

Context Graph: Definition, Architecture, Use Cases
Your AI system retrieves the right documents, but still gives wrong answers. The data is there, scattered across your data warehouse, your CRM, your event logs, Slack threads, and tribal knowledge, but the model has no way to understand how those pieces connect. That missing connective tissue is exactly what a context graph provides.
A context graph organizes entities, relationships, and operational metadata into a queryable structure that artificial intelligence systems can traverse for grounded, multi-hop reasoning. Unlike flat retrieval pipelines, it captures not just what your data says, but how it fits together and why it matters in a specific decision.
This guide covers what a context graph is, how it works, how it compares to a knowledge graph, and where it fits in modern AI architectures.
What Is a Context Graph?
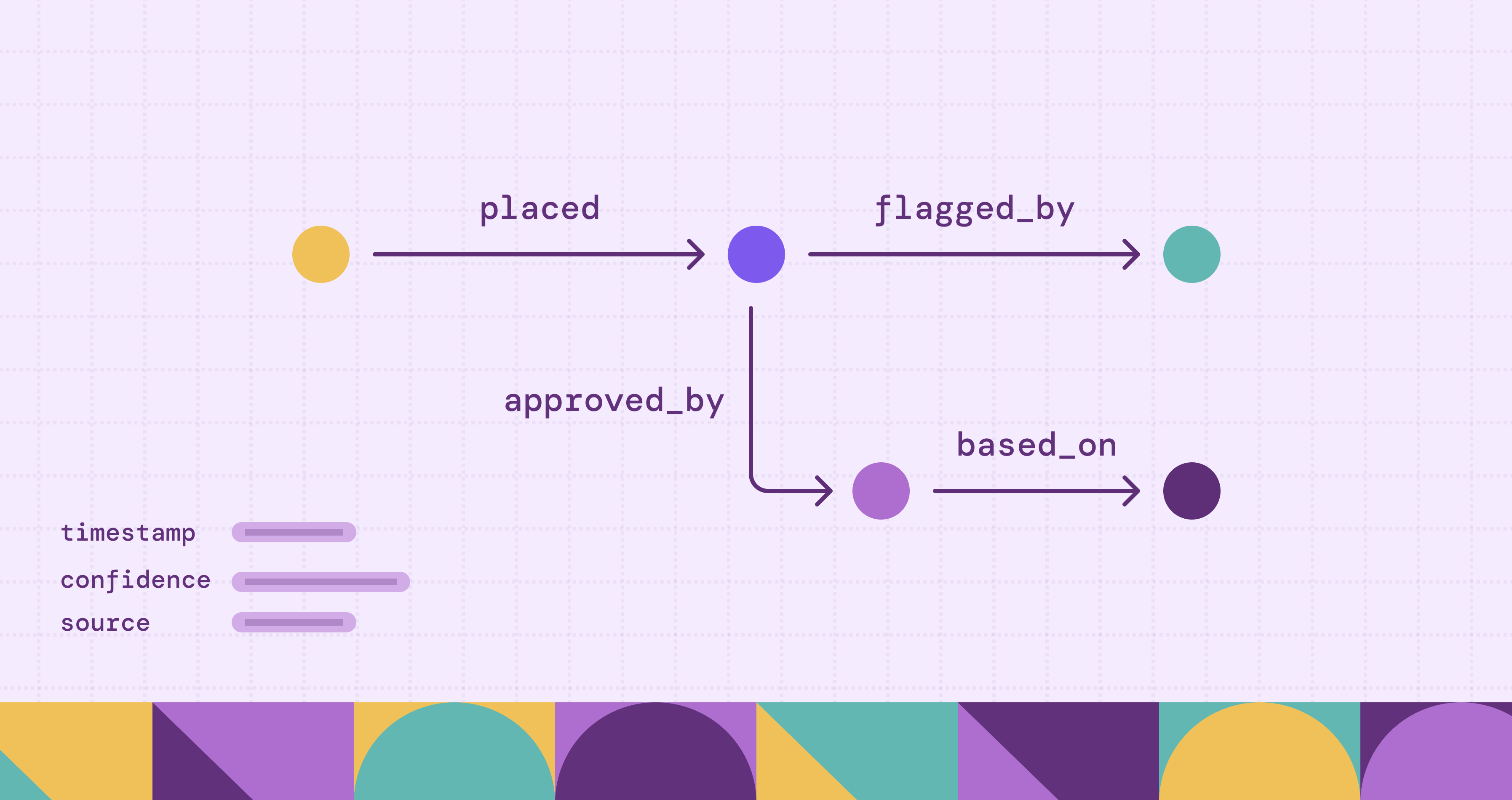
A context graph is a structured representation of entities, their relationships, and the contextual metadata that explains how those entities interact within a specific domain or decision flow. Every node represents something meaningful (a customer, a transaction, a code commit, a support ticket) and every edge represents a typed relationship (purchased, authored, depends_on, escalated_to).
