

7 Types of RAG Techniques Explained
Retrieval-Augmented Generation (RAG) has become one of the most practical ways to improve how large language models work in real-world systems. Instead of relying only on static training data, RAG allows models to fetch relevant information from external sources before generating answers. This approach helps reduce hallucinations, improve factual grounding, and support enterprise use cases that depend on fresh or proprietary data. As organizations increasingly deploy AI into production workflows, the need for reliable retrieval strategies has become just as important as the language models themselves.
However, RAG is not a single architecture but a growing ecosystem of techniques. From basic retrieval pipelines to sophisticated agentic workflows and graph-enhanced reasoning, each method addresses different challenges such as context management, reasoning depth, or system scalability. Understanding these variations is essential for designing effective AI systems. This article explores seven major types of RAG architectures: Naïve, Advanced, GraphRAG, Hybrid, Agentic, Multi-Hop, Adaptive and Iterative RAG, explains when to use them, and examines how evolving pipelines enable more adaptive, accurate, and context-aware generative AI solutions.
What Is Retrieval-Augmented Generation (RAG)?
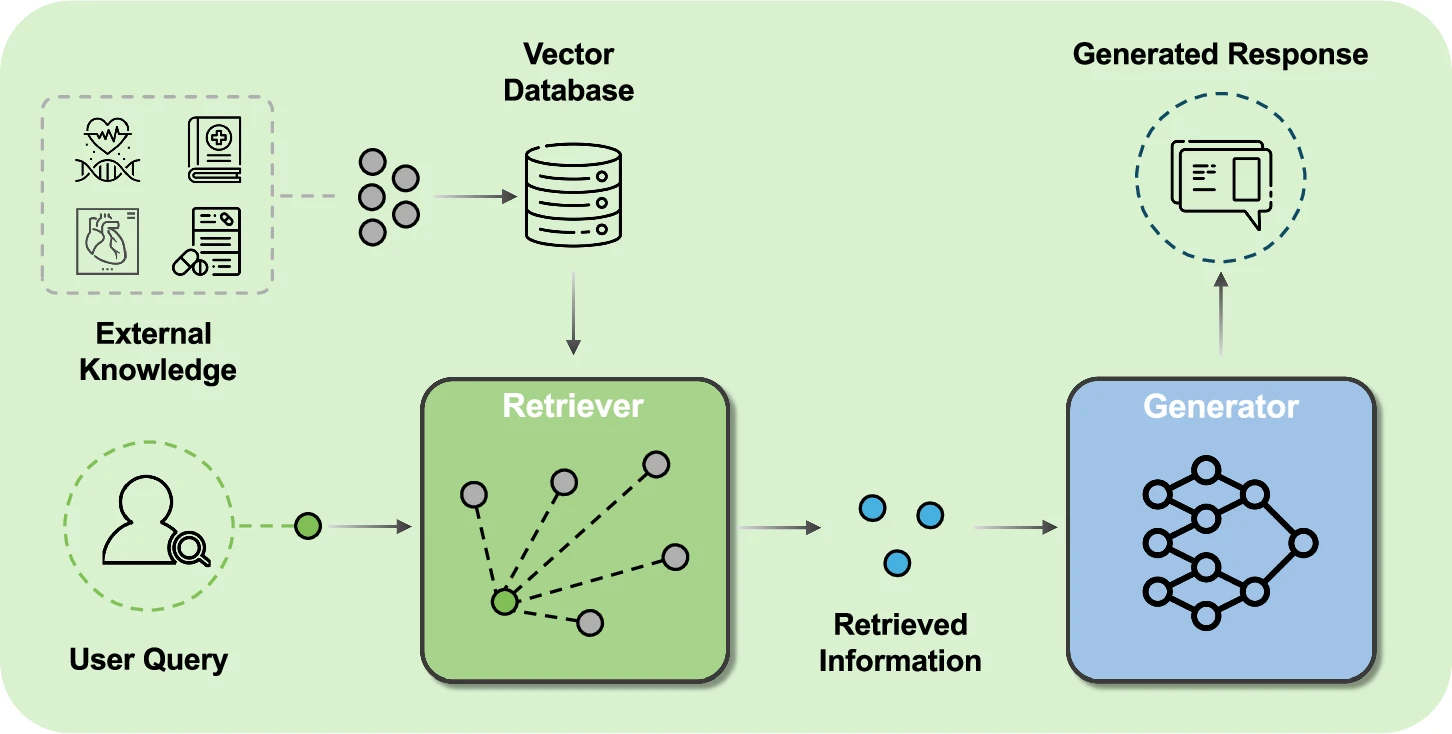
Retrieval-Augmented Generation is a framework that combines information retrieval with generative language models. Instead of generating responses solely from pre-trained knowledge, a RAG pipeline retrieves relevant documents, passages, or structured data from external sources. The retrieved context is then inserted into the model’s prompt, allowing the model to produce answers grounded in real information. This process enables systems to respond using up-to-date knowledge, domain-specific materials, and organizational data that may not be present in the model’s training set.
In practice, a typical RAG system consists of three main steps: indexing data, retrieving relevant context based on a query, and generating a response using the retrieved information. Data can come from documents, databases, APIs, or knowledge graphs. By separating retrieval from generation, RAG allows teams to update information sources without retraining models. This modularity makes it a powerful architecture for enterprise AI applications where accuracy, freshness, and explainability are essential requirements.
Why RAG Techniques Matter for LLM Performance
Large language models are powerful but inherently limited by the data they were trained on and the fixed parameters learned during training. Without retrieval, models may generate outdated or incorrect information when faced with unfamiliar or evolving topics. RAG techniques address these limitations by dynamically injecting context at inference time. This improves factual correctness, enhances domain-specific performance, and allows AI systems to work with private organizational knowledge without modifying the underlying model weights.
