

What Is a Reasoning Engine? The Ultimate Guide
Modern AI systems can recognize patterns, generate text, and extract signals from massive datasets. But many real-world systems require the ability to obtain conclusions from known relationships and enforce consistent decision logic, which is what a reasoning engine can help with.
This post explains what a reasoning engine is, how it works, the types of reasoning systems used in practice, and how these engines integrate with knowledge graphs and modern AI architectures.
What Is a Reasoning Engine?
A reasoning engine is an AI system component that obtains new facts, decisions, or actions from existing facts using an explicit inference method. You give it a knowledge base (facts) and a reasoning model (rules, logic, or probabilistic assumptions); it produces conclusions that were not directly immediate in the input.
A reasoning engine can deduce what must be true, or likely true, in view of what you know. So you can ask questions like “Given these entities and constraints, what else follows?” or “Which actions should trigger when these conditions hold?”
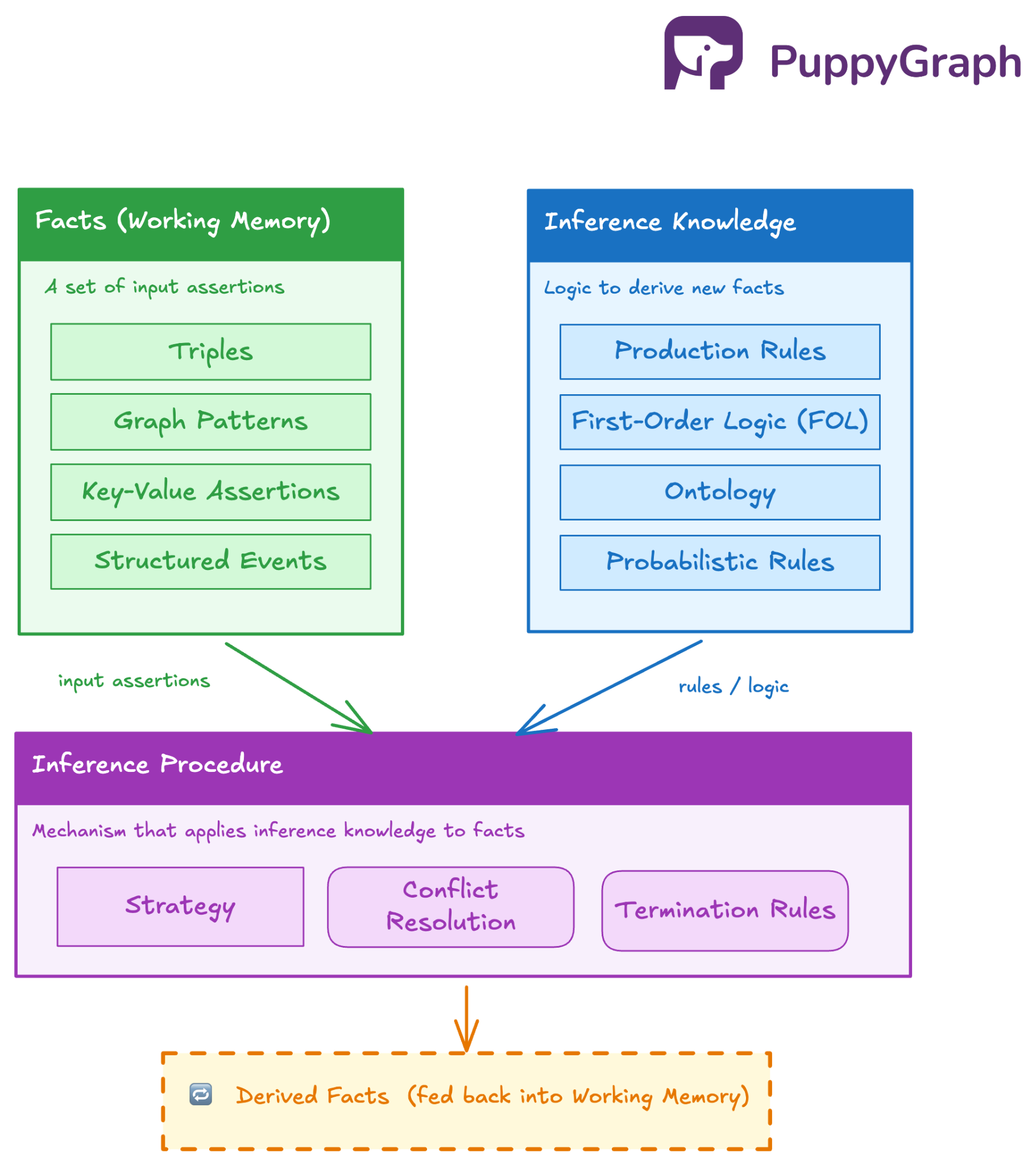
Most reasoning engines operate over three core elements:
- Facts (working memory): A set of assertions the engine treats as inputs. Depending on the system, these can be triples, graph patterns, key-value assertions, or structured events.
