

GPT vs Neo4j Graph Database Applications: Key Differences
When it comes to generative AI, one of the most common tools is GPT. Over the last few (very short) years, Large language models, or LLMs for short, have become increasingly better at providing answers to their users. LLMs like GPT excel at natural language understanding but struggle with complex relationships and real-time data, an aspect of response generation that is becoming increasingly crucial.
Graph databases like Neo4j store and query connected data efficiently, but can't parse conversational requests and instead require a query language to interact with the data and human expertise to interpret the responses. Combining them through GraphRAG (Graph Retrieval Augmented Generation) uses knowledge graphs to ground AI responses in structured, accurate data. This article explores how GPT and Neo4j work, their key differences, and why using them together delivers better results than either technology alone.
What Is GPT and How It Is Used in Applications

If you are using technologies like ChatGPT or any API built by OpenAI, you're already familiar with GPT and its capabilities. GPT, which stands for Generative Pre-trained Transformer, is an LLM developed by OpenAI that generates human-like text based on patterns learned from massive datasets. The model uses a transformer architecture with billions of parameters trained on diverse internet text, books, articles, and other written content.
Applications integrate GPT via APIs to handle tasks such as content generation, code completion, customer support, and data analysis. When most companies talk about "integrating AI into their products", they are talking about this exactly. The model processes natural language inputs and produces contextually relevant responses, making it useful for chatbots, writing assistants, search interfaces, and automated documentation tools.
When using GPT, it's clear that its strength lies in its ability to understand context and generate coherent responses across many topics. The problem is that it operates on static training data with a knowledge cutoff date; in earlier versions, this was a really annoying problem since training data was many years in the past. While some implementations add internet search capabilities, this only partially addresses the core limitation: GPT doesn't maintain structured knowledge about specific domains or relationships within your organization's data.
The model also struggles with factual accuracy because it predicts probable text sequences rather than retrieving verified information. It can confidently generate incorrect information, a problem known as hallucination. For the most part, GPT will not return an answer containing "I'm not sure" and instead tries to create an answer that makes sense, even if it's not factually correct. For AI applications that require precise answers from complex, interconnected data, GPT alone often falls short. Graph databases, such as Neo4j, can help address this gap.
What Is Neo4j and How Graph Databases Work

Neo4j is a native graph database that stores data as nodes (entities) and relationships (connections between entities). Unlike relational databases that use tables and foreign keys, graph databases directly represent connections as first-class citizens in the data model. For example, the diagram below shows how a graph database like Neo4j would represent the data stored within it:
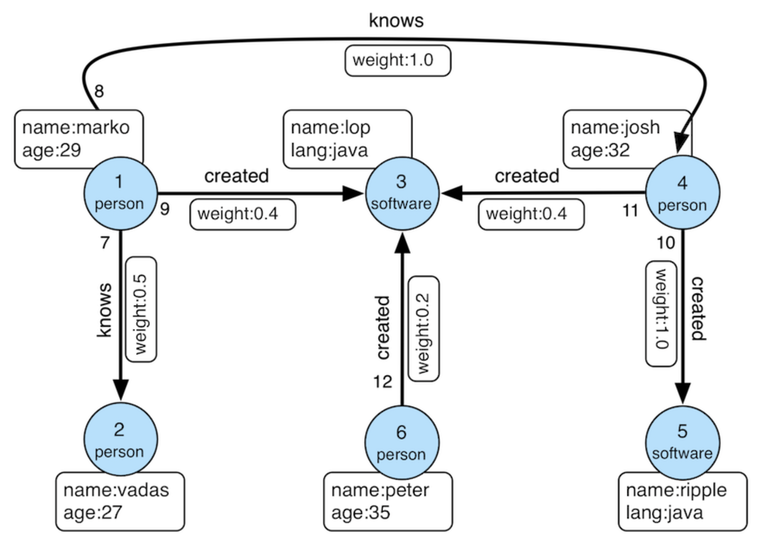
The property graph model in Neo4j consists of nodes with labels and properties, relationships with types and properties, and the ability to traverse these connections efficiently. For example, a knowledge graph might have Product nodes connected to Category nodes, Customer nodes, and Supplier nodes through various relationship types, with properties capturing relevant attributes.