Beyond accuracy, RAG techniques also influence how models reason and structure responses. Advanced retrieval strategies can improve coherence, enable multi-step reasoning, and reduce irrelevant information in prompts. For enterprise deployments, the choice of RAG technique affects system cost, latency, scalability, and maintenance complexity. Understanding different architectures allows teams to design pipelines that balance performance with operational efficiency while ensuring the AI system remains reliable as data and use cases evolve.
Naïve (Standard) RAG Architecture
Naïve RAG represents the simplest implementation of retrieval-augmented generation. A user query is converted into an embedding, matched against a vector database, and the most relevant documents are retrieved. These documents are then inserted into the prompt, and the language model generates an answer based on the combined context. This architecture is easy to implement and works well for straightforward question-answering tasks or document retrieval scenarios where context is relatively small and well-structured.
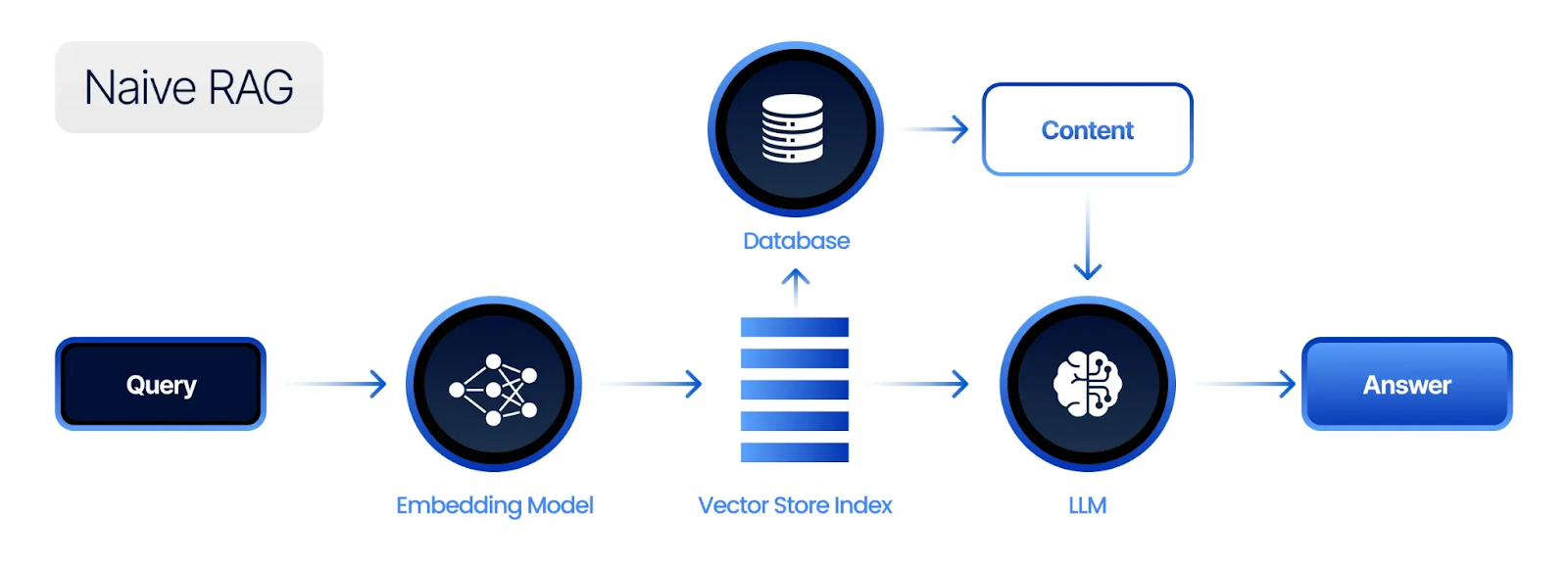
Despite its simplicity, naïve RAG often struggles with complex queries or noisy data. The model may receive irrelevant or redundant context, leading to weaker responses. It also lacks mechanisms for reasoning across multiple sources or verifying retrieved information. However, for many early-stage deployments or small-scale internal tools, naïve RAG remains a valuable starting point due to its low implementation complexity and fast iteration cycle.
Advanced RAG: Chunking, Re-Ranking & Context Optimization
As organizations scale beyond basic retrieval, advanced RAG techniques focus on improving the quality of context passed to the language model. Chunking divides documents into smaller, semantically meaningful sections to increase retrieval precision. Re-ranking algorithms evaluate retrieved passages using more sophisticated models to ensure the most relevant information appears first. Context optimization methods selectively filter or compress retrieved data to fit within token limits while preserving critical meaning.
These enhancements significantly improve model performance without fundamentally changing the architecture. Instead of simply retrieving the top results from a vector database, advanced pipelines may apply multiple filtering stages. The result is more focused prompts, reduced hallucinations, and improved response clarity. Context optimization also helps manage costs by reducing unnecessary tokens, making it easier to deploy RAG systems at scale while maintaining consistent output quality.