- Inference knowledge: The logic that expounds how to derive new facts: production rules, first-order logic, description logic (common in ontology reasoners), or probabilistic rules.
- Inference procedure: The mechanism that applies inference knowledge to facts, for example, strategy (like chaining), conflict resolution, and termination rules.
Reasoning Engines’ Importance in AI Systems
AI systems entail structured decision logic in addition to pattern recognition. Large language models, despite being able to predict tokens, do not enforce constraints. They do not guarantee consistency. And they do not understand formal relationships unless you encode them emphatically. Using a reasoning engine, you can make certain that decisions follow defined rules, domain logic, or ontological constraints.
Enforcing Deterministic Logic
AI systems often operate in regulated or high-stakes environments. Finance, healthcare, cybersecurity, and supply-chain systems cannot rely on probabilistic outputs alone.
A reasoning engine helps effectuate rules like these:
- Access policies
- Compliance constraints
- Risk thresholds
- Eligibility conditions
If a rule states that “a customer with overdue invoices cannot place a new order,” the system must apply it consistently. A language model might generate an explanation. But only a reasoning engine guarantees imposition.
This separation between generative capability and deterministic logic is essential in production AI systems.
Operating Over Structured Knowledge
Modern AI pipelines increasingly rely on structured data, for example:
- Knowledge graphs
- Ontologies
- Entity relationship networks
- Schema-constrained datasets
Structured knowledge encodes relationships, but for insight, you need to derive new relationships from existing ones, the process of which a reasoning engine formalizes and automates. It transfigures static graph data into logically enriched knowledge. This ability becomes critical in systems that rely on multi-hop relationships.
Supporting Explainability and Auditability
Enterprise AI systems must explain decisions so as to do away with black-box predictions that create operational and legal risks. A reasoning engine provides traceable inference paths so that each derived fact links back to, for example, the source facts, the rule that triggered the inference, and the inference chain. It turns out a structured explanation graph; teams can inspect the rationale behind the decision and the contributing rules. In many industries, such explainability is a system requirement.
Complementing Neural Models
Neural models understand languages, and can efficiently extract motifs and embed similarity, but not when it comes to strict rule enforcement, logical consistency, and symbolic constraint satisfaction.
A reasoning engine supplements neural models by:
- Validating LLM outputs against domain rules
- Inferring additional structured facts from extracted entities
- Enforcing constraints preceding final actions
Enabling Policy-Driven Automation
Automation systems require clear decision boundaries that a reasoning engine can provide. As opposed to hardcoding logic across microservices, you can centralize decision logic in a rule or inference layer. By doing so, you reduce duplicated logic, improve maintainability, and allow controlled rule evolution. The reasoning layer becomes the decision authority.
As AI adoption increases, so do complexity and data volumes; LLMs introduce non-deterministic behavior into workflows. As a result, organizations need stronger control over aspects like the following which a reasoning engine can help attain:
- Decision consistency
- Multi-hop relationship inference
- Policy enforcement
- Cross-entity reasoning
How a Reasoning Engine Works
A reasoning engine operates as an inference runtime. It continuously assesses known facts against a formal rule system and derives new deductions until no further inferences are practicable or a goal condition has been accomplished.
