

Knowledge Graph vs Vector Database: Key Differences
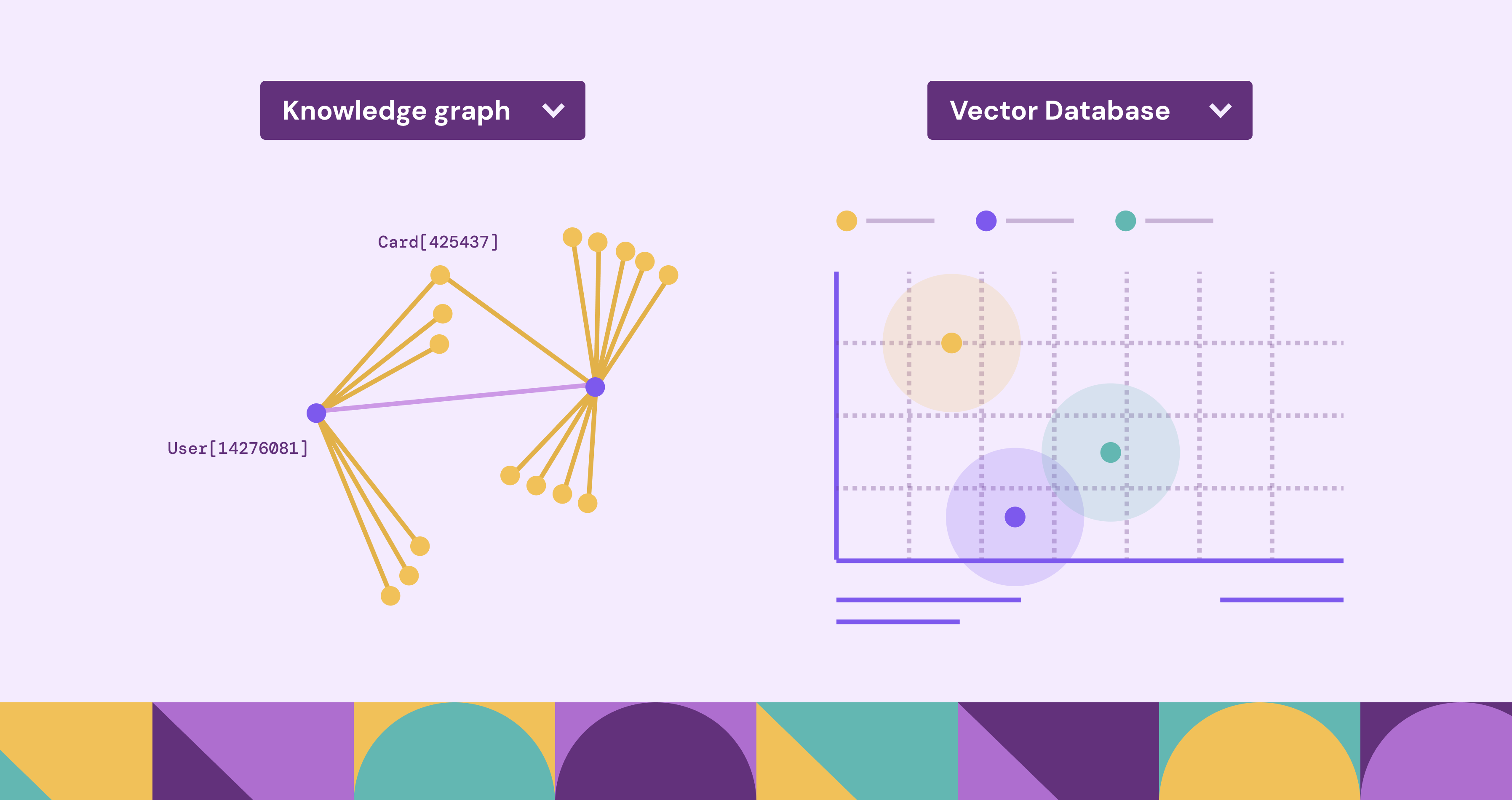
Teams today have a wider range of data needs than they used to. It’s not just transactions and dashboards anymore. The same organization might need dependency analysis across systems, semantic search across documents, recommendations, identity resolution, and fast retrieval that still respects context and constraints. As those needs expanded, the data stack evolved to support them.
Knowledge graphs and vector databases are two such technologies. Knowledge graphs represent entities and relationships explicitly, which supports structured facts, multi-step questions, and explainable answers about how things connect. Vector databases store embeddings, enabling fast similarity search where close matches matter more than exact ones, especially across unstructured data like text and images.
In this blog, we’ll define both technologies, compare how they differ, and map them to the workloads they fit best. We’ll also look at modern alternatives for building knowledge graphs without standing up a separate graph database, such as PuppyGraph, a graph query engine that lets you model and query existing tables as a graph.
