

Attack Surface Management: Complete 2026 Guide

Every organization has an attack surface. Think domains and subdomains, web apps and APIs and cloud services. It is the full set of points an attacker could potentially exploit. This surface changes quickly as teams ship features, spin up resources, and adopt new tools. It becomes hard to track.
Attack Surface Management (ASM) helps by giving security teams an outside-in view that mirrors how attackers find a target. It continuously discovers assets, attributes them to the right owners, monitors for risky changes, and drives fixes you can verify. Done well, ASM turns a scattered set of findings into a live inventory with clear priorities and accountable workflows.
This blog explains what ASM is, why it matters, how it works, and what to look for in a tool. We will cover core capabilities, common challenges, and practical ways to keep noise low and remediation fast. From there, we show how tools like PuppyGraph take ASM a step further, using graph analytics to focus effort on what is truly reachable and risky.
What Is Attack Surface Management?
ASM creates the source of truth for what exists and who is responsible. By identifying what might be at risk, ASM informs organizations on where to focus their efforts to reduce their attack surface, leaving fewer vulnerabilities to exploit. But what is an attack surface, and how do we manage one?
What Is an Attack Surface?
An attack surface is the set of ways an attacker can interact with your organization’s systems, data, and people. It changes as you ship features, add vendors, and spin up cloud resources. Keeping it manageable starts with knowing which surfaces you have.
The three broad categories of attack surfaces include:
- External attack surface: All internet-facing assets such as domains, web apps, APIs, cloud services, SaaS tenants, certificates, and public storage.
- Internal attack surface: Assets reachable from inside your network or with authenticated access, including internal services, data stores, CI/CD, devices, and identity systems.
- Social engineering attack surface: People and processes that can be manipulated. Common tactics include phishing, baiting, and impersonating.

Managing an Attack Surface
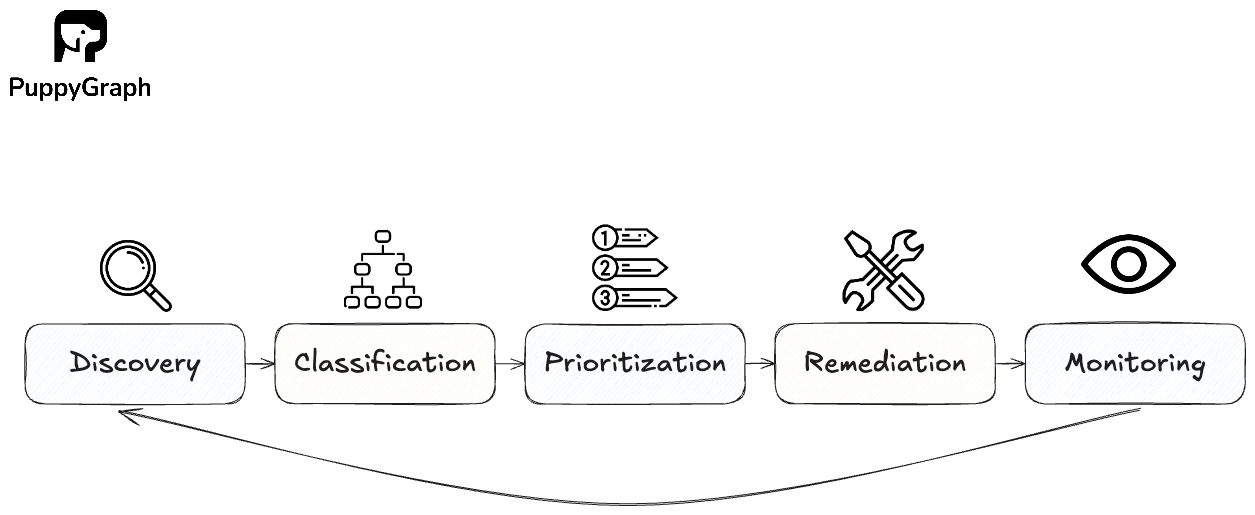
The goal of ASM is to improve security posture by shrinking the attack surface so there are fewer avenues for attackers to infiltrate your systems. You do this with a simple loop that keeps unknowns low, exposures short-lived, and ownership clear:
- Discovery: Find exposed assets from seeds like legal names, domains, cloud accounts, and SaaS tenants.
- Classification: Label assets by type, environment, owner, and data sensitivity so you know what matters and who is responsible.
- Prioritization: Rank findings using estimates of exploitability, reachability, business criticality, and exposure age.
- Remediation: Route fixes to owners with SLAs. Automate safe changes where possible and verify before closing.
- Monitoring: Watch for drift, new assets, expired certs, and regressions. Re-scan to confirm fixes and keep exposures short-lived.