GraphRAG (Knowledge Graph–Enhanced Retrieval)
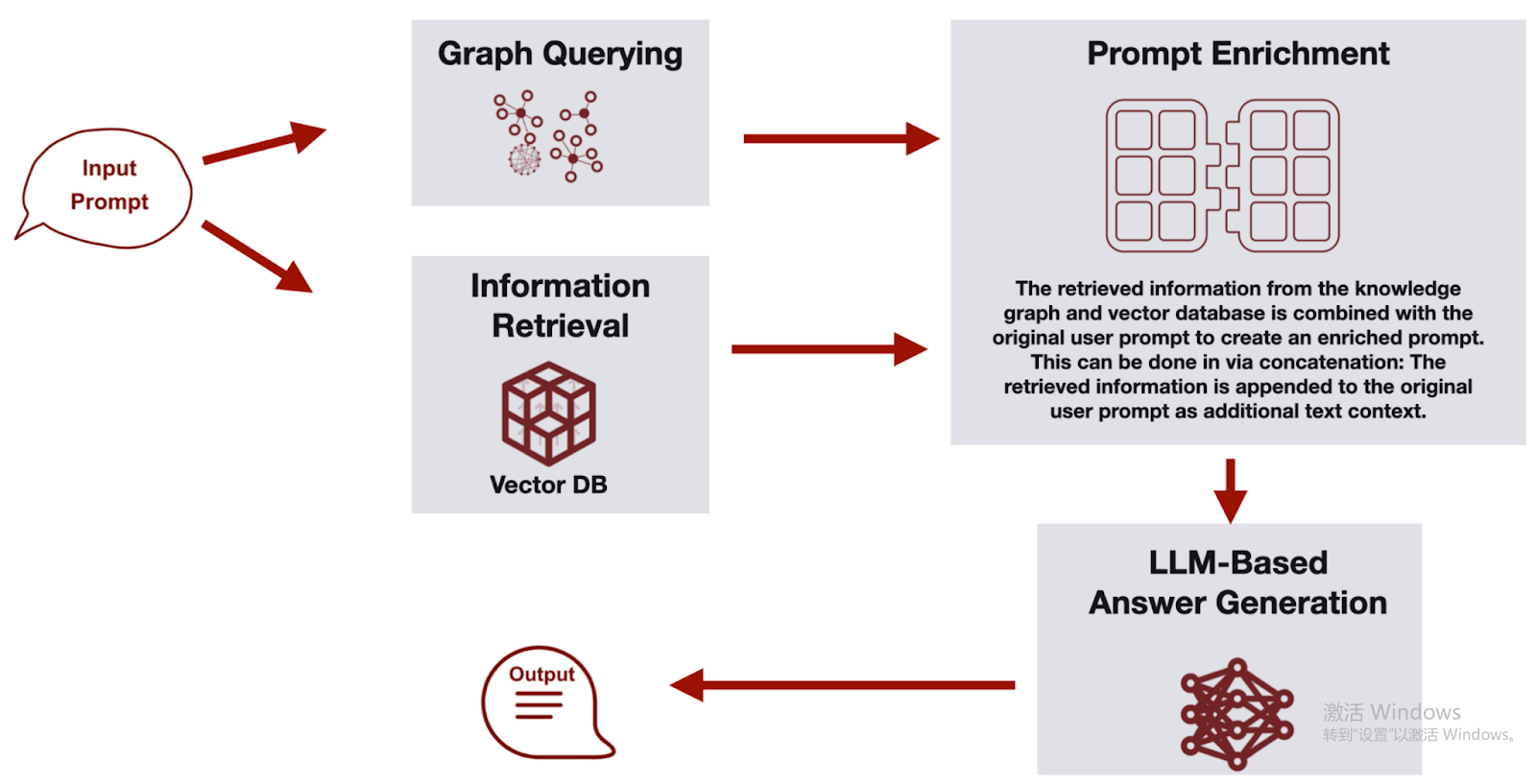
GraphRAG extends RAG beyond representation learning into explicit relational reasoning by making the knowledge graph the core retrieval and context modeling layer. When a user submits a natural language query, the system first analyzes what information is required to answer it and translates that need into a structured graph query. This query runs against the underlying knowledge graph to retrieve relevant subgraphs, entities, relationships, and any necessary aggregation results. Instead of pulling isolated text fragments, GraphRAG assembles a connected, structured view of the data that reflects how concepts relate to one another.
The retrieved graph-based context is then combined with additional computations or summaries when needed, forming a rich and context-aware representation of the problem. This structured context is passed back to the GraphRAG agent, which performs multi-hop reasoning, infers dependencies, and synthesizes a grounded response. By explicitly modeling relationships and traversing them during retrieval, GraphRAG can uncover indirect connections and layered dependencies that traditional vector search may overlook. Although it requires constructing or integrating a knowledge graph, the approach delivers stronger explainability, deeper contextual understanding, and improved performance on complex analytical queries where network structure is central to the answer.
Hybrid RAG
Hybrid RAG combines multiple retrieval strategies, such as mixing semantic vector search, keyword-based search, and structured graph queries. Semantic search captures conceptual similarity, keyword search ensures precise matches for names, numbers, or technical terminology, while graph queries enable relationship-aware retrieval across connected entities and multi-hop paths. By blending these methods, hybrid pipelines overcome the weaknesses of relying on a single retrieval technique. The system may retrieve documents, structured records, or subgraphs from different sources and merge results before passing them to the generation stage.
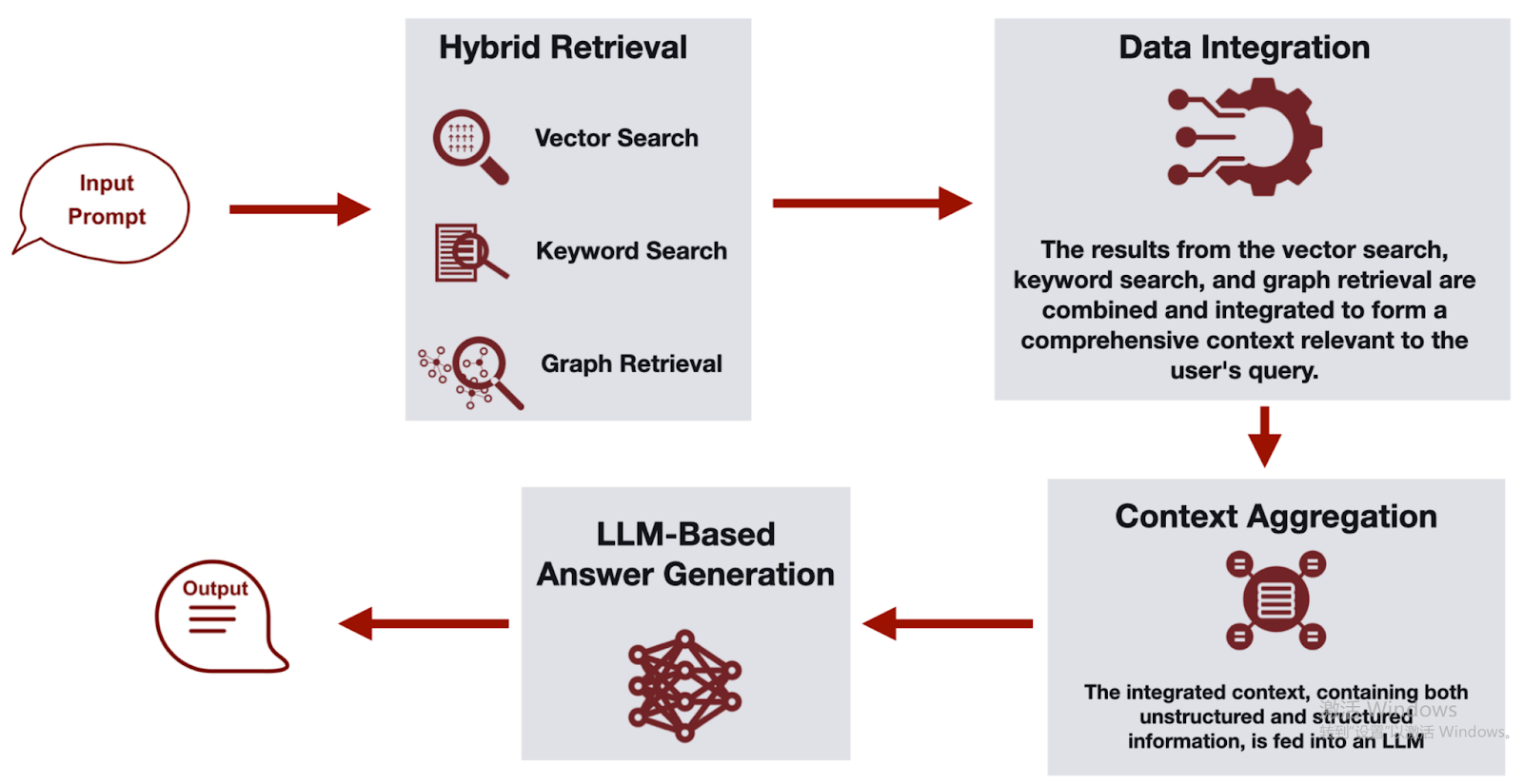
Hybrid RAG is particularly useful in enterprise environments where data is heterogeneous and stored across different systems. Structured databases, unstructured documents, and knowledge graphs or graph query engines may all contribute to the final context. The architecture often includes ranking layers to resolve conflicts between retrieval sources and to prioritize the most relevant signals across semantic, lexical, and relational dimensions. This approach increases coverage and improves reliability, especially for technical, legal, or analytical content where both semantic understanding and exact structural relationships are critical to generating accurate responses.
Agentic RAG (Tool-Using and Iterative Retrieval)
Agentic RAG introduces autonomous decision-making into the retrieval process. Instead of performing a single retrieval step, an AI agent decides when to search, which tools to use, and how to refine queries iteratively. The agent may call external APIs, run database queries, or request additional context based on intermediate reasoning. This approach allows the system to adapt dynamically to complex tasks that cannot be solved with a single retrieval pass.
The iterative nature of agentic RAG enables more flexible workflows. The model can evaluate its own progress, identify missing information, and retrieve additional data before producing a final answer. While this increases computational cost and architectural complexity, it significantly improves performance on open-ended or multi-stage problems. Agentic RAG is increasingly used in advanced assistants, research tools, and decision-support systems that require real-time interaction with multiple data sources.
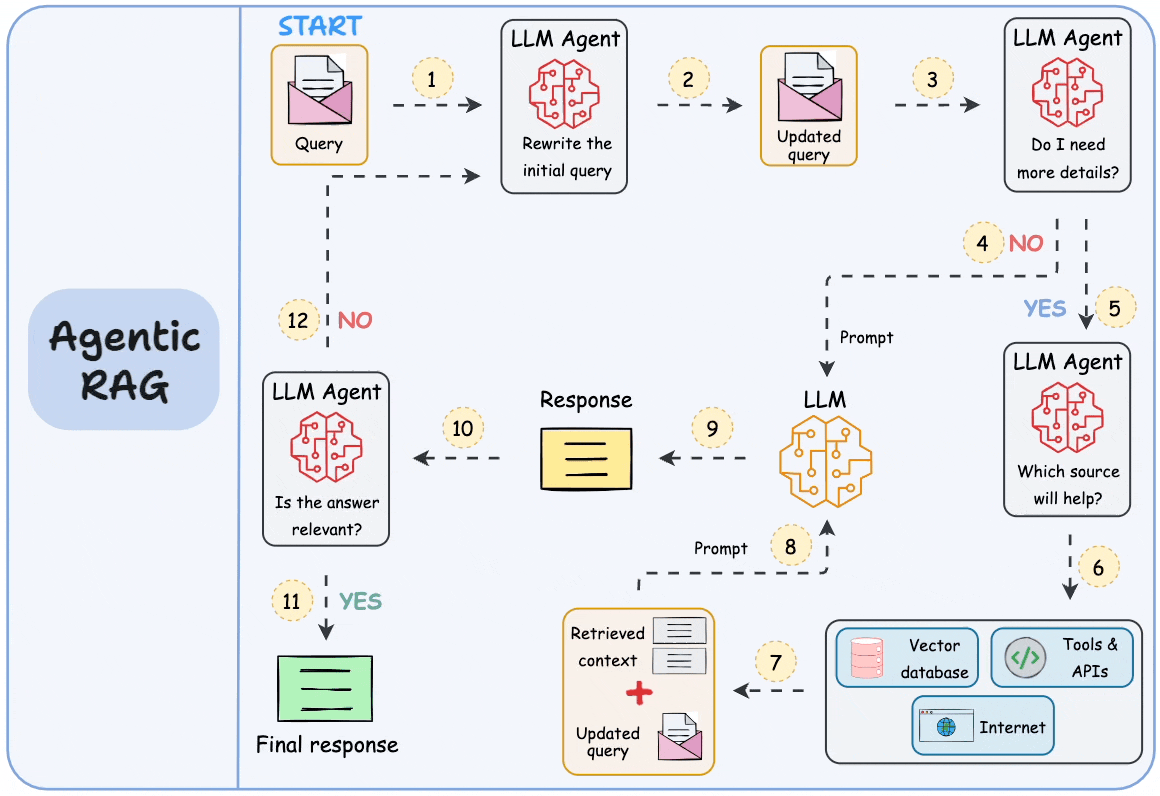
Figure: An example framework of Agentic RAG (Source)
Multi-Hop RAG for Complex Reasoning
Multi-hop RAG focuses on answering questions that require reasoning across multiple pieces of information. Instead of retrieving context in one step, the system performs sequential retrievals, where the results of one step inform the next query. This approach is particularly useful for analytical tasks, investigative research, or technical troubleshooting scenarios where answers depend on connecting multiple facts or sources together in a logical sequence.