Neo4j uses Cypher, a declarative query language designed specifically for graph traversal. These Cypher statements, or queries, can express complex patterns like "find all customers who purchased products similar to this one and also viewed items from related categories" more naturally than SQL joins. The database optimizes these traversals through index-free adjacency, where each node directly references its connected nodes.
For AI applications, graph databases provide the structured knowledge layer that language models, like GPT, lack. When an AI assistant needs to answer questions about your products, customers, or domain-specific entities, it can query the graph for verified relationships rather than guessing based on training data. Combining natural language understanding from GPT with factual grounding from Neo4j creates more reliable AI systems.
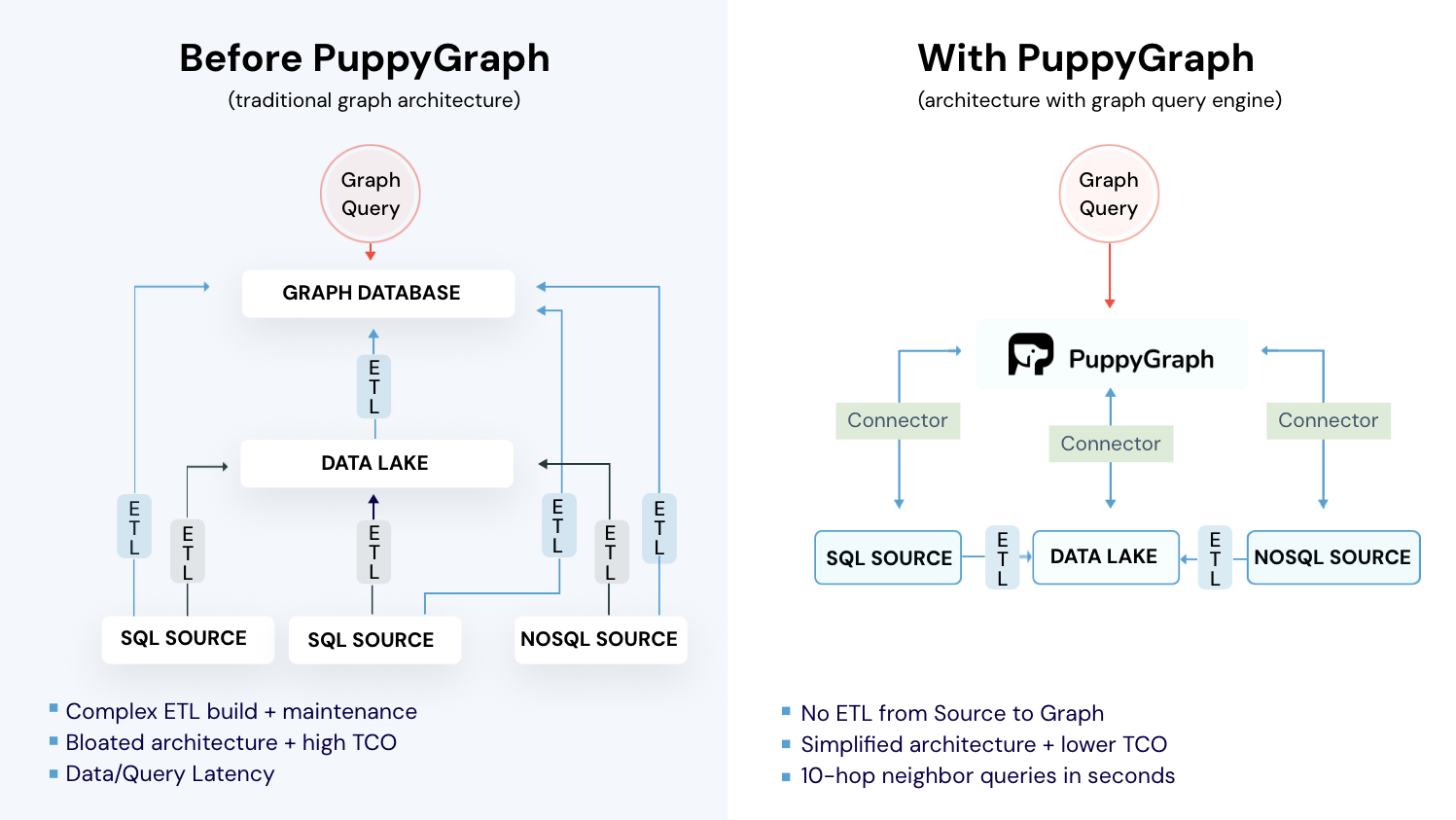
One of the biggest hurdles to using Neo4j and other traditional graph databases is that they require significant upfront investment before they can be used for anything, like graphRAG. To make it operational, you need to extract data from existing systems, transform it into a graph model, and load it into Neo4j. This ETL process takes time, resources, and ongoing maintenance as source data evolves. For organizations with data spread across multiple databases, this becomes a barrier to adopting graph technology for AI applications.