Types of Attack Surface Management
ASM serves as a blanket term for this workflow of discovery, classification, prioritization, remediation and monitoring. But depending on the exact type of attack surface you’re looking to protect, the specific ASM tool might differ.
Here are some common types of ASM:
- External ASM (EASM): Focuses on external, internet-facing assets
- Internal ASM (IASM): Focuses on internal assets and risks
- Cyber Asset ASM (CAASM): Provides a comprehensive, unified view by combining both internal and external asset data
Why Attack Surface Management Matters
Your attack surface grows every day. Without ASM, it’s tough to see what you have, let alone fix what matters. Let’s look at why it’s so hard to keep track and how ASM helps.
Fragmented Environments
Cloud, AI, SaaS, and on-prem environments split visibility across accounts, regions, and tools. Changes land inconsistently, which creates configuration drift over time. Vulnerabilities slip through as security teams lack a clear view of what exists. ASM builds a single source of truth that unifies assets, surfaces duplicates, spots shadow services, and links each asset to the right team. Blind spots shrink and follow-up work reaches the people who can actually fix it.
Constant Changes
Cloud resources appear and disappear quickly, which makes gaps easy to miss. VM sprawl results in forgotten instances that miss critical patches and updates. They turn into blind spots where attackers can hide, and you may not even realize they exist. An attacker can also spin up a VM, run a malicious command, and tear it down between scans. Short-lived services evade schedules, while configuration drift quietly reopens old issues. ASM adds continuous discovery and monitoring so these changes are caught sooner, routed to the right owners, and verified after the fix.
Audit Gaps and Third-Party Risk
Audit gaps often come from not knowing what exists. Without a comprehensive inventory, you cannot prove that required controls cover every asset, and you cannot show which resources fall outside your framework. Shadow IT and newly added cloud environments make this worse, since tenants, accounts, and services may sit outside standard policies. ASM pulls these into one inventory, assigns owners, and tracks basic status so you can map assets to specific control requirements.
Core Capabilities of ASM
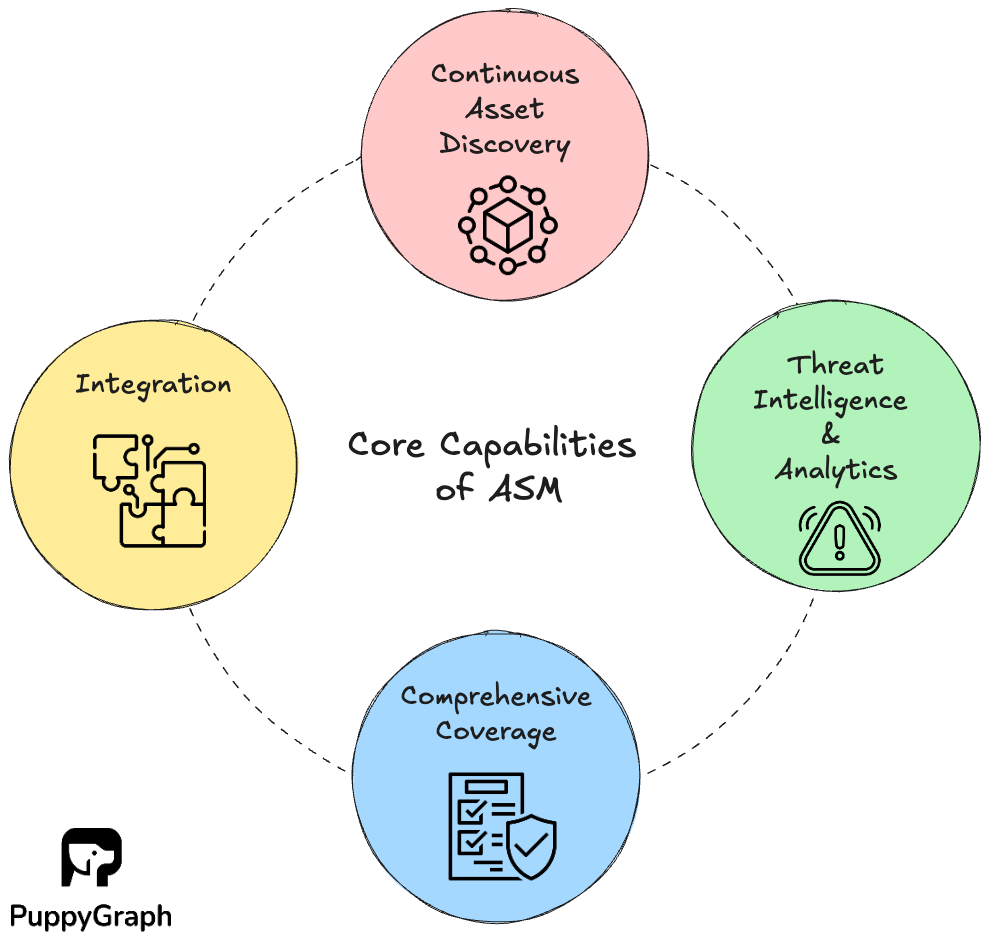
Effective Attack Surface Management gives your organization a unified view of its resources and steadily shrinks what is exposed. The program keeps the inventory current, ties assets to owners, and prioritizes work so teams protect business-critical systems first.
- Continuous asset discovery: Live inventory across cloud, on-premises, and third-party estates. Built from sources of truth and public signals, normalized and deduplicated so each asset appears once with an owner.
- Risk prioritization with threat intelligence and analytics: Ranking based on exploitability, reachability signals, business context, data sensitivity, and active-abuse intel.
- Comprehensive coverage: A unified view of assets from the environments you care about. This can include internet-facing assets, internally reachable services, and cloud resources.
- Integration: Connections to cloud and SaaS APIs, ticketing, SIEM, VM, and CSPM so inventory and findings fit into existing workflows. APIs for export and reporting.
Benefits of ASM
Unified Visibility Across Environments
A single inventory pulls assets from your scattered environments into one view. Duplicate entries collapse, shadow services surface, and each asset links to a clear owner and environment. With that inventory, teams can render an asset graph that shows how domains, apps, APIs, storage, and identities connect, making the attack surface easy to see and explore. Working from the same source of truth, rather than reconciling scattered lists, makes follow-ups faster and less error-prone.
Shorter Exposure Windows
Continuous checks spot risky changes quickly and send them to the team that owns the asset. Small, reversible issues like expired certificates, orphan DNS, and leaked keys can be automated, which removes delays. A quick re-scan confirms the fix. The net effect is less time for attackers to find and use a weakness.
Faster Prioritization
Initial severity uses quick signals like exploitability, provisional reachability, criticality, and exposure age so teams know what to tackle first. Duplicate findings collapse into one item, and unknown-owner issues are flagged for fast review. Tools that add graph context lift items with real paths to sensitive data or privileged roles, so the top of the queue reflects actual risk.
ASM vs Traditional Vulnerability Management
Attack Surface Management maps what’s exposed and who owns it so you can reduce unknowns and shrink exposure. Traditional Vulnerability Management focuses on finding and fixing software flaws on managed hosts. Let’s break down where they differ and how they fit into your program.
How Attack Surface Management Works
ASM runs on a straightforward loop: discover assets, assess and prioritize risk, remediate, then monitor. Let’s review it step by step.
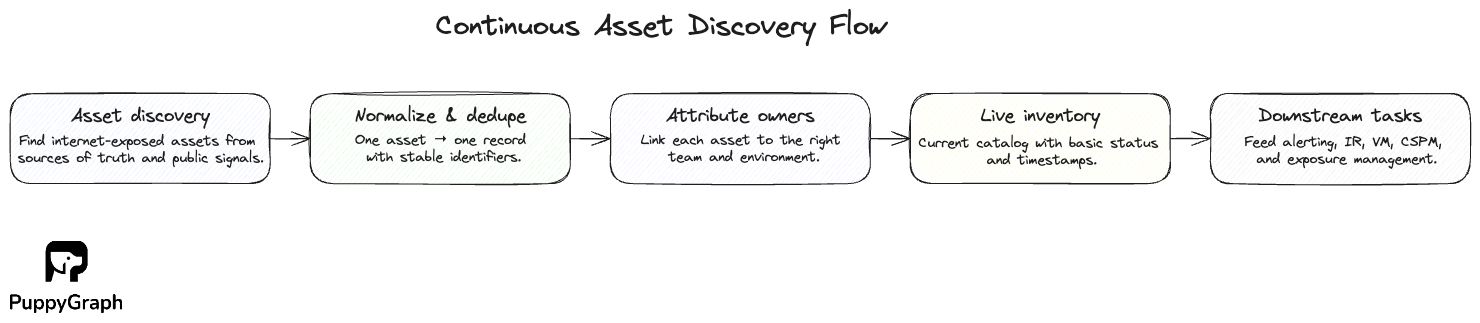
Continuous Asset Discovery
An ASM tool builds a live inventory of your internet-exposed assets, normalizes and deduplicates records so each asset appears once, and attributes ownership to the right teams and environments. Starting from trusted seeds and public signals, discovery expands to related domains, apps, APIs, and storage, then rolls everything into a single, consistent catalog. The result is a comprehensive view of security assets that serves as the foundation for downstream cybersecurity tasks, from alerting and incident response to vulnerability management, CSPM, and exposure management.