The process begins with a structured working memory. This memory contains asserted facts expressed in a formal representation. These facts may be logical predicates, graph relationships, typed entities, or domain-specific statements. The engine does not process raw text; it requires structured inputs that follow a known schema or logical model.
Once the fact base becomes available, the engine evaluates rules against it. Each rule defines a condition and a consequence. In a production-style rule, the condition describes a pattern over variables. When the engine finds bindings that satisfy that pattern, it schedules the rule for execution.
For example, consider the following rule:
IF ReportsTo(X, Y) AND Manager(Y)
THEN ManagedBy(X, Y)If the fact base contains ReportsTo(Alex, Bob) and Manager(Bob), the engine binds X = Alex and Y = Bob. The rule activates. When it fires, the engine inserts the derived fact ManagedBy(Alex, Bob) into working memory.
That insertion may activate auxiliary rules. The engine therefore runs in a loop. It matches rules, selects an applicable rule instance, executes it, updates the working memory, and repeats the cycle. This continues until the system reaches a fixed point, meaning no new rules can produce additional facts.
You also need efficient pattern matching in this cycle. Naively scanning the entire fact base for each rule would not scale. Most production-grade engines instead compile rules into discrimination networks such as the Rete algorithm. These networks cache partial matches and propagate only incremental changes. As new facts arrive, the engine updates only the affected rule nodes instead of re-evaluating everything.
Another key component is conflict resolution. Multiple rules may become eligible at the same time. The engine maintains an agenda and applies a selection strategy, often based on rule priority, specificity, or recency of facts. It averts non-deterministic execution order in systems that require predictable behavior.
In dynamic environments, the engine must also manage truth dependencies. If a base fact is retracted or modified, previously derived facts may no longer hold. Advanced engines implement truth maintenance mechanisms to track which inferences depend on which premises. When a premise changes, dependent conclusions are invalidated or recomputed. Without this, derived knowledge can silently drift into inconsistency.
At scale, reasoning resembles incremental dataflow computation. Facts propagate through a rule network. Each propagation step may generate new bindings. The engine terminates when propagation stabilizes.
The execution model we just discussed will become clearer when we examine different categories of reasoning engines and how they structure their inference strategies in the upcoming sections.
Types of Reasoning Engines
Rule-Based
These systems encode domain logic as explicit condition–action rules, for example:
IF <condition>
THEN <action or derived fact>When the engine detects that a condition holds in working memory, it derives a new fact or triggers an action. It dominates business rule systems and policy automation platforms because it keeps logic readable and modular. You can update rules without rewriting application code. However, rule interactions can grow complex. As rule counts increase, unintended cascades become harder to reason about without careful governance.
Logic-Based
Logic-based reasoners operate on logical systems such as first-order logic or description logic. Instead of focusing on operational rules, they emphasize entailment. Given a set of axioms and assertions, the engine determines what must logically follow. This method often appears in ontology-driven systems and semantic web technologies. It can provide strong assurance around soundness and consistency. One caveat is the cost stemming from computational complexity, especially when the logical language becomes highly expressive.
Datalog-Based
Datalog-based engines situate between production systems and full logical reasoners. Datalog restricts expressiveness in order to guarantee decidability and efficient evaluation. These restrictions make Datalog particularly well suited for recursive reasoning over graph structures. Transitive closure, reachability, and multi-hop inference can run efficiently under a bottom-up evaluation model. Because of these properties, many graph-native reasoning systems adopt Datalog-style evaluation internally, even if they expose a higher-level query interface.
Probabilistic Engines
Probabilistic reasoning engines extend symbolic logic into uncertain domains. They don’t derive facts as strictly true or false but compute likelihoods, for example, Bayesian networks and Markov logic networks. These systems model incomplete or noisy information and support inference over probability distributions. They are valuable when certainty is unrealistic, but they introduce additional computational cost and interpretability challenges.
Hybrid Methods
Modern AI architectures increasingly adopt hybrid reasoning models. In these systems, neural components extract structured signals from unstructured input. A symbolic reasoning layer then applies rules or logical constraints to enforce domain correctness. By dint of the separation, teams can combine statistical generalization with deterministic assurances. It also lessens the risk of propagating hallucinated or inconsistent outputs into downstream systems.