What sets a context graph apart from a standard property graph is the inclusion of operational context. Each node and edge can carry contextual information like timestamps, confidence scores, source provenance, and governance rules. This makes the graph more than a static picture of your domain. It becomes a living record that can answer questions like "Why was this transaction flagged?" or "What downstream systems does this schema change affect?"
The practical difference matters. A traditional data model tells you that Customer A placed Order B. A context graph tells you that Customer A placed Order B, which was approved by Agent C despite exceeding the standard credit threshold, based on a searchable precedent from similar cases in Q3. Those decision traces stitched across nodes and edges are what make context graphs useful for AI systems that need grounded, explainable outputs.
The concept gained traction after Foundation Capital's late-2025 essay calling context graphs AI's trillion-dollar opportunity by Jaya Gupta and Ashu Garg, and subsequent follow-ups in early 2026 describing context graphs as the systems of record for decisions and the "missing layer" for enterprise AI. Since then, context graphs have moved from concept to early implementations and pilots, especially in agentic workflows, financial services, and cybersecurity.
Why Context Graphs Matter in AI and Data Systems
Most AI failures are not model failures. They are context failures. An LLM generates a plausible-sounding answer because it retrieved a relevant text chunk, but it lacked the full context to understand that the information was outdated, applied to a different customer segment, or contradicted by a more recent policy change. Vector search finds similar documents. It does not find connected reasoning. Most companies still struggle with basic data unification across these sources, let alone the semantic understanding needed for more sophisticated reasoning processes.
Context graphs solve this by making relationships queryable. Instead of feeding an AI model a flat list of retrieved passages, a context graph lets the model traverse structured paths between entities, following typed edges that encode business logic, temporal ordering, and causal chains.
Three capabilities make this valuable.
Multi-hop reasoning becomes tractable. Questions like "Which suppliers are connected to both flagged transactions and sanctioned entities?" require traversing multiple relationship hops. In a relational database, this means recursive joins that grow expensive as the hop count increases. In a context graph, it is a native traversal, often simpler to express and significantly faster for relationship-heavy queries.
Context assembly becomes dynamic. Rather than pre-computing every possible context window, a context graph lets AI systems assemble context at decision time by traversing outward from a starting node. With a federated approach (using data sources directly, rather than ETL-ing the data into another database), context stays closer to real-time because graph queries against the underlying data sources are executed directly rather than relying on stale copies.
Decisions become traceable. Because relationships are modeled explicitly, you can inspect which nodes and edges contributed to an answer. This creates audit trails that make provenance easier to surface than with embedding-based retrieval alone, especially when combined with logging and decision lineage tracking.
This matters most in enterprise environments where data lives across many systems. In real workflows, a single renewal decision might require context from CRM records, support ticket history, usage analytics, billing data, and contract terms, each stored in a different system. Traditional approaches require copying all this data into a single store before you can reason across it. A federated graph query engine like PuppyGraph connects to each data source directly and exposes a unified graph layer, with zero ETL and without the staleness that comes with data duplication.
Core Components of a Context Graph
A context graph is built from four fundamental building blocks that work together to represent both the structure and the meaning of your data.