Risk Assessment and Prioritization
ASM uses fast signals to set an initial severity so teams know what to tackle first. Duplicate findings collapse into a single item, low-confidence results are flagged, and unknown-owner issues move to the front for review. Many platforms are adding context-aware ranking with graph analysis, lifting items with proven paths to sensitive data or privileged roles. The outcome is a shorter queue that reflects real impact.
Remediation
Findings are turned into issues with clear owners and SLAs, with ASM tools tracking the progress through to verified fix. Tickets are created for the team that runs the asset, with the context needed to act. Closure follows a re-scan or control check so the fix is confirmed, not assumed. Limited, reversible auto-remediation is supported for narrow cases like expired certificates, orphan DNS, and leaked keys.
Continuous Monitoring
ASM is not a one-off thing. After assets are identified and fixes land, ASM tools continue to monitor those resources for vulnerabilities, weak configurations, and potential entry points. This lets issues get flagged quickly or fixed automatically when safe to do so. Event signals from cloud and SaaS providers, DNS and certificate changes, and edge or gateway updates keep the inventory current between scans. With a normalized inventory, teams can render an asset graph to watch how endpoints, identities, and data stores connect.
Common Challenges & How to Overcome Them
Even with a solid ASM program, teams hit predictable hurdles. Understanding what typically goes wrong and concrete ways to fix it helps effort stay focused on the assets that matter most.
Resource Limitations
Keeping an accurate inventory is hard when assets are added, removed, or changed without a trail. Mergers and acquisitions, subsidiaries, and third-party software make it messier. With such large attack surfaces, you can’t protect everything equally. A better approach is to give stronger controls to what matters most, like PII routes, crown-jewel systems, and high-impact services. Pushing uniform controls across the board slows operations and invites corner-cutting. Treat this as an iterative program: start with the critical assets, expand coverage each cycle, and keep refining ownership and controls. A current inventory remains the foundation for finding entry points and closing them.
Dynamic and Expanding Attack Surface
Cloud services, IoT, and third-party integrations change constantly, so point-in-time scans go stale. Automate discovery and monitoring so new endpoints, config drift, and forgotten VMs are caught quickly. Use an asset graph to visualize relationships and flag likely attack paths before they are used.
Limited Context for Risk Assessment
Knowing an asset exists isn’t enough. You need business impact, data sensitivity, and real reachability to rank work. A CTEM-style loop keeps fixes aligned to business goals. An attack graph adds the missing context by mapping paths to crown-jewel systems and measuring blast radius. With graph analytics, you can see which exposures sit on real paths to sensitive data or privileged roles and tackle those first. Prioritization aligns with the business, and fixes drive visible risk reduction instead of scattered one-offs.
Choosing the Right ASM Tool
Here’s a quick checklist to consider the best ASM tools for your needs:
- Discovery depth and frequency: Continuous discovery with near real-time updates is preferred. Mix passive recon, active scans, cert and DNS monitoring to build a complete and accurate inventory.
- Asset coverage: Handles the assets you care about across hybrid and multicloud. Domains, subdomains, IPs, cloud services, APIs, certs, SaaS, and external services.
- Risk context and scoring: Scoring that blends exploitability, reachability, threat intel, and business importance. They should be tunable to your risk tolerance.
- Integrations and workflow: Make sure it plugs into where you scan and where you work. For scanning, this includes APIs for cloud, SaaS and WAFs. For workflow, SIEM, SOAR, VM, CSPM, and ticketing.
- Change detection and history: Near real-time alerts on high-risk changes with a timeline of what changed and when.
- Deployment and automation: Fast onboarding, sane authentication and network requirements, with cloud or on-prem options. Support for automations on small, reversible fixes.
How PuppyGraph Helps
ASM gives you a live asset inventory, but most tools still score risk without enough context. An attack graph fixes that, but building one usually means ETL into a separate graph database, a second data copy, and delay. For teams that need real-time answers, ingest and scale constraints get in the way. That’s where PuppyGraph comes in.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Attack Surface Management gives you a single, live view of what exists, who owns it, and where it is exposed. As your footprint grows across cloud, SaaS, and on-premise, this foundation is what shrinks blind spots and keeps remediation focused where it matters most.
Taking the next step means adding context. An asset graph built on top of your ASM data lets you see real paths to crown-jewel systems and measure blast radius, so prioritization reflects actual risk and fixes drive visible reduction instead of scattered one-offs. When you are ready to go beyond discovery and scoring, graph analytics turns your inventory into decisions.
Ready to try it? Download PuppyGraph’s forever-free Developer Edition or book a demo with our team to see path-aware analysis on your data, without standing up a separate graph database.

Jaz Ku is a Solution Architect with a background in Computer Science and an interest in technical writing. She earned her Bachelor's degree from the University of San Francisco, where she did research involving Rust’s compiler infrastructure. Jaz enjoys the challenge of explaining complex ideas in a clear and straightforward way.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install