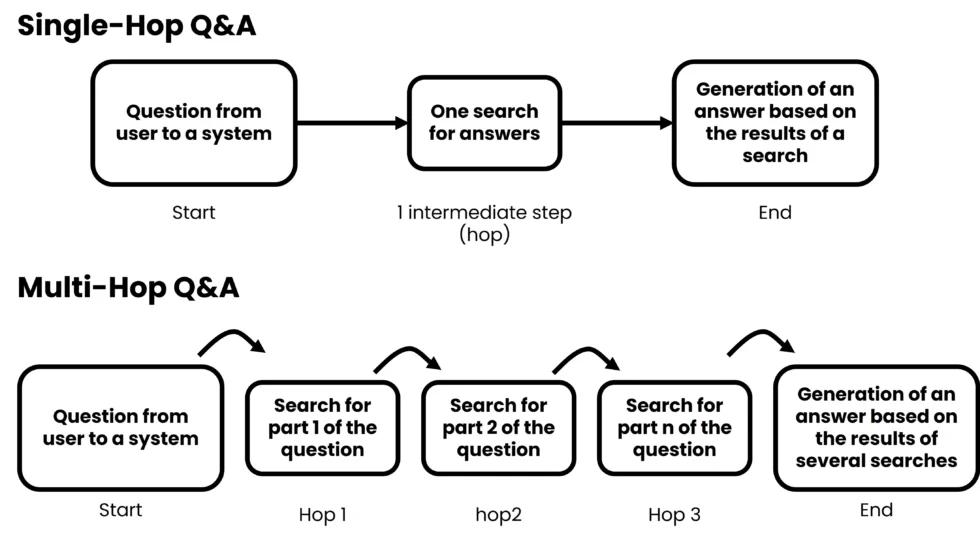
In multi-hop pipelines, the language model may generate intermediate questions or hypotheses to guide subsequent retrieval steps. Each hop adds more context, gradually building a comprehensive understanding of the problem. This architecture improves reasoning depth but requires careful design to avoid accumulating irrelevant information. Techniques such as structured prompts, context filtering, and evaluation checkpoints help maintain focus and ensure the final answer reflects accurate and coherent reasoning across all retrieved materials.
Adaptive and Iterative RAG Pipelines
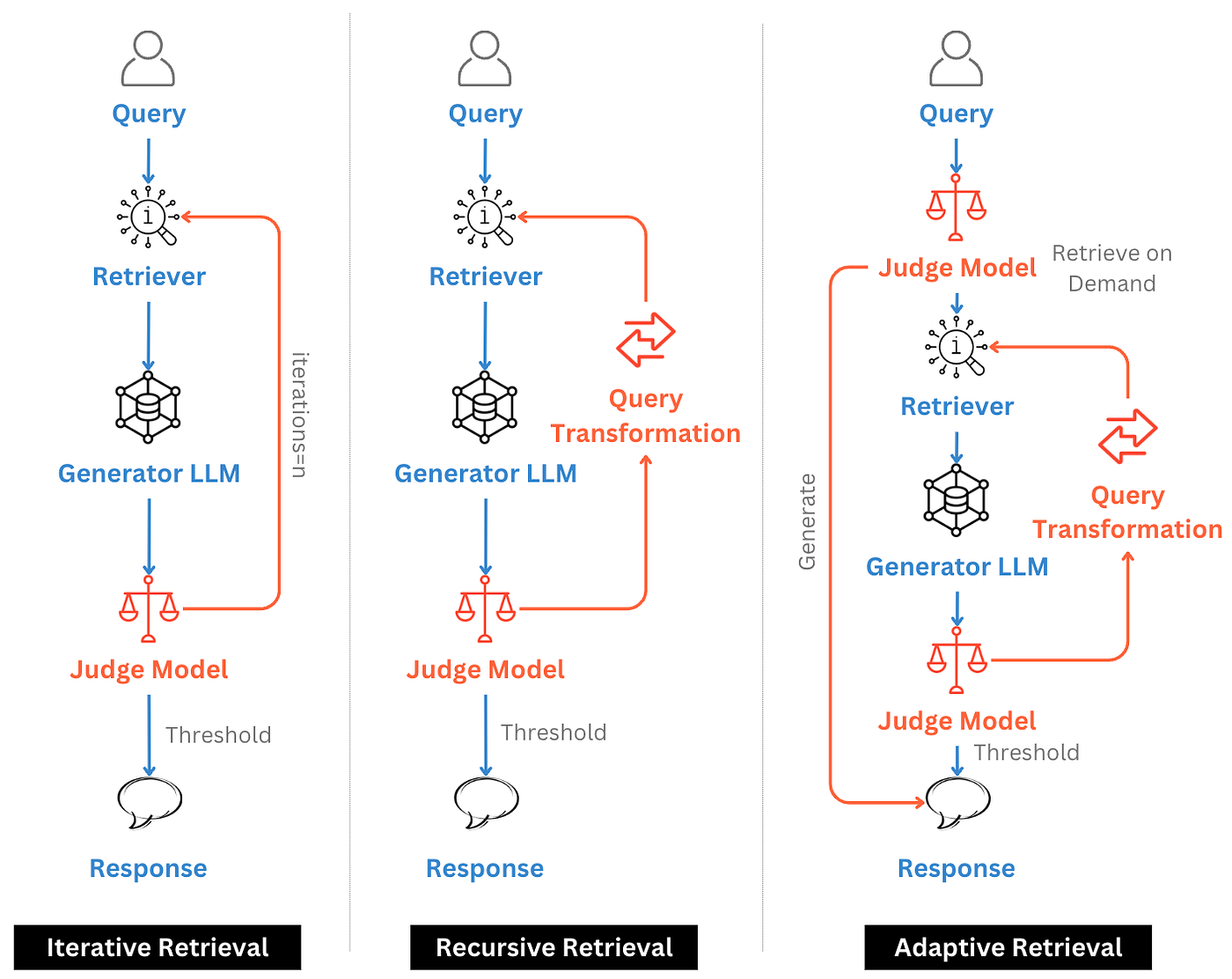
Adaptive RAG pipelines introduce feedback loops that adjust retrieval strategies based on the model’s performance or user interaction. The system may analyze the confidence of generated responses, evaluate retrieval quality, or incorporate user corrections to refine future queries. Over time, the pipeline learns which sources, retrieval methods, or prompt structures produce the best outcomes, creating a continuously improving AI system.