The next section examines two fundamental inference strategies that many of these engines rely on: forward chaining and backward chaining.
Forward Chaining vs Backward Chaining
Forward Chaining
Here, the engine begins with known facts and continuously applies rules to derive additional facts. Each new inference becomes part of the working memory and may trigger further rules.
The reasoning process moves forward from premises to consequences.
Consider a simple policy domain. Suppose the system contains these facts:
Purchase(User123, Laptop)
Price(Laptop, 1800)
PremiumCustomer(User123)And here’s the rule:
IF Purchase(U, Item) AND Price(Item, P) AND P > 1000
THEN HighValuePurchase(U, Item)The engine evaluates existing facts, discovers that the rule conditions hold, and derives:
HighValuePurchase(User123, Laptop)If another rule depends on HighValuePurchase, the engine evaluates that rule next. The inference chain continues until no additional rules activate.
You will see forward-chaining in use in systems that must continuously react to incoming data. Event processing, monitoring systems, and compliance checks often rely on forward chaining because the engine automatically propagates new facts through the rule network.
Many production rule engines therefore adopt forward chaining with incremental evaluation networks such as Rete or Treat. These structures allow the engine to propagate only the changes new or updated facts bring about.
Forward chaining may produce many derived facts that no query ever requests. In large systems, therefore, it can increase memory usage and computation expenses.
Backward Chaining
Backward chaining takes the obverse approach: it doesn’t derive every possible conclusion but begins with a query and works rearward to ascertain whether the required facts can be proven.
The engine treats the query as a goal and searches for rules whose conclusions match that goal. It then evaluates whether the rule’s conditions can be satisfied.
For example, suppose the system receives a query to ascertain whether a specific user is eligible for discount.
The engine finds a rule that defines eligibility:
IF PremiumCustomer(U) AND HighValuePurchase(U, Item)
THEN EligibleForDiscount(U)The engine now treats the rule conditions as sub-goals. It checks whether PremiumCustomer(User123) exists and whether HighValuePurchase(User123, Item) can be derived. If another rule defines high-value purchases, the engine evaluates that rule next.
This recursive search continues until the system either proves the goal or determines that no rule chain can satisfy it.
Backward chaining is employed in selective and unpredictable queries. Instead of computing every possible inference ahead of time, the engine derives only what the query requires.
Logic programming languages such as Prolog rely heavily on backward chaining. Query planners in certain logical databases also follow a similar strategy.
Now, when it comes to choosing between the two, system designers must consider the form of their workload. Data-heavy pipelines with frequent updates often benefit from forward inference because new knowledge propagates automatically. Query-driven workloads may favor backward chaining, since the system avoids computing unnecessary conclusions.
Some reasoning engines go the hybrid way: they may materialize commonly used inferences using forward reasoning while resolving rare queries through backward evaluation.
Reasoning Engine Architecture
The architecture allows for a coordinated system of components that manage knowledge, execute inference, and maintain consistency as data evolves, with separation of concerns so the system can scale and remain maintainable.
Most production reasoning engines follow a layered architecture with a few core subsystems.
Knowledge Base
The knowledge base stores the information the engine reasons over. It usually contains two marked elements: asserted facts and inference rules.
Facts represent the current state of the domain. In many modern systems they appear as graph relationships, structured predicates, or schema-bound entities. These facts form the foundation for all reasoning.
Rules encode the logical relationships that produce new knowledge. They may appear as production rules, logical implications, or Datalog clauses depending on the system design. The knowledge base therefore defines what the engine knows and how it should reason about it.
In graph-oriented environments, the knowledge base often maps naturally to a graph structure, where nodes represent entities and edges represent relationships. Rules can then operate over multi-hop patterns in the graph. Historically, working this way often required moving data through ETL pipelines into a dedicated graph database first. Tools like PuppyGraph have made that model far more accessible by letting teams query structured data as a graph directly, which makes performant multi-hop analysis possible at scale without the usual infrastructure overhead.
Working Memory
Working memory holds the facts that take part in active reasoning. While the knowledge base defines persistent knowledge, working memory represents the current reasoning state.