What is a Knowledge Graph
A knowledge graph is a structured way to represent knowledge by organizing entities, their attributes, and the relationships between them into a formal graph model. Unlike unstructured data or loosely connected information, it imposes a clear schema, allowing facts to be systematically stored, linked, and queried. Nodes represent entities or concepts, while edges capture well-defined relationships such as works for, is part of, or depends on, providing context and enabling reasoning beyond isolated data points.
Modeling Knowledge Graphs
There are two common ways to model knowledge graphs: property graphs and RDF.
A property graph is a labeled, directed graph model designed to represent entities and their relationships using key-value pairs called properties. Both nodes and edges can carry properties, so you can attach attributes like timestamps, confidence scores, or status directly to an entity or a relationship. Property graphs are commonly queried using graph traversal and pattern-matching languages such as Gremlin and Cypher.
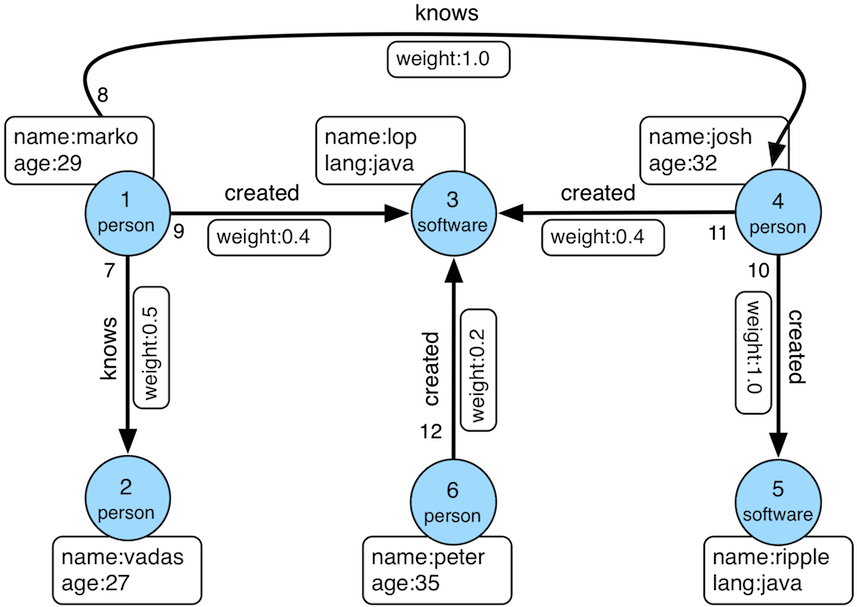