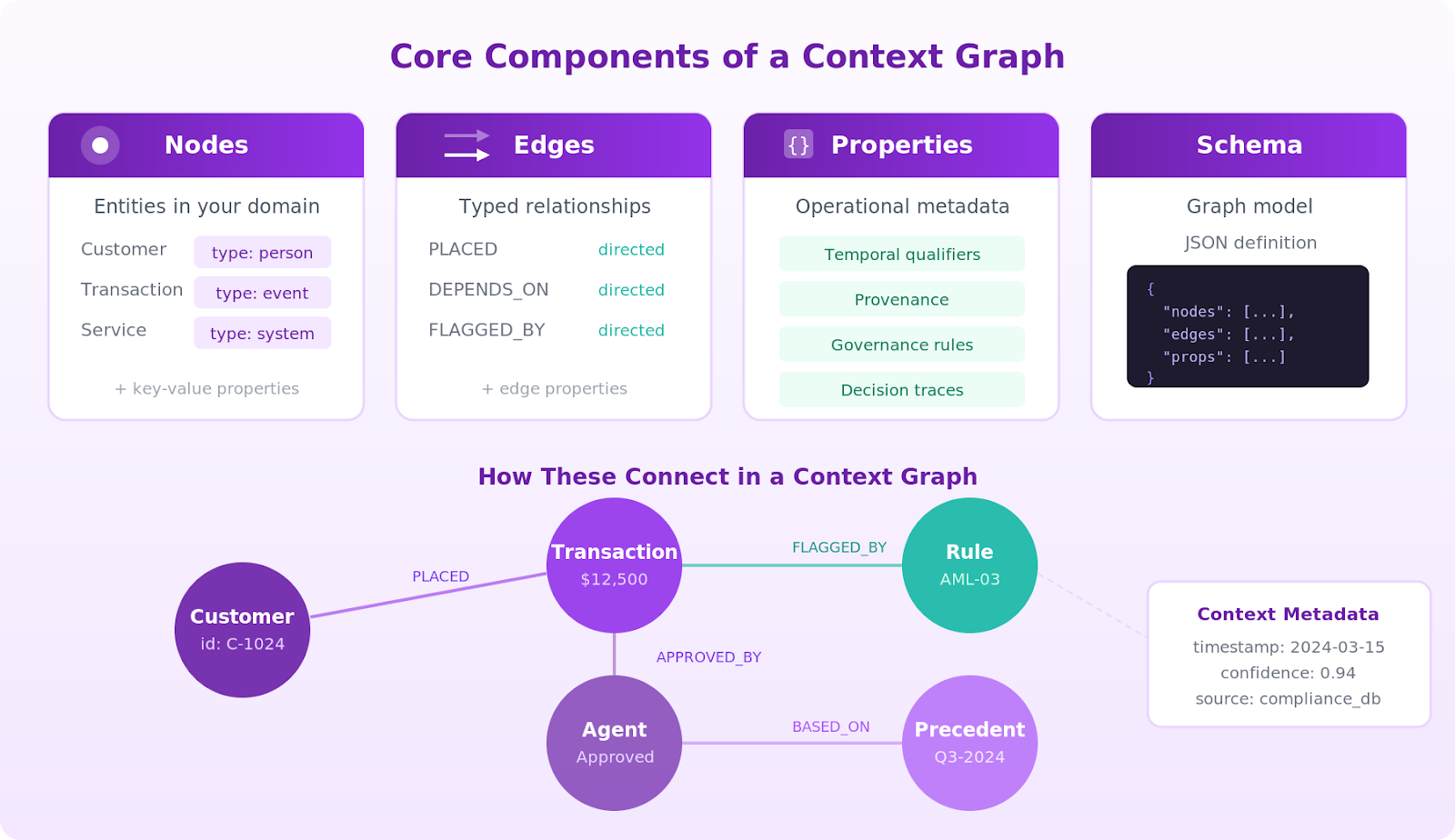
Nodes (Entities)
Nodes represent discrete objects in your domain. In a financial context graph, nodes might include customers, accounts, transactions, merchants, and devices. Each node carries a type label and a set of properties (key-value pairs) that describe its attributes.
Edges (Relationships)
Edges are typed, directed connections between nodes. "Customer PLACED Order" is different from "Order ASSIGNED_TO Warehouse." Edges can also carry properties: a "DEPENDS_ON" edge between microservices might include a version constraint, while a "FLAGGED_BY" edge might include a risk score and the rule that triggered the flag.