When the engine acquires a new fact, it inserts that fact into working memory. This updated state may trigger additional rules, subsisting the inference process.
Efficient working memory management becomes really important as the number of facts grows. Engines typically index facts by predicate or relationship type to allow rule matching without scanning the entire dataset.
Inference Engine
The inference engine performs the actual reasoning. It evaluates rules against the facts in working memory and ascertains when new conclusions should be produced.
Internally, this component performs several responsibilities. It matches rule conditions against current facts, schedules rule activations, settles conflicts between competing rules, and executes the selected rule to create new knowledge.
To maintain performance at scale, many reasoning engines compile rules into optimized evaluation structures. Pattern matching networks such as Rete or its variants allow the system to reuse intermediate matches.
Agenda and Control Strategy
During reasoning, multiple rules may become eligible for execution at the same time. The architecture therefore includes an agenda or control layer that decides which rule should fire next.
The agenda maintains a queue of pending rule activations. Selection policies determine execution order. Some systems rely on rule priorities, while others prefer recency-based or specificity-based scheduling. This control mechanism makes certain deterministic behavior when multiple inference paths exist.
Without this scheduling layer, rule interactions could become unpredictable, especially in large rule bases.
Truth Maintenance and Dependency Tracking
Derived knowledge often depends on multiple supporting facts. If one of those facts changes, the engine must update any conclusions that relied on it.
So there are mechanisms for tracking those veracities. When a base fact is retracted or modified, the system identifies all derived facts that depend on it and recomputes or removes them. This prevents outdated conclusions from remaining in the system.
Truth maintenance becomes especially important in streaming or real-time environments where facts evolve continually.
Persistence and Integration Layer
Many modern reasoning engines operate as part of larger data platforms. They therefore include integration layers that connect the inference engine to external storage systems, APIs, or data pipelines.
In some architectures the reasoning layer operates directly on top of a graph database. In others it maintains a separate reasoning store and synchronizes with external data sources. The design choice depends on latency requirements, data volume, and system complexity.
This layer allows the reasoning engine to participate in broader application workflows and not persist as an isolated component.
Integration with Knowledge Graphs and AI Models
Modern systems integrate reasoning engines with knowledge graphs and AI models to compound structured inference with machine-driven pattern recognition. That way, systems can reason over connected data while processing large volumes of unstructured information.
Reasoning Over Knowledge Graphs
Knowledge graphs provide a natural substrate for reasoning engines. Graph structures represent entities and relationships explicitly, so inference rules can operate directly on connected data.
In a graph environment, facts often appear as triples or property graph relationships. For example, a graph might contain relationships such as:
(Alex) -[:WORKS_FOR]-> (CompanyX)
(CompanyX) -[:LOCATED_IN]-> (Germany)A reasoning rule can derive additional knowledge from these relationships:
IF Person(X) WORKS_FOR Company(Y)
AND Company(Y) LOCATED_IN Country(Z)
THEN Person(X) WORKS_IN Country(Z)The reasoning engine evaluates motifs across graph paths and obtains new relationships, an ability especially valuable in systems where meaningful insights depend on multi-hop connections.
Graph-backed reasoning supports scenarios like dependency analysis, fraud detection, recommendation systems, and supply chain visibility. In each case, the engine derives conclusions from indirect relationships that span several entities.
Another advantage of graph integration is that inference can enrich the graph itself. Derived relationships may be stored alongside original data, allowing subsequent queries to operate on both asserted and inferred knowledge.
Combining Reasoning with Machine Learning
AI models typically produce probabilistic outputs and not deterministic knowledge. Reasoning engines provide the structured layer that interprets those outputs.
We can think about an example architecture like so:
An AI model processes raw input, such as text, logs, or documents, and extracts structured signals. These signals become facts in the reasoning system. The reasoning engine then applies rules or logical constraints to derive additional conclusions or enforce domain policies.
For example, an LLM might extract entities and relationships from a document. Once converted into structured assertions, a reasoning engine can determine whether those relationships violate compliance policies or imply additional dependencies.
By dint of such separation, each component focuses on what they do best.
Reasoning in AI System Pipelines
When integrated into modern AI pipelines, reasoning engines oftentimes act as an intermediary decision layer. Data flows from ingestion systems into structured stores or knowledge graphs. AI models enrich the data with extracted signals. The reasoning engine then assesses rules that interpret those signals within the domain’s logical framework. Identity resolution, recommendation engines, and cybersecurity analysis are some of the use cases this architecture becomes really beneficial, as they all rely on relationships that stretch beyond individual data points.
Affixing Symbolic and Statistical Intelligence
The integration of reasoning engines with knowledge graphs and AI models bespeaks a broader trend in system design; modern platforms increasingly combine symbolic reasoning with statistical learning.
Symbolic reasoning provides blunt structure, traceable logic, and deterministic decision paths. Machine learning provides pattern recognition and pliancy to unstructured data. In concert, they institute a complementary system.
As AI deployments grow more composite, this hybrid architecture allows organizations to move from isolated predictions toward systems that understand relationships, administer rules, and acquire meaningful conclusions from connected knowledge.
Challenges in Building and Scaling Reasoning Engines
Rule Explosion and Interaction Complexity
As reasoning systems grow, the number of rules often grows with them. Each new rule introduces potential interactions with existing rules. These interactions can produce unexpected inference chains or cyclic reasoning paths.
A small set of rules may behave predictably, but hundreds or thousands of rules create a composite dependency network. Engineers must carefully design rule scopes, priorities, and conditions to avoid unintended cascades.
Without clear rule governance, the system may generate redundant inferences, conflicting conclusions, or excessive rule activations; combination of many rules and many facts produces a rapidly expanding set of derived knowledge.
Performance and Computational Cost
Reasoning can be computationally expensive because it often involves repeated pattern matching over large datasets. Each rule condition may require joins across multiple facts, especially in graph-oriented domains where relationships span multiple hops.
Even with optimized pattern matching networks, the cost of evaluating rules grows with the size of the fact base and the complexity of rule conditions. Recursive rules can further increase computational load because the engine must repeatedly evaluate intermediate results until no new inferences appear.
Managing Incremental Updates
Real-world data doesn’t remain unvariable. New facts arrive continuously, existing data changes, and outdated information must be removed. A reasoning engine must therefore update its derived knowledge without recomputing the entire inference space from scratch.
Incremental reasoning addresses this problem by updating only the parts of the inference graph affected by a change. However, implementing incremental updates requires you to cautiously track dependencies. If the system cannot determine which derived facts depend on which base facts, it may need to recompute large portions of the rule network.
This challenge becomes more pronounced in streaming environments where data updates occur at high frequency.
Maintaining Consistency and Correctness
Large reasoning systems must guard against inconsistent conclusions. Conflicting rules, incomplete knowledge, or changing inputs can lead to contradictions in derived knowledge.
For example, one rule might infer that an entity qualifies for a certain status, while another rule invalidates that status under a different condition. Without clear conflict resolution strategies, the engine may oscillate between competing conclusions.
Scaling Across Distributed Systems
Modern data platforms often operate across distributed infrastructure. Reasoning engines must therefore handle data partitioning, network latency, and synchronization between nodes.
Distributing reasoning tasks across multiple machines introduces more complication. Some inference rules require access to facts that reside in different partitions of the data graph. Coordinating inference across distributed nodes can increase communication overhead and complicate consistency guarantees.
Conclusion
As AI systems grow more complex, purely statistical models often need a complementary layer for logic, consistency, and explicit knowledge. Reasoning engines fill that role by turning static facts into actionable conclusions through formal inference.
To add more context to the reasoning engine, graphs used as a knowledge base provide an AI-readable view of underlying data, making relationships, entities, and rules easier for intelligent systems to interpret and work with. PuppyGraph makes it easier to get started by letting teams build that graph layer directly on top of existing structured data, without ETL or a separate graph database.
Want to try it out for yourself? Explore the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Matt is a developer at heart with a passion for data, software architecture, and writing technical content. In the past, Matt worked at some of the largest finance and insurance companies in Canada before pivoting to working for fast-growing startups.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install