RDF is the abbreviation for Resource Description Framework, a W3C standard for data exchange on the Web. Oftentimes, RDF is used to refer to its underlying data model, such as the RDF graph data model. Under this framework, information is represented as triples, consisting of a subject, a predicate, and an object. Each triple is a statement, and an RDF graph is a collection of these statements linked together. RDF graphs are most commonly queried with SPARQL, which is designed around matching triple patterns.
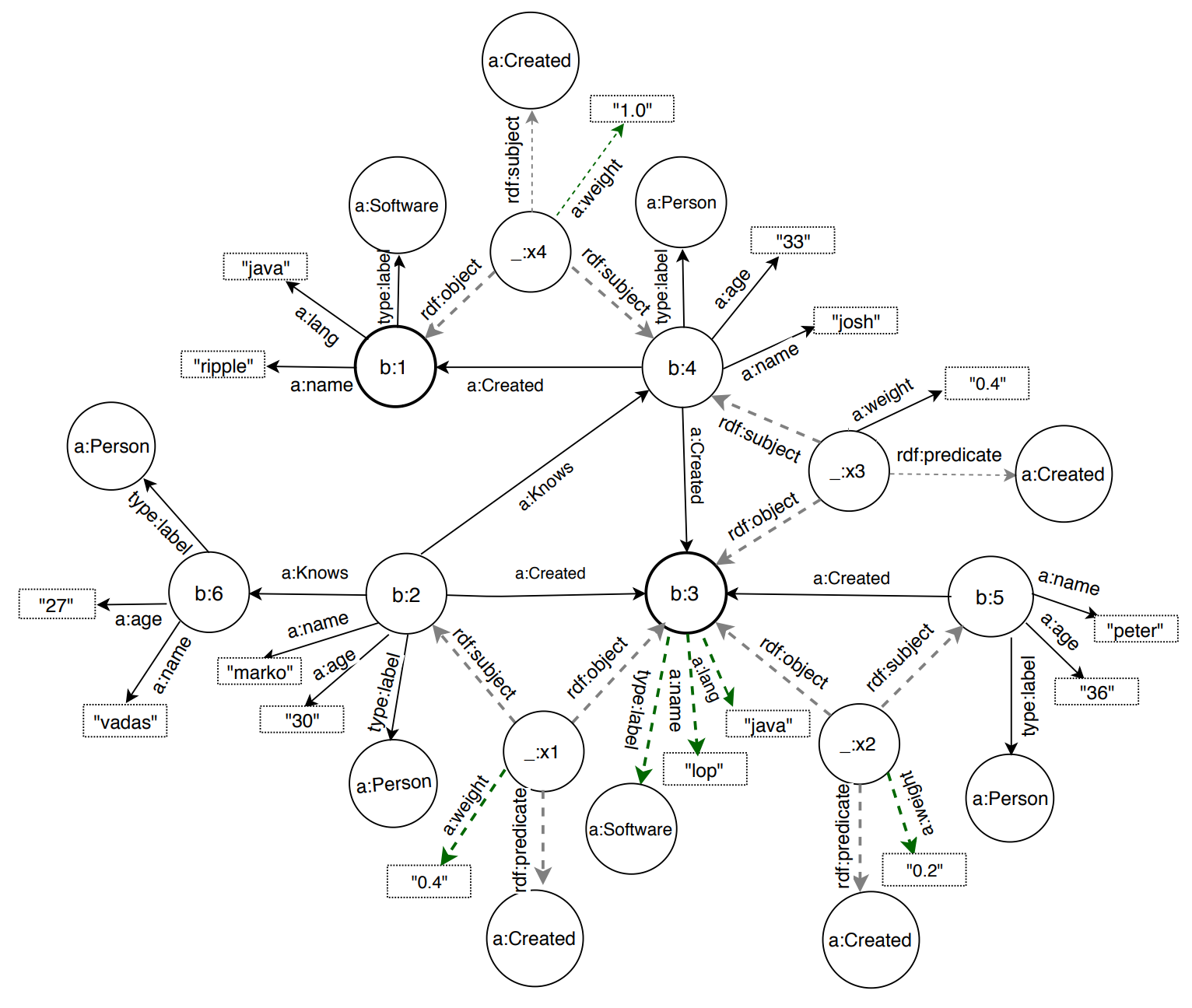
Choosing the right graph model affects ease of setup, how you query the graph, and how the system behaves as the graph grows.
RDF is sometimes treated as the default framework for knowledge graphs because of its association with W3C standards and formal semantics. It’s a strong fit when you need rich ontologies and logical inference. At the same time, many teams choose property graphs for simpler modeling and direct querying over entity and relationship properties using Gremlin or Cypher. RDF graphs can also be harder to scale for large analytical workloads, and retrieval latency may increase as the knowledge base grows.
What is a Vector Database
Before we define a vector database, it helps to understand what vector embeddings are and why they matter.
Vector Embedding
A vector embedding is simply an array of floating-point numbers that describes a piece of data in a way a machine can compare. The exact values are not universal. They depend on the embedding model you choose, since each model learns its own representation of meaning from the data it was trained on.
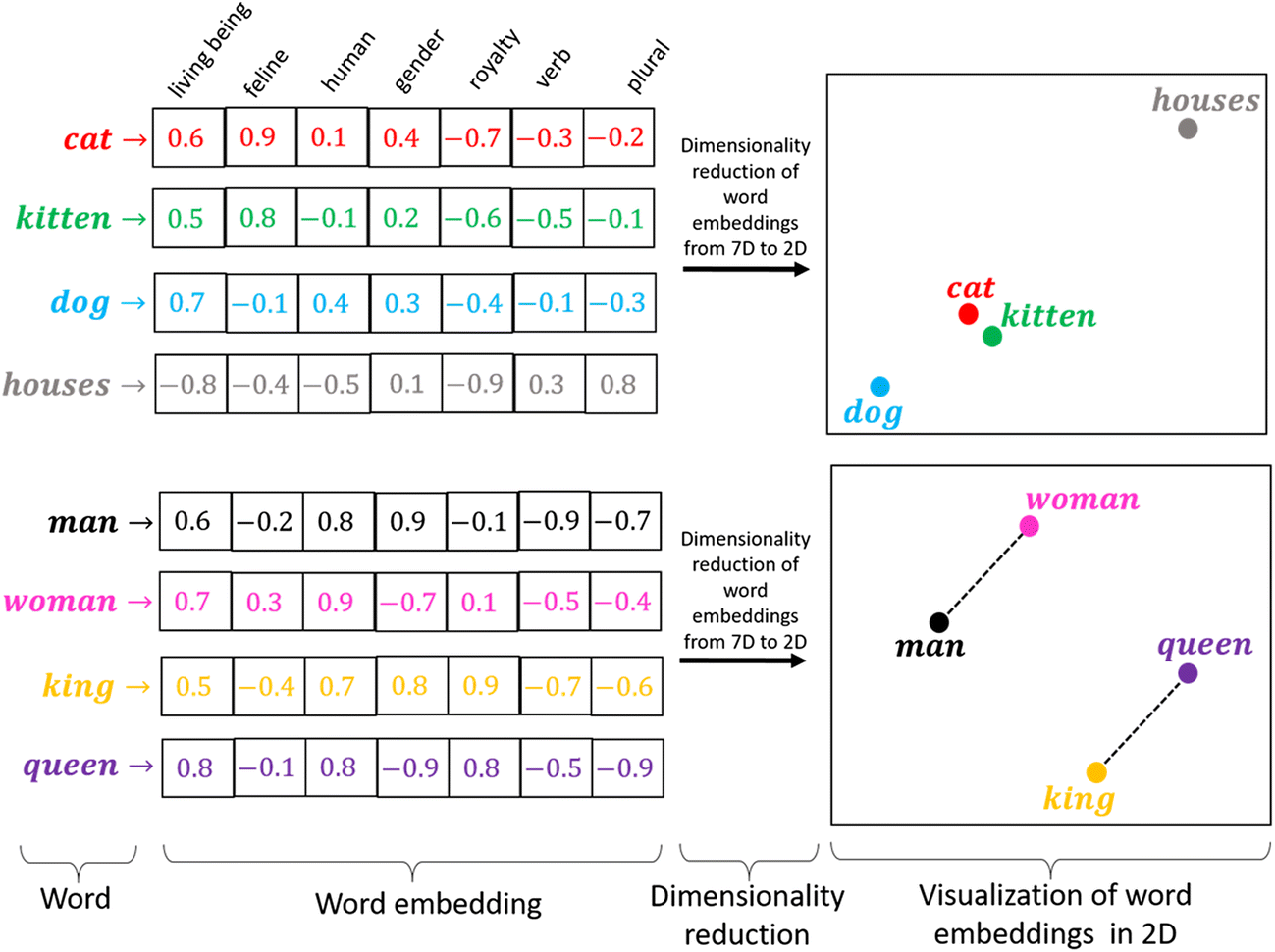
The key idea is that items with similar meaning or content tend to produce similar vectors, which places them near each other in vector space. That’s why vector search works: instead of matching exact keywords or fields, you retrieve the items whose embeddings are closest to your query’s embedding.
Vector Databases for Embedding-Based Retrieval
A vector database stores and indexes vector embeddings so you can retrieve similar items quickly at scale. In practice, raw content is usually split into chunks, and each chunk is stored alongside its embedding (plus identifiers and metadata). At query time, the database finds the nearest embeddings, then returns the corresponding chunks as the results.
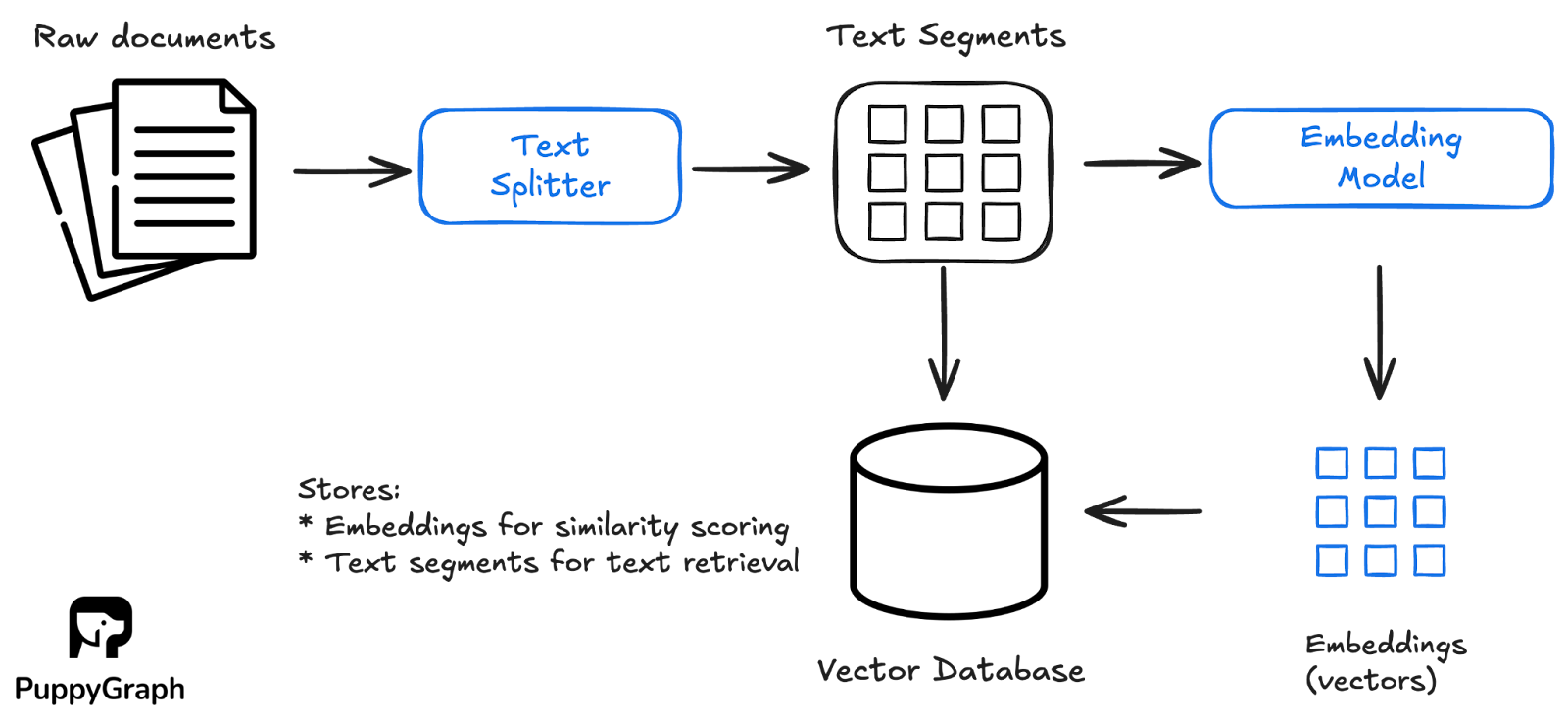
While relational databases can support vectors through extensions like PostgreSQL’s pgvector, dedicated vector databases become more important as you scale and need higher throughput, lower latency, as well as built-in tooling for managing vector workloads, including indexing, updates, filtering, and monitoring.
To make similarity search fast, vector databases rely on specialized indexing and compression techniques such as Hierarchical Navigable Small World (HNSW), Inverted File Index (IVF), and Product Quantization (PQ). Rather than querying for exact matches or predefined field values, they run nearest-neighbor search to return the closest vectors under a chosen distance metric. In practice, most systems use Approximate Nearest Neighbor (ANN) algorithms, trading a small amount of accuracy for much lower latency at scale.
They’re especially useful for unstructured data because embeddings can be generated from many modalities. Text, image, video, and audio embedding models convert raw content into compact, fixed-length vectors that capture key features, so you can retrieve similar items directly from the content itself, without relying only on manually written descriptions or tags.
How are Knowledge Graphs Different from Vector Databases
Knowledge graphs and vector databases both help you retrieve relevant information, but they do it in fundamentally different ways. Let’s take a look at how knowledge graphs differ from vector databases.
Core Purpose
Knowledge graphs are built to capture context. By storing entities and the relationships between them explicitly, they preserve the “why” behind the data, not just the data itself. This makes them well-suited for reasoning about how entities connect, tracing dependencies across multiple hops, and explaining outcomes with the actual paths and relationships that led to them. Results are often interpretable because the context is encoded directly in the graph structure.
Vector databases are built to represent similarity. They store embeddings and retrieve items based on proximity in vector space, which makes them well-suited for semantic retrieval, clustering, and recommendations. Instead of relying on explicit relationships, they rely on learned representations where similar content tends to map to similar vectors.
Data Sources and Representation
A knowledge graph represents data as nodes and edges, along with properties and sometimes a schema or ontology. They can be built from structured sources like relational tables, event logs, and APIs by mapping existing identifiers and relationships into a graph model. They can also be built from unstructured sources like documents, tickets, and webpages by extracting entities and relationships using NLP pipelines or LLMs, then mapping those extractions back to nodes and edges in the graph.
Vector databases represent information as embeddings, which are high-dimensional arrays of floating-point numbers produced by an embedding model. These vectors are often generated from unstructured or semi-structured content such as text, images, audio, and video, but they can also be generated from structured records like product catalogs or user profiles. Alongside vectors, vector databases typically store metadata for filtering, access control, and provenance.
Query Patterns
Knowledge graphs are queried through graph traversals and pattern matching. You start from one or more entities, then follow relationships across one or many hops, often with constraints on node or edge properties. Common query patterns include path finding, neighborhood expansion, subgraph matching, and dependency analysis. These queries are typically expressed in languages like Cypher or Gremlin for property graphs, and SPARQL for RDF graphs.
Vector databases are queried through top-k nearest-neighbor search. The query is embedded into a vector, then the system retrieves the k vectors closest to it under a distance metric. To keep this fast at scale, most systems use approximate nearest neighbor search with specialized indexes, and apply optional metadata filters to narrow results. The output is a ranked list of items with similarity scores, alongside their associated metadata.
Knowledge Graph vs Vector Database: Side-by-Side Comparison
Understanding how knowledge graphs and vector databases work helps you choose the right tool for your use case. The comparison below summarizes the key distinctions between the two.
A Brief History: Knowledge Graph and Vector Database
Both started as answers to the same basic challenge: making growing piles of information searchable in a way that preserves meaning. In this section, we’ll trace what each technology was originally built to solve, and how they moved from niche ideas to widely adopted tools.
Knowledge Graphs
Knowledge graphs grew out of efforts to organize information so it’s understandable and usable by both humans and machines. Semantic Web work in the late 1990s and 2000s pushed standards like RDF and SPARQL for representing linked data with formal semantics and querying it consistently. The idea became mainstream in 2012, when Google popularized the term “Knowledge Graph” as a way to connect entities and improve search results with richer context.
In parallel, property graphs took off in the late 2000s and early 2010s, as graph databases and developer-friendly query languages made graph modeling practical for production workloads. That made them a natural fit for use cases like master data management, customer 360, governance and lineage, fraud graphs, and security graphs, where the goal extends beyond just retrieval, but also maintaining a living map of how entities, systems, and processes relate.
Today, newer tooling is making knowledge graphs even more accessible. For example, graph query engines like PuppyGraph let teams model and query relational tables as a graph directly, without standing up and maintaining a separate graph database or duplicating data.
Vector Databases
Vector search has deep roots in information retrieval, but the modern vector database wave is powered by dense embeddings and efficient, scalable nearest-neighbor search. Word embedding models like word2vec helped popularize the idea that vectors can capture semantic similarity and relationships. This is also where the well-known analogy king − man + woman ≈ queen comes from, showing how related concepts can be reflected through distances and directions in vector space.
On the systems side, the 2010s brought major advances in approximate search and compression. Product Quantization (PQ) was introduced as a practical way to compress vectors and speed up nearest-neighbor retrieval at scale. Hierarchical Navigable Small World (HNSW) followed as a high-performance graph-based approach to approximate nearest-neighbor search. Then Facebook AI Similarity Search (Faiss) helped bring these techniques into production by providing a well-engineered library for similarity search and clustering, making large-scale vector retrieval much easier to adopt in real systems.
From there, dedicated vector databases emerged to operationalize embeddings end-to-end, covering ingestion, indexing, filtering, updates, and monitoring. Interest accelerated further once embedding-based retrieval became a common foundation for semantic search and modern LLM-based applications.
Which is Best: Knowledge Graph or Vector Database
There isn’t a single best choice between a knowledge graph and a vector database. They solve different problems, and their strengths show up in different workloads.
When To Choose Knowledge Graphs
Knowledge graphs are a strong fit when the value comes from explicit relationships and reasoning over connections, such as:
- Dependency and impact analysis: trace upstream and downstream relationships to see what changes, breaks, or is affected when an entity changes
- Graph pattern matching: explore neighborhoods, k-hop expansions, and relationship chains where the path itself is the answer
- Clustering and community analysis: identify communities and segments based on connectivity patterns
- Graph anomaly detection: flag unusual structures like unexpected bridges, new privileged paths, sudden neighborhood growth, or abnormal connectivity