Core Differences Between GPT and Neo4j
GPT and Neo4j serve fundamentally different purposes in AI systems. GPT handles unstructured text and generates natural language responses, while Neo4j manages structured, connected data and executes precise graph queries. Although they can't be directly compared, since they are two very different technologies, we can look at a few aspects to more concretely show the differences. Here are five core areas and the differences between the two technologies:
Data representation differs significantly between the two. GPT encodes knowledge implicitly within neural network weights learned during training. You can't inspect or update specific facts directly. Neo4j stores explicit, structured data as nodes and relationships that you can query, update, and audit. If a customer's address changes or a product goes out of stock, you update that node property immediately. With GPT, you can't selectively update embedded knowledge without retraining.
Query capabilities reflect these architectural differences. GPT accepts natural language prompts and generates probabilistic responses. Neo4j requires structured Cypher queries and returns deterministic results. When you ask GPT, "Who are our top customers in the healthcare sector?", it might generate plausible-sounding names based on patterns from its training data, not your actual customer database. Neo4j executes a query against your real customer graph and returns verified results that an AI can then format into natural language.
Accuracy and reliability create different trade-offs for AI applications. GPT can hallucinate information, especially for niche domains or specific factual questions about your business. It might confidently state incorrect relationships or outdated information. Neo4j returns exactly what's in the database: if the data is accurate, the results are accurate. Graph databases become essential for AI systems where wrong answers damage user trust or business outcomes.
Use case alignment shows where each technology fits in AI architectures. GPT handles open-ended questions, creative tasks, summarization, and natural language understanding. Neo4j handles relationship queries, pathfinding, pattern matching, and analysis of connected data that AI systems need for context. GPT works well for understanding what users want. Neo4j provides the factual foundation for accurate AI responses.
Integration requirements pose different challenges. GPT integrates through API calls with minimal setup but requires prompt engineering and response validation. Neo4j requires data modeling, ETL pipelines, and query optimization but provides direct access to your operational data. The best AI applications combine both: Neo4j for knowledge retrieval and GPT for natural language interaction.
Knowing these differences, now we can start to see where each can excel. Next, let's look at a quick breakdown of when to use each technology based on use case and desired outcomes.
When to Use GPT
GPT fits scenarios where natural language understanding and generation matter more than precise data relationships. For example, customer-facing chatbots benefit from GPT's ability to understand varied questions and generate helpful responses without requiring exact query syntax. There are a few other areas where GPT makes a lot of sense as well, including:
Content creation workflows use GPT for drafting blog posts, product descriptions, marketing copy, and documentation. The model helps writers overcome blank page syndrome and generates multiple variations quickly. While human editing remains essential, GPT accelerates the initial creation phase.
Code generation and developer tools use GPT's training on vast amounts of code. Developers describe what they want to build, and GPT suggests implementations, explains existing code, or helps debug issues. Tools like GitHub Copilot use OpenAI's GPT models to provide context-aware code completion.