Iterative pipelines also support real-time adjustments during a single conversation. For example, if the model detects ambiguity or incomplete information, it can request clarification or initiate additional retrieval steps automatically. This adaptability improves user experience and increases reliability in complex environments. This idea shares some similarities with agentic RAG paradigms, as both rely on LLM-based decision-making. The key difference is that in agentic workflows, the model can autonomously decide whether to perform retrieval, which tools to use, and how to refine queries based on intermediate reasoning. In contrast, adaptive or iterative RAG pipelines typically rely on a judge or evaluation component to determine whether retrieval is needed and which retrieval strategy should be applied. Adaptive RAG architectures represent a shift from static pipelines toward dynamic systems that evolve alongside data sources, user behavior, and organizational knowledge requirements.
RAG vs Fine-Tuning: Key Differences
RAG and fine-tuning address different challenges in AI system design. Fine-tuning modifies a model’s parameters to encode new knowledge or behavior directly into the model. This can improve consistency and style but requires retraining whenever information changes. In contrast, RAG keeps the model unchanged while updating external data sources. This allows teams to refresh knowledge quickly without costly retraining cycles or risk of catastrophic forgetting.
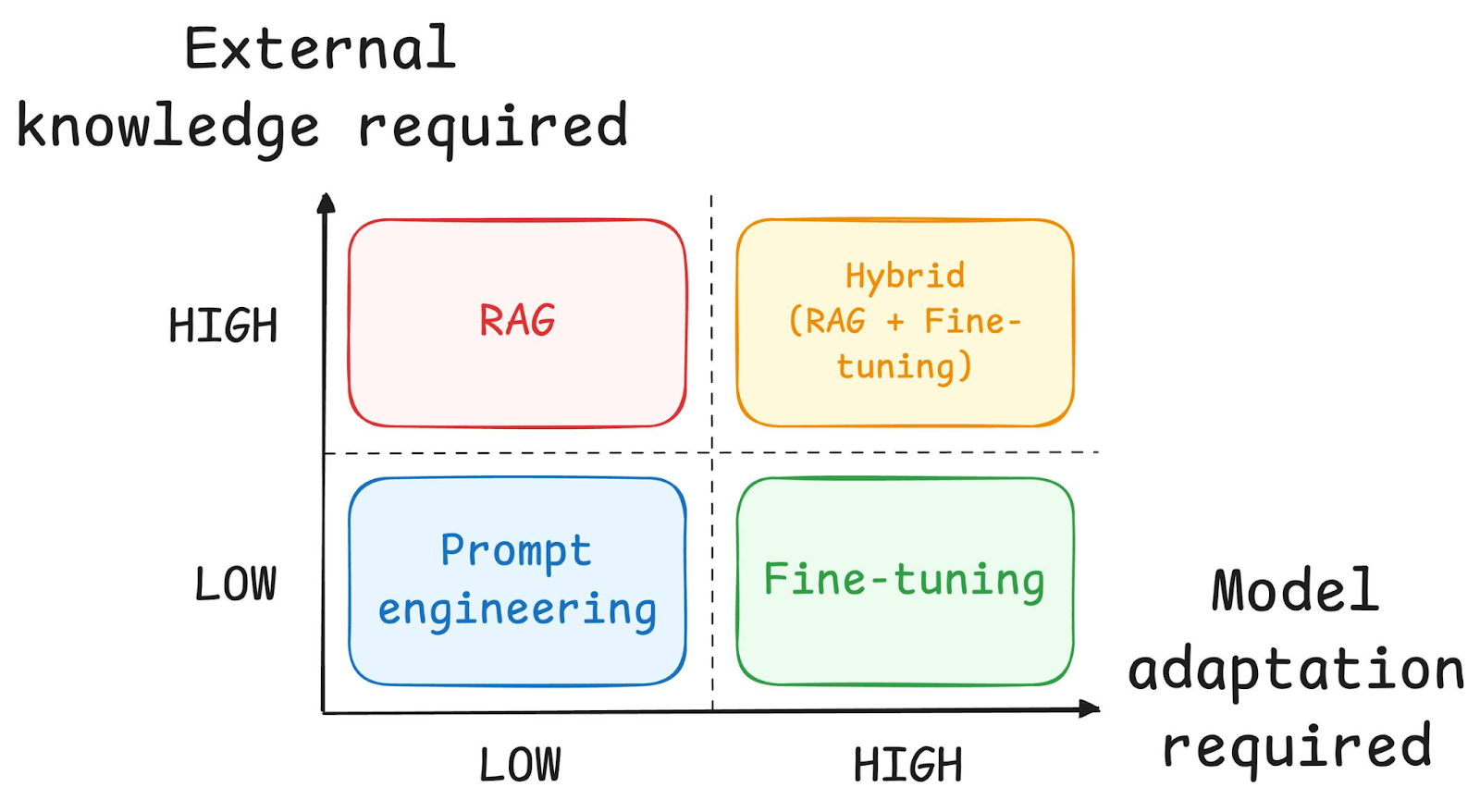
In many enterprise deployments, RAG and fine-tuning complement rather than replace each other. Fine-tuning can improve task-specific performance, while RAG provides dynamic access to evolving information. Combining both approaches enables systems to maintain strong reasoning capabilities while staying grounded in accurate, up-to-date data. The choice depends on factors such as data volatility, infrastructure resources, latency requirements, and the degree of control needed over model behavior and output consistency.
How PuppyGraph Helps
PuppyGraph enables graph-based retrieval without requiring organizations to migrate data into a dedicated graph database. Instead of building complex ETL pipelines, teams can map existing relational, analytical, or lakehouse systems into a virtual graph layer. This unified interface allows applications to traverse relationships and gather contextual information directly from source systems.
This capability is particularly valuable for GraphRAG-style workflows, where multi-hop reasoning and relationship traversal improve retrieval quality. It also serves as a flexible retrieval layer in hybrid pipelines that combine vector search, keyword search, and structured queries. By querying connected data structures across multiple systems, AI applications can assemble richer context with less data duplication and simpler architecture.
This approach allows teams to experiment with advanced retrieval strategies while minimizing infrastructure changes.
As a concrete example, we’ll show how quickly you can enhance a RAG pipeline with a knowledge graph modeled directly from relational data using PuppyGraph.
As the first step, let’s deploy the dataset Northwind on PuppyGraph, by uploading the schema, which defines the structure of the graph view, the datasource (such as duckDB), and how the relational tables correspond to the nodes and edges in the graph:
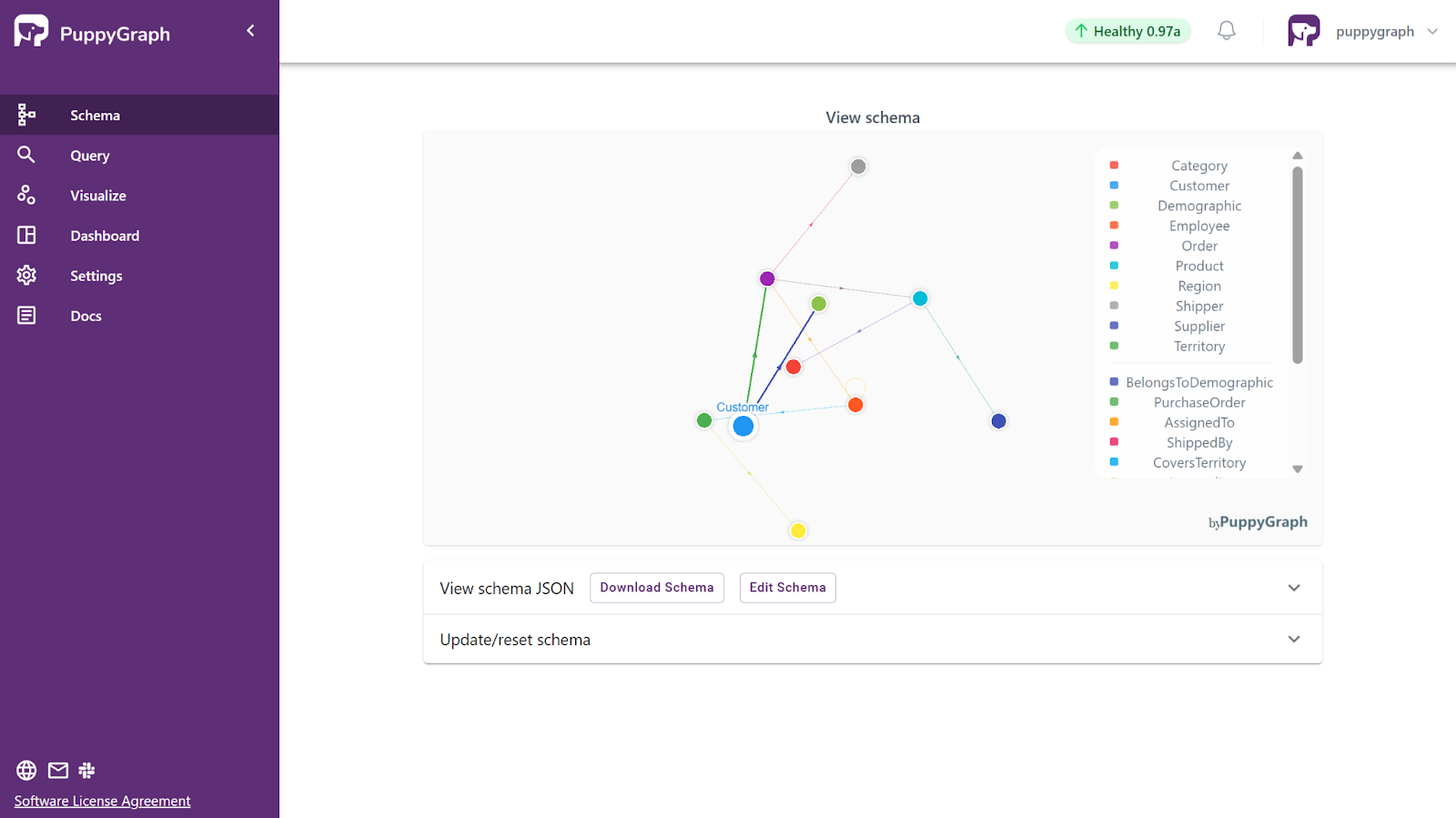
In the screenshot above, you can see how PuppyGraph maps relational tables into a graph model by defining nodes and edges. In this graph, customers are linked to their orders, orders to products, and employees to the orders they manage. Once the graph view is defined, you can run a Gremlin or Cypher query against the dataset directly, surfacing insights that would require complex joins or custom pipelines in SQL.