When To Choose Vector Databases
Vector databases shine when you need semantic similarity at scale, especially over unstructured or high-variance content, such as:
- Semantic search over documents: retrieving relevant passages even without keyword overlap
- Recommendation engines: finding similar products, tickets, or content
- Clustering and deduplication: grouping near-duplicates or finding repeated patterns
- Multimodal retrieval: searching across text, images, audio, or video using embeddings
Why Not Both
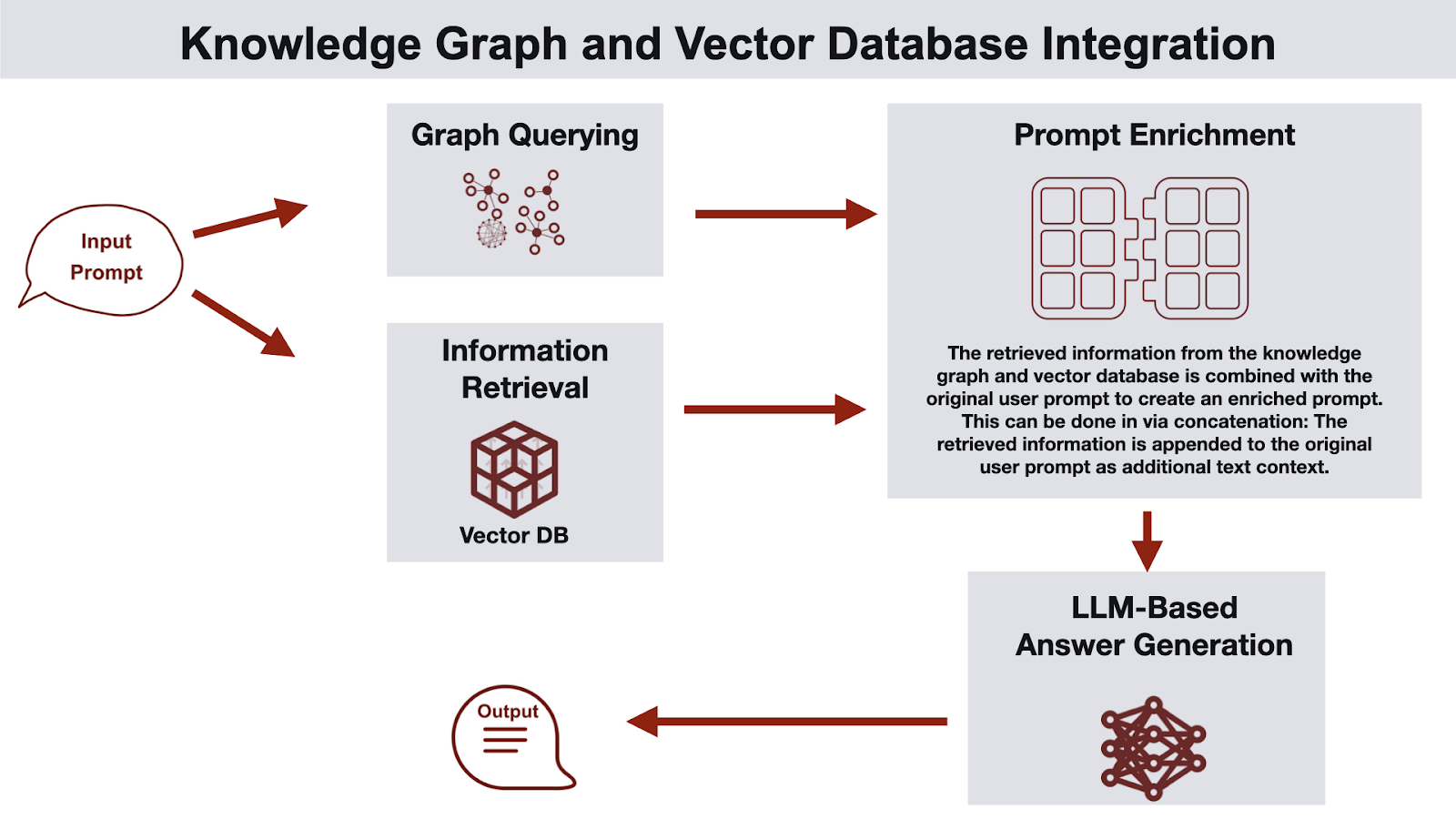
These approaches aren’t mutually exclusive. In many systems, combining them gives better results than either one alone. A common pattern is GraphRAG: the knowledge graph provides structure and constraints by identifying the entities and subgraphs that matter for a question, and the vector database retrieves the most relevant documents or chunks within that scoped context. This reduces noise, improves retrieval quality, and makes the final results easier to explain.
Graph the Easy Way with PuppyGraph
Many organizations already have rich datasets stored in relational databases, which implicitly contain knowledge graph structures: entities, relationships, and dependencies that are just waiting to be explored. Traditionally, unlocking this graph-like knowledge would require complex ETL pipelines to move data into a separate graph system, often duplicating data, creating extra governance overhead, and slowing down queries through deep traversals.
PuppyGraph removes these barriers by allowing teams to directly expose existing relational or lakehouse data as a graph, with no ETL and no data duplication. Graph schemas are defined entirely through JSON files, requiring no structural changes to your source systems. This makes graph modeling lightweight and highly flexible: the same underlying data can support multiple graph models simply by defining different JSON schema files. As your data evolves, your graph models can evolve just as easily, enabling analysts to explore relationships and dependencies in real time while keeping a single source of truth.
On top of this foundation, PuppyGraph Chatbot implements a GraphRAG approach. One channel traverses the knowledge graph to identify paths and relationships, while a second channel queries a vector database to retrieve semantically similar example questions paired with Cypher queries, guiding the LLM to translate user requests into correct Cypher queries. Users can interact in natural language, and the system executes both channels to return results that are both structurally meaningful and contextually relevant, without requiring knowledge of Cypher or any additional ETL processes.
Demo: Using PuppyGraph Chatbot
This demo illustrates how PuppyGraph Chatbot implements a GraphRAG workflow. Suppose the user wants to understand a company’s management structure. The query might be:
“Show me the full management chain for Robert King, up to 5 layers.”