Summarization tasks work well with GPT because it understands long text and extracts key points. Applications use GPT to summarize customer feedback, research papers, meeting transcripts, and support tickets. The model identifies themes and generates concise summaries without requiring structured input.
General knowledge questions benefit from GPT's broad training across many domains. When users ask about concepts, historical events, or how things work, GPT provides informative responses. That said, users should still verify critical information (due to potential hallucinations) and avoid relying on GPT for questions requiring current or proprietary data when only relying on training data (and not using RAG techniques to enrich context and knowledge).
GPT works best when paired with structured knowledge sources for AI applications involving your specific business data, customer relationships, or real-time context. A graph database grounds its responses in facts, which can then be combined with GPT's excellent natural language responses. This naturally leads well into when you should use a graph database like Neo4j.
When to Use Neo4j
Neo4j helps to overcome some of the critical limitations in AI applications where GPT and other language models fall short due to a lack of data or context. When building AI systems that need to answer questions about your specific domain, Neo4j provides the factual foundation that can enrich GPT's answers. Here are some of the areas where injecting graph capabilities, through platforms like Neo4j, would make sense:
Reducing AI hallucinations is the primary use case. When GPT generates responses about company-specific information like product catalogs, customer relationships, or organizational hierarchies, it often fabricates details because this data wasn't in its training set. Neo4j stores these entities and relationships explicitly, allowing AI systems to retrieve verified facts before generating responses.
Enabling multi-hop reasoning addresses a fundamental weakness in language models. GPT struggles with questions requiring multiple logical steps across relationships, like "Find products that customers similar to me purchased from suppliers that also sell items I recently viewed." Neo4j executes these traversals precisely, and GPT formats the verified results into natural language.
Providing real-time context solves the staleness problem with language models. GPT's training data has a cutoff date, and even models with internet access can't query your internal systems. Neo4j can maintain current graphs of customer preferences, product relationships, and business rules, depending on what data you are storing within the database. When an AI generates recommendations, it queries the graph for up-to-date context, resulting in up-to-date answers.
Supporting explainable AI becomes possible when Neo4j provides the reasoning path. In fraud detection, an AI might flag a transaction as suspicious, but users need to understand why. The graph reveals the specific relationship patterns that triggered the alert, building trust in AI recommendations since the logic is explainable and auditable (which is much tougher when only relying on training data).
For questions that extend beyond a model's training data, AI systems need structured, accurate, queryable knowledge to complement GPT's language capabilities. Neo4j provides this foundation, turning AI from a pattern-matching system into one grounded in verified relationships and real-time data.
Which is Best? (GPT vs Neo4j)
As already mentioned, neither GPT nor Neo4j is "best" in isolation because they solve different problems. The question changes when you combine them through GraphRAG.
The combination of using GPT with GraphRAG plugged into it addresses key weaknesses in both technologies. GPT gains access to current, domain-specific data and reduces hallucinations. The graph database gains natural language interfaces and semantic understanding. Users ask questions in plain English, and the system generates Cypher queries based on what's required, retrieves accurate data, and generates readable and accurate responses.
For example, a customer service application might use GraphRAG to answer "What products did customers similar to me purchase after buying item X?" The system queries Neo4j (GPT would generate Cypher statements to run against the database) to find similar customers and their purchase patterns, then uses GPT to format the findings into a helpful response with explanations and recommendations.
Although graph capabilities are powerful, the only problem is that implementing GraphRAG traditionally requires significant overhead. This is because you need to extract data from operational databases, transform it into a graph model, load it into Neo4j, and maintain synchronization as source data changes. This ETL pipeline to get data into a usable state adds complexity, latency, and cost. Fortunately, there are ways to make GraphRAG more accessible without all of these steps.
GraphRAG the Easy Way with PuppyGraph
PuppyGraph offers GraphRAG capabilities without the traditional ETL burden. Instead of moving data into a separate graph database (like you need to with Neo4j), PuppyGraph creates a graph layer over your existing data stores. You can query data across multiple databases using graph semