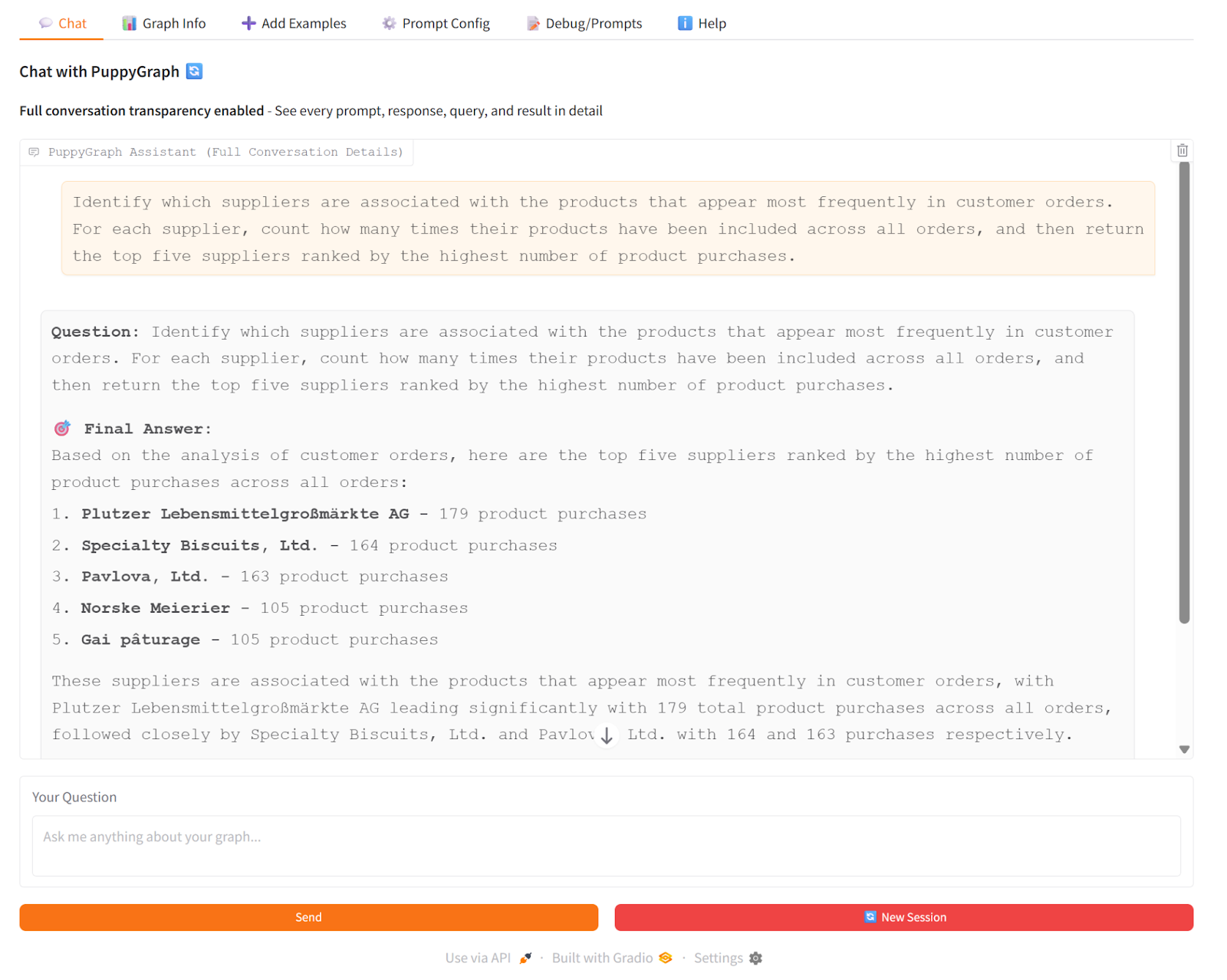
This shows how GraphRAG works: PuppyGraph provides the actual graph traversal and multi-hop relationships, so the chatbot’s answers are grounded in real connections rather than just inferred from text.
What is PuppyGraph

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.


Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
In this blog, we explored what knowledge graphs and RAG are, and how they come together in GraphRAG to enable more context-aware retrieval for AI systems. GraphRAG is just one use case among many that knowledge graphs support, since a knowledge graph provides a unified view of a company’s data for reasoning and analysis across systems.
If you’re interested in putting knowledge graphs to work, PuppyGraph makes adoption easier by letting you model and query your existing relational and lakehouse tables as a graph in real time. That makes it faster to experiment with GraphRAG and other graph-powered workloads without the usual ETL and data duplication.
Download PuppyGraph’s forever-free Developer Edition, or book a demo with the team to see how you can get started with knowledge graphs on your own data.

Jaz Ku is a Solution Architect with a background in Computer Science and an interest in technical writing. She earned her Bachelor's degree from the University of San Francisco, where she did research involving Rust’s compiler infrastructure. Jaz enjoys the challenge of explaining complex ideas in a clear and straightforward way.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install