Properties and Metadata
This is where context graphs diverge from basic property graphs. Edge properties and node properties include operational metadata like:
- Temporal context: Valid-from and valid-to timestamps, transaction dates, or version numbers that allow time-scoped queries
- Provenance: Source system, ingestion timestamp, confidence score, and data quality indicators
- Governance rules: Compliance policies, access controls, and retention rules encoded as queryable properties or separate policy nodes
- Decision traces: Precedent links to approval workflows, exceptions, and past decisions that form a queryable record of how edge cases were resolved
Schema (Graph Model)
The schema defines which node types exist, which edge types connect them, and what properties each carries. In PuppyGraph, for example, graph models are defined through JSON schema files, making it possible to update, version, or switch graph views without touching the underlying data. This separation of schema from storage lets teams iterate on how data is modeled as a graph without migrating the actual data.
How a Context Graph Works
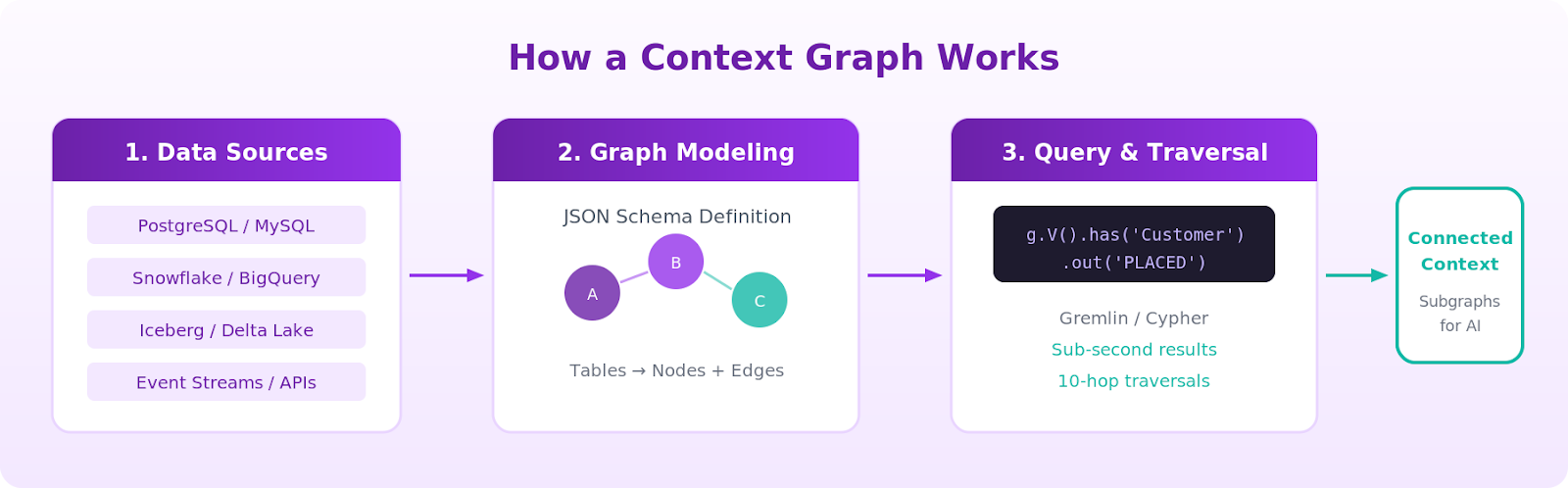
Building context graphs involves three stages: sourcing the data, modeling it as a graph, and querying it for context.
Stage 1: Data Sourcing
Context graph data comes from the systems where it already lives: relational databases, data warehouses, data lakes, event streams, and SaaS APIs. The critical question is whether you copy this data into a separate graph database (ETL) or query it in place (federated).
The ETL approach creates a dedicated graph store, introducing data duplication, staleness, and pipeline maintenance overhead. If your context graph only contains data from two of your ten systems, you have a partial context graph, and partial context leads to partial answers.

The federated approach queries data where it lives. PuppyGraph's virtual graph architecture takes this route: the query planner decomposes graph operations into source-level instructions, applying optimizations like join ordering, traversal pruning, and predicate pushdown. This means the context graph stays closer to real-time without replication lag. PuppyGraph connects directly to PostgreSQL, Snowflake, Apache Iceberg, BigQuery, Delta Lake, and others, exposing a unified graph across all of them.