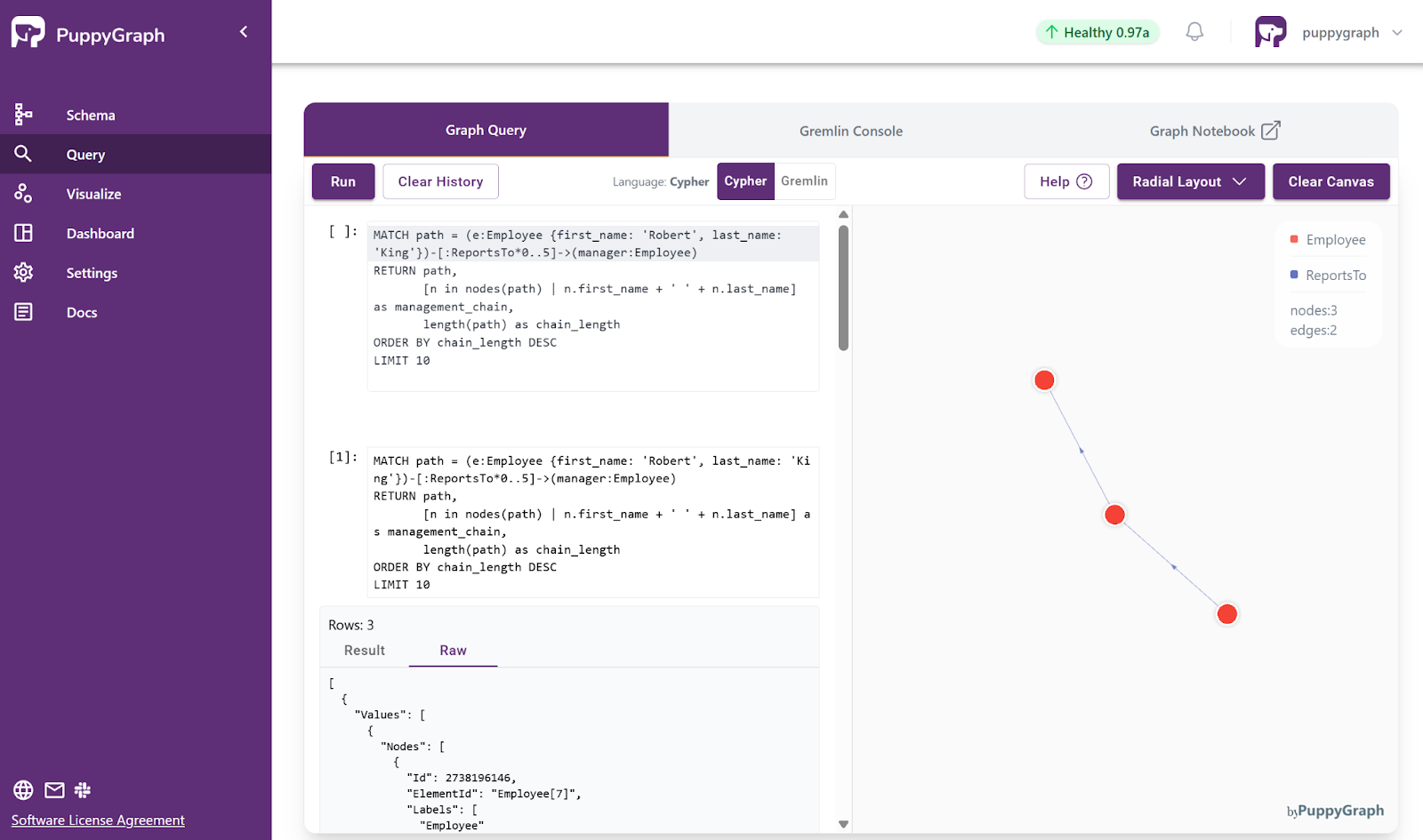
In PuppyGraph Chatbot, the user types the request in plain language and clicks Send.
- Graph Channel: The chatbot traverses the knowledge graph constructed by PuppyGraph, identifying the multi-hop path through ReportsTo relationships. This produces an explicit, interpretable management chain.
- Vector Channel: The vector database here is not used for business data. It stores “golden examples” of natural language questions paired with Cypher queries. When a user asks a question, the chatbot retrieves similar examples to guide the LLM in accurately translating the request into a correct Cypher query.
The user immediately sees the result:

A small button before “Click to view detailed processing steps” allows the user to reveal the generated Cypher afterward.

As shown in the figure, the generated Cypher query here is:
MATCH path = (e:Employee {first_name: 'Robert', last_name: 'King'})-[:ReportsTo*0..5]->(manager:Employee)
RETURN path,
[n in nodes(path) | n.first_name + ' ' + n.last_name] as management_chain,
length(path) as chain_length
ORDER BY chain_length DESC
LIMIT 10Although the query is executed inside the chatbot automatically, it can also be visualized directly in the PuppyGraph UI. Users may copy the query to the PuppyGraph UI and run it to see the corresponding management chain in PuppyGraph’s standard graph visualization panel.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.


Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Knowledge graphs and vector databases address complementary aspects of information retrieval. Knowledge graphs make relationships explicit, enabling reasoning over paths, dependencies, communities, and anomalies with clear, interpretable context. Vector databases excel at semantic similarity, allowing fast retrieval of relevant content even when queries don’t match exact keywords. Many organizations achieve the best results by combining both in GraphRAG workflows, where the graph scopes the subgraph that matters, and vectors surface the most relevant content within it.
Traditional graph databases require ETL into separate stores, data duplication, and ongoing maintenance, and deep traversals increase performance tuning complexity. PuppyGraph eliminates these hurdles by letting teams model and query existing tables as a graph in real time, without ETL or duplicate storage. Paired with the PuppyGraph Chatbot, users can interact in natural language, executing graph traversals and vector searches simultaneously to get results that are both structurally meaningful and semantically relevant, without writing queries or managing extra pipelines.
Download PuppyGraph’s forever-free Developer Edition, or book a demo to see how it simplifies knowledge graph and GraphRAG workflows.

Jaz Ku is a Solution Architect with a background in Computer Science and an interest in technical writing. She earned her Bachelor's degree from the University of San Francisco, where she did research involving Rust’s compiler infrastructure. Jaz enjoys the challenge of explaining complex ideas in a clear and straightforward way.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install