

Graph Analytics on Microsoft OneLake: Zero ETL with PuppyGraph

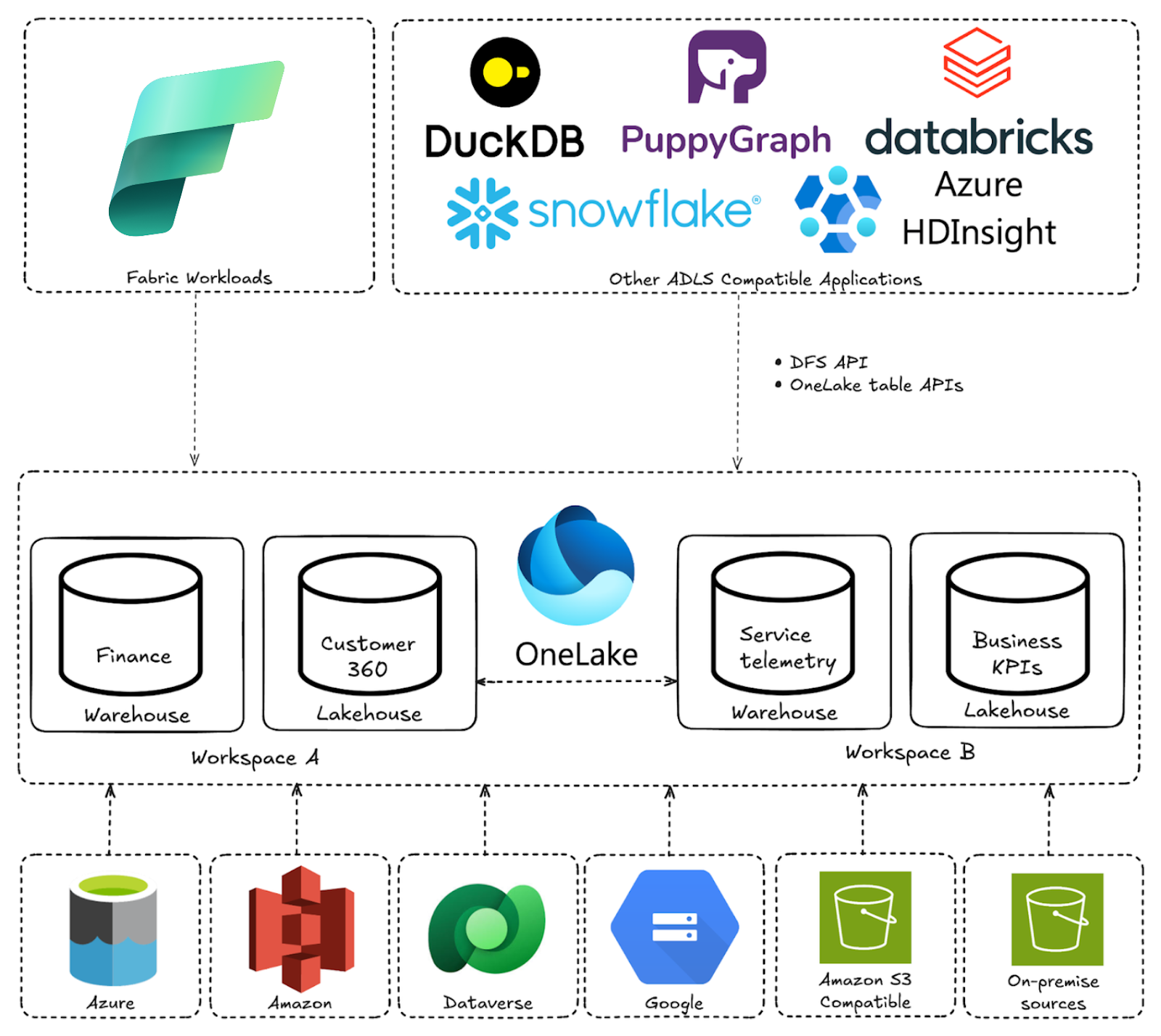
Microsoft OneLake comes provisioned with every Microsoft Fabric tenant as the default data lake. As the “OneDrive of data”, OneLake provides a single logical lake that unifies storage across workspaces and engines. This allows teams to spend less time managing overlapping storage resources and more time collaborating on a shared, governed lake.
For data analytics, this unified view means queries can start from a broader and more consistent picture of the business instead of stitched-together exports. SQL is a natural fit for many workloads such as aggregations, reporting, and familiar BI use cases. Some questions, though, are about how entities relate to each other. When you want to see how things connect across several hops, how risk propagates through dependencies, or how users move through journeys, you are dealing with a graph-shaped problem. These workloads focus on traversing connections and analyzing paths.
That is where PuppyGraph comes in. PuppyGraph is a real-time graph query engine that lets you run graph analytics on the same Delta and Iceberg tables that OneLake exposes, with zero ETL and no duplicate data. You define graph models on your existing tables and run graph queries using openCypher or Gremlin.
Why Microsoft OneLake for Data Analytics?

Microsoft OneLake is well suited for data analytics because it gives the organization a single, unified data lake instead of scattered silos. Teams work with one logical copy of the data that multiple analytics engines can access, whether that is a warehouse, lakehouse, notebook, or Power BI report. Under the hood, OneLake is built on Azure Data Lake Storage Gen2, so it inherits a scalable, enterprise-grade storage foundation while adding a unified, Fabric-aware layer on top. Data can live directly in OneLake and be referenced from external storage via shortcuts, but users get to see everything through a consistent OneLake view. This abstraction lets them focus on how they want to use the data, not which storage account it sits in.
By using open table formats such as Delta Lake and Apache Iceberg, the same tables can be queried efficiently by different engines without rewriting or duplicating data. Analysts, data scientists, and engineers all get to work from the same datasets instead of maintaining competing copies, which simplifies handoffs and reduces rework. Governance and discovery also become easier, since policies and permissions are defined in one place while individual domains still manage their own workspaces and access rules. Data owners keep control, and consumers get a simpler, more consistent way to find and use data for analytics.
Why Relationships Need Graph Analytics
SQL shines at aggregations, filtering, and transactional workloads. The challenge shows up when you care about the deeper connections between data points. Questions like “who can reach what” or “how does this change propagate through downstream systems” are really about relationships. In SQL, answering them often means stringing together long join chains to stitch context across many tables. These queries are hard to write and even harder to understand.
Graph analytics approaches the problem from the other direction. It makes relationships explicit by modeling entities as nodes and their links as edges. With graph query languages like openCypher and Gremlin, you describe patterns and paths instead of stitching joins together, so you can simply start from one entity, follow its connections, and see what lies a few hops away.
As data grows more connected, the most useful insights often lie in how entities relate. Graph analytics brings those relationships into focus, whether you’re tracking identity and access paths in cybersecurity, monitoring financial and transaction flows in financial services, analyzing supply chain dependencies, or modeling customer journeys and recommendations across channels and products.
Graph Analytics Straight From OneLake With Zero ETL
Graph analytics can unlock deeper questions on top of your existing data, but traditionally, getting there has been painful. Standing up a separate graph database means complex ETL pipelines, a separate data store to operate and secure, duplicated data that drifts out of date, and a new vendor surface where you can get locked in.
With PuppyGraph, getting started with graph analytics using data in Microsoft OneLake becomes much simpler. PuppyGraph connects directly to Microsoft OneLake, using the OneLake Tables API for table discovery and the underlying OneLake storage endpoints for data access, so you can work with the data that is already there. You define a graph model on top of your existing tables: which tables represent nodes, which represent edges, and how they are connected. Once that model is in place, you can start running graph queries immediately, without building ETL pipelines or standing up a separate graph database.

Key features of the integration:
- Zero ETL, No Duplicate Copies
Run graph analytics on the same Delta and Iceberg tables that OneLake exposes. No copying to a separate graph database, no separate pipelines.
- Distributed Graph Query Engine
Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Built for Simplicity and Speed
Define flexible graph views directly over your data and query them using standard graph languages like Gremlin and openCypher.
- Best of SQL and Graph
OneLake allows for the querying of data without the movement, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables.
PuppyGraph and OneLake align on allowing users to choose the right query engine for their workloads.
Getting Started: PuppyGraph on OneLake
So how do you get started with PuppyGraph on Onelake within Microsoft Fabric? This section walks through a step-by-step tutorial. You’ll connect to your OneLake tables, define a graph model, and start querying your data as a graph in just a few minutes. For more details, you can refer to our documentation on querying OneLake Data as a Graph.
Prerequisites
- Docker
- A Microsoft Fabric workspace and a user account with at least the Contributor role in that workspace.
- A service principal in Microsoft Entra ID with permissions to read tables in the lakehouse to create later. For more details on setting up authentication, please refer to preparing for authentication.
Before We Get Started
We recommend reading the official documents for getting familiar with OneLake table with OneLake table APIs for Iceberg and lakehouse, as well as the medallion lakehouse architecture for Microsoft Fabric with OneLake.
Data Preparation
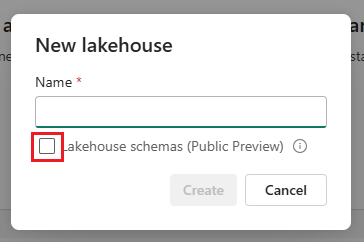
Setting Up The Lakehouse
In your Microsoft Fabric workspace, create a new Lakehouse and ensure that the Lakehouse schemas are enabled. This activates schema support for your Lakehouse, allowing you to group your tables together.
For this demonstration, we’ll be using the OneLake tables API for Iceberg. As such, you’ll want to enable the Delta Lake to Apache Iceberg table format virtualization to ensure that your Delta tables can be read as Iceberg tables.

Microsoft Fabric stores tables using the Delta-Parquet format to support efficient querying over large datasets. To create and populate our Delta tables, we’ll use a Microsoft Fabric notebook. Create a new notebook and run the following Spark SQL code:
CREATE SCHEMA modern;
CREATE TABLE modern.person (
id string,
name string,
age int
) USING DELTA;
INSERT INTO modern.person VALUES
('v1', 'marko', 29),
('v2', 'vadas', 27),
('v4', 'josh', 32),
('v6', 'peter', 35);
CREATE TABLE modern.software (
id string,
name string,
lang string
) USING DELTA;
INSERT INTO modern.software VALUES
('v3', 'lop', 'java'),
('v5', 'ripple', 'java');
CREATE TABLE modern.created (
id string,
from_id string,
to_id string,
weight double
) USING DELTA;
INSERT INTO modern.created VALUES
('e9', 'v1', 'v3', 0.4),
('e10', 'v4', 'v5', 1.0),
('e11', 'v4', 'v3', 0.4),
('e12', 'v6', 'v3', 0.2);
CREATE TABLE modern.knows (
id string,
from_id string,
to_id string,
weight double
) USING DELTA;
INSERT INTO modern.knows VALUES
('e7', 'v1', 'v2', 0.5),
('e8', 'v1', 'v4', 1.0);
Now that our data is loaded in, we can connect PuppyGraph directly to our OneLake Delta tables to start running graph queries.
Connecting to PuppyGraph
Start a PuppyGraph Docker instance with the following command:
docker run -p 8081:8081 -p 8182:8182 -p 7687:7687 -e PUPPYGRAPH_PASSWORD=puppygraph123 -e QUERY_TIMEOUT=5m -d --name puppy --rm --pull=always puppygraph/puppygraph:0.101Once the instance is up and running, we can head over to PuppyGraph’s Web UI at http://localhost:8081 with the default credentials:
- Username: puppygraph
- Password: puppygraph123
Modeling The Graph
Create a schema.json file that maps nodes and edges to their corresponding tables. Make sure to replace the placeholders in the schema.json with your actual credentials.
{
"catalogs": [
{
"name": "test_onelake_table_api",
"type": "iceberg",
"metastore": {
"type": "rest",
"uri": "https://onelake.table.fabric.microsoft.com/iceberg",
"warehouse": "<fabric_workspace_id>/<fabric_data_item_id>",
"security": "OAUTH2",
"credential": "<client_id>:<client_secret>",
"enableIcebergMetaCache": "true",
"icebergMetaCacheTTL": "180",
"scope": "https://storage.azure.com/.default",
"oauthServerUri": "https://login.microsoftonline.com/<tenant_id>/oauth2/v2.0/token"
},
"storage": {
"type": "AzureDLS2",
"clientId": "<client_id>",
"clientSecret": "<client_secret>",
"clientEndpoint": "https://login.microsoftonline.com/<tenant_id>/oauth2/v2.0/token"
}
}
],
"graph": {
"vertices": [
{
"label": "person",
"oneToOne": {
"tableSource": {
"catalog": "test_onelake_table_api",
"schema": "modern",
"table": "person"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_id_id"
}
]
},
"attributes": [
{
"type": "STRING",
"field": "name",
"alias": "name"
}
]
}
},
{
"label": "software",
"oneToOne": {
"tableSource": {
"catalog": "test_onelake_table_api",
"schema": "modern",
"table": "software"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_id_id"
}
]
},
"attributes": [
{
"type": "STRING",
"field": "name",
"alias": "name"
},
{
"type": "STRING",
"field": "lang",
"alias": "lang"
}
]
}
}
],
"edges": [
{
"label": "created",
"fromVertex": "person",
"toVertex": "software",
"tableSource": {
"catalog": "test_onelake_table_api",
"schema": "modern",
"table": "created"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_id_id"
}
]
},
"fromId": {
"fields": [
{
"type": "STRING",
"field": "from_id",
"alias": "puppy_from_from_id"
}
]
},
"toId": {
"fields": [
{
"type": "STRING",
"field": "to_id",
"alias": "puppy_to_to_id"
}
]
}
},
{
"label": "knows",
"fromVertex": "person",
"toVertex": "person",
"tableSource": {
"catalog": "test_onelake_table_api",
"schema": "modern",
"table": "knows"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_id_id"
}
]
},
"fromId": {
"fields": [
{
"type": "STRING",
"field": "from_id",
"alias": "puppy_from_from_id"
}
]
},
"toId": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_to_id"
}
]
}
}
]
}
}
In Web UI, select the file `schema.json` under Upload Graph Schema JSON, then click on Upload.
Once the schema is uploaded, the schema page shows the visualized graph schema as follows.

Querying the Graph
Once everything is set up, we can navigate to the Query panel and start querying our data as a graph.
Some example queries you can run include:
- Retrieve a vertex named "marko"
Gremlin:
g.V().has("name", "marko").valueMap()Cypher:
MATCH (v {name: 'marko'}) RETURN v- Retrieve the paths from "marko" to the software created by those whom "marko" knows
Gremlin:
g.V().has("name", "marko")
.out("knows").out("created").path()Cypher:
MATCH p=(v {name: 'marko'})-[:knows]->()-[:created]->()
RETURN p
Teardown
To stop the PuppyGraph container, run the following command:
docker stop puppyConclusion
Microsoft OneLake gives you a unified, governed lake that any engine can query. PuppyGraph plugs straight into that tech stack. Instead of copying data into a separate graph database, you run graph queries directly on the same Delta and Iceberg tables that power your warehouses, lakehouses, and reports.
If you are already investing in Microsoft Fabric and want to try graph queries, download PuppyGraph’s forever-free Developer Edition or book a free demo today with our graph experts.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Jaz Ku is a Solution Architect with a background in Computer Science and an interest in technical writing. She earned her Bachelor's degree from the University of San Francisco, where she did research involving Rust’s compiler infrastructure. Jaz enjoys the challenge of explaining complex ideas in a clear and straightforward way.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install