Stage 2: Graph Modeling
Once data sources are connected, you define a graph model that maps relational structures (tables, columns, foreign keys) to graph structures (nodes, edges, properties). A fraud detection team might model accounts, transactions, devices, geographic locations, and IP addresses as nodes, with edges like SENT_TO, LOGGED_IN_FROM, and ASSOCIATED_WITH. The same underlying data can support multiple graph models for different analytical perspectives.
Stage 3: Query and Traversal
With the graph model defined, context is assembled through graph queries. Languages like Gremlin and Cypher express traversal patterns: "Start at this customer node, follow all PLACED edges to transactions, then follow FLAGGED_BY edges to see which rules triggered." These traversals return connected subgraphs, not isolated rows, giving AI systems structured context with the relationships intact.
PuppyGraph executes these traversals with auto-sharded, distributed computation, handling petabyte-scale workloads and 10-hop queries in seconds. This performance is critical for real-time use cases like fraud detection, where a decision might span millions of connected entities.
Context Graph vs Knowledge Graph
Context graphs and knowledge graphs are closely related, and the distinction matters more in practice than in theory, having been debated extensively since the term gained traction in late 2025. Many teams treat a context graph as an evolution of a knowledge graph: essentially a KG plus time, provenance, and decision traces.
A knowledge graph represents what is. It models entities and their semantic relationships in a structured, machine-readable format. "Customer A is_a Premium_Customer. Premium_Customer has_benefit Free_Shipping." Knowledge graphs excel at encoding domain ontologies, taxonomies, and static facts.
A context graph extends this to represent how and why. It adds the operational metadata, temporal dynamics, and decision traces that make the graph useful for dynamic reasoning. "Customer A was upgraded to Premium_Customer by Agent B on 2024-01-15, based on spending threshold policy P3, which was active from 2023-Q4 through 2024-Q2."
The practical implication for AI systems: a knowledge graph can tell an LLM that "Product X is in Category Y." A context graph can tell the LLM that "Product X was reclassified from Category Z to Category Y by analyst M on date D, because of regulatory change R, which also affected Products P and Q." That additional context reduces hallucination risk because the model has traceable reasoning paths instead of isolated facts, a structural advantage for any AI application requiring explainability.
Some experts find the distinction intellectually compelling but argue that context graphs are simply well-designed knowledge graphs with operational metadata added. That is a fair characterization architecturally, and it is a useful reality check on the hype. In practice, many knowledge graphs focus on semantic structure, while context graphs emphasize decision lineage and provenance from past decisions, but the data models can overlap heavily. The distinction is less about the underlying technology and more about what you choose to model.
What both share is a fundamental requirement: they only work if the graph has access to all relevant data. A knowledge graph built from a single database gives you a narrow slice of truth. A context graph that only covers your CRM but not your support tickets, usage data, and billing systems produces incomplete reasoning. By querying across all data sources without requiring data migration, a federated graph engine ensures full context.
Context Graph in LLM and RAG Architectures
Traditional RAG pipelines chunk documents into text blocks, embed them as vectors, and retrieve the top-k most similar chunks at query time. This works for surface-level questions, but breaks down when answers require connecting information across multiple sources or more sophisticated reasoning processes across relationships between entities.
GraphRAG addresses this by augmenting retrieval with graph structure. The approach gained momentum after Microsoft Research's 2024 paper demonstrated that graph-based retrieval significantly outperformed traditional RAG on complex, multi-hop questions over private datasets. Implementations vary, but the core idea is the same: use graph traversal to retrieve entity neighborhoods and connected subgraphs, or to expand and organize retrieved context along explicit relationship paths.