To demonstrate how GraphRAG works here, we asked the PuppyGraph Chatbot: “Which suppliers are associated with the products that appear most frequently in customer orders?” The chatbot used vector search to enhance the generation of Cypher queries. Then, it used PuppyGraph to traverse the knowledge graph in real time, following connections from products to suppliers and counting orders along the way. The LLM then combined the generated Cypher results to produce a clear answer with the top suppliers, the products driving those orders, and the total order counts.
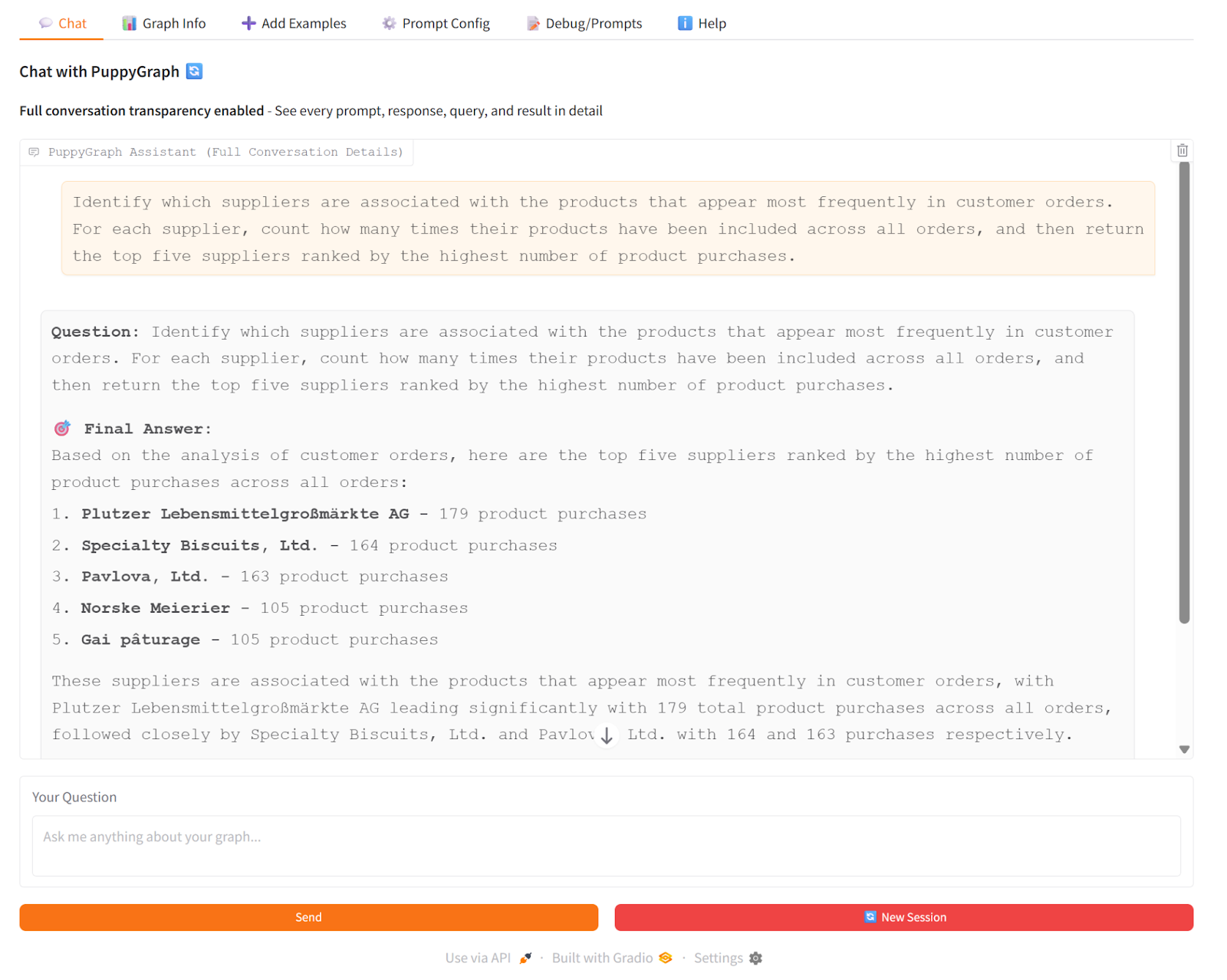
This shows how GraphRAG works: PuppyGraph provides the actual graph traversal and multi-hop relationships, so the chatbot’s answers are grounded in real connections rather than just inferred from text.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Retrieval-Augmented Generation has evolved from simple vector search pipelines into a diverse ecosystem of architectures, each designed to address different challenges in reasoning, context management, and scalability. From naïve and advanced RAG to hybrid, multi-hop, agentic, and adaptive pipelines, the core principle remains the same: grounding language models in reliable external knowledge. The choice of architecture depends on data complexity, performance requirements, and operational constraints, but the goal is consistent: improving factual accuracy, reducing hallucinations, and enabling enterprise-ready AI systems.
As GraphRAG and hybrid approaches gain momentum, structured relationship-aware retrieval is becoming increasingly important. PuppyGraph demonstrates how organizations can implement graph-based retrieval without heavy ETL or data duplication, enabling real-time, multi-hop reasoning directly on existing data sources. By combining flexible retrieval strategies with scalable graph traversal, teams can build AI systems that are not only more accurate, but also more adaptable to evolving data and business needs.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install