How a Context Graph Enhances RAG
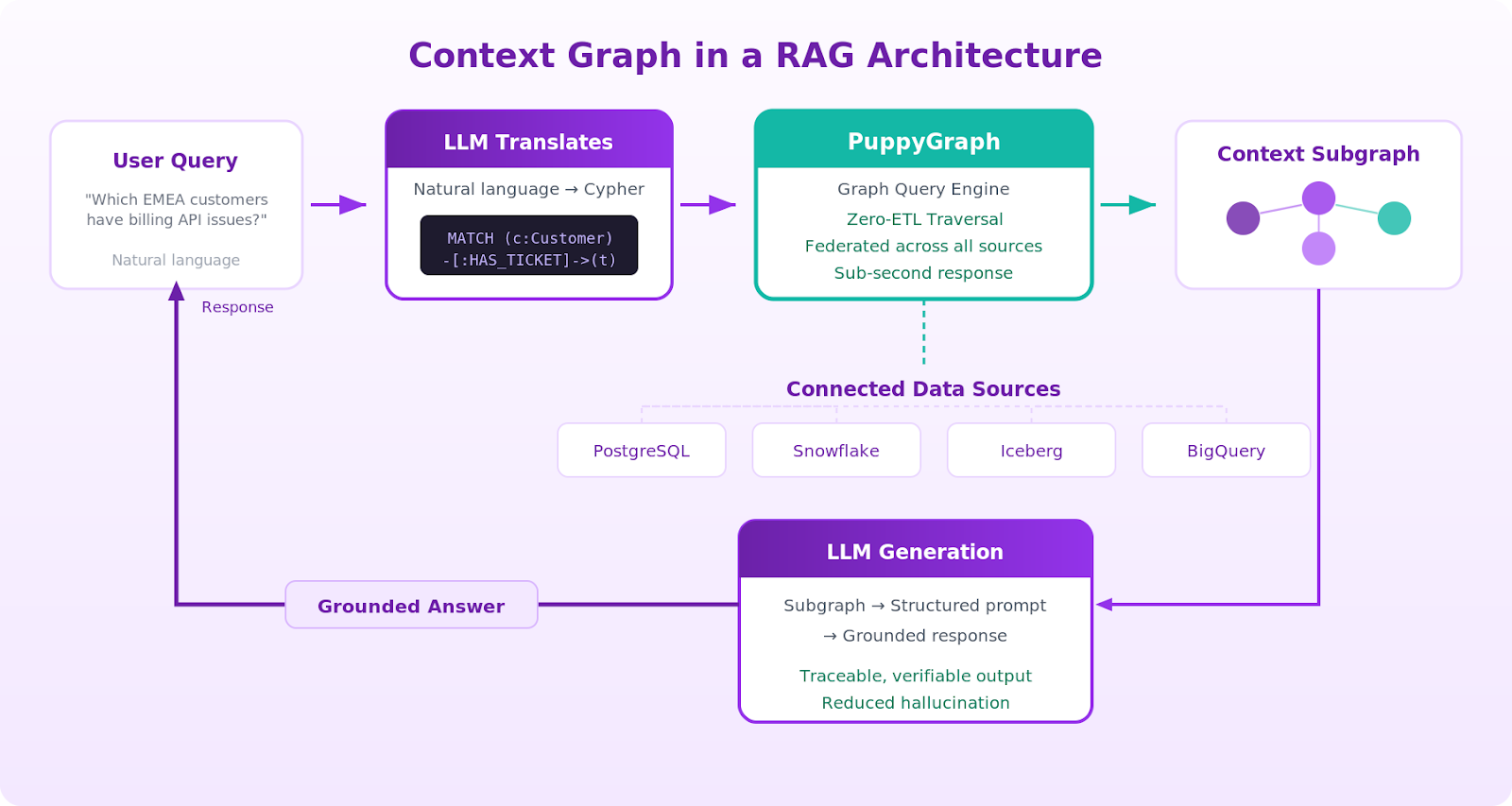
A context-graph-powered RAG pipeline works in three stages:
Graph Sourcing: The context graph is built on top of existing data sources. With PuppyGraph, this means connecting directly to your data lake or warehouse and defining a graph model via JSON schema. No data duplication is required.
Graph Retrieval: When a user asks a question, the system uses an LLM (often with guardrails or templates) to generate a graph query in Cypher or Gremlin. The traversal extracts the relevant subgraph: the specific nodes, edges, and properties that relate to the question. This structural advantage over vector similarity search comes from following explicit relationship paths rather than statistical proximity.
LLM Generation: The retrieved subgraph is serialized and included in the LLM prompt as structured context. The model uses this context to generate its response, with the graph structure providing guardrails against hallucination. Because each piece of context is traceable to a specific node and edge, the output can be verified.
Why This Outperforms Text-Only RAG
Graph queries are more efficient for relational questions. "Which customers in the EMEA region have open support tickets related to our billing API?" would require a text-only RAG system to retrieve and process dozens of document chunks. A graph traversal answers this directly by starting at the "billing API" node, following edges to support tickets, then to customers filtered by region.
PuppyGraph's Agentic GraphRAG capabilities serve as an agent orchestration layer, integrating with large language model frameworks through natural-language-to-Cypher translation. The LLM interprets the user's question and, with schema-aware guardrails, generates the appropriate graph query. PuppyGraph executes it directly on the connected data source, and the results feed back into the LLM for response generation.
In one documented implementation, a Databricks Solution Architect used PuppyGraph to build a GraphRAG system that improved query accuracy from grade 1 to grade 4.8-5 on MLflow evaluation, measured against meta queries requiring multi-hop relational reasoning.
Real-World Use Cases of Context Graphs
Context graph AI applications are being deployed across industries where decision-making depends on understanding relationships between entities distributed across multiple systems.
Fraud Detection and Financial Services
Financial fraud exploits gaps between siloed systems. A fraudster might use one identity across multiple accounts, routing transactions through shell entities that look legitimate individually. A context graph connects these entities into a single traversable structure where multi-hop traversals reveal rings and patterns invisible in tabular data.
PuppyGraph is used in financial services for this: connecting data from multiple sources into a unified graph that enables real-time fraud pattern detection without copying data into a separate graph database.
Cybersecurity and Threat Analysis
A context graph links assets (servers, endpoints, users) to events (login attempts, file access, network connections) and threat indicators (known malicious IPs, vulnerability records). When an alert fires, analysts traverse the graph to understand blast radius: what systems are connected to the compromised asset and what lateral movement paths exist.
PuppyGraph supports cybersecurity use cases by federating across security data sources, giving SOC teams a graph view without data migration.
AI Agent Reasoning and Decision Tracing
As AI agents and semi-autonomous agents take on more complex tasks, humans need tools for tracing and auditing each decision event along the execution path. By capturing decision traces, a context graph records what data an agent consulted, the traversal path it followed, and the reasoning chain that produced its output.
AMD built a Data Intelligence Platform using PuppyGraph that connects tickets, code, logs, and telemetry through graph traversals over Apache Iceberg. Query times dropped from minutes to sub-seconds while scaling to millions of relationships, with ETL eliminated entirely.
Supply Chain and Healthcare
Supply chains are inherently graph-shaped: suppliers connect to components, components connect to products, and products connect to warehouses. A context graph makes these multi-tier relationships traversable, allowing teams to answer questions such as "If Supplier X is disrupted, which finished products are affected?" Similarly, healthcare applications use context graphs for drug interaction analysis, patient journey mapping, and clinical trial matching.
Conclusion
A context graph transforms scattered data into connected, queryable intelligence that AI systems can traverse for grounded reasoning. Context engineering at this level extends the knowledge graph model with operational metadata, temporal awareness, and decision traces, giving AI systems the relational context they need for accurate, explainable outputs.
The key insight is that a context graph is only as complete as the data it can access. If your graph covers one or two of your data sources, your AI models operate with partial context, which leads to partial answers. This is why the federated approach matters: by querying data where it already lives rather than requiring every single system to replicate into a graph database, a federated graph engine keeps your context graph closer to its final state without the staleness and maintenance burden of replicated pipelines.
PuppyGraph is the only graph query engine built for this federated model. It connects directly to your data warehouses, data lakes, and databases, exposes a unified context graph through Gremlin and Cypher, and handles petabyte-scale traversals. Try PuppyGraph's free Developer Edition and start querying in under 10 minutes, or book a demo with our team of graph experts to see it in action.

Matt is a developer at heart with a passion for data, software architecture, and writing technical content. In the past, Matt worked at some of the largest finance and insurance companies in Canada before pivoting to working for fast-growing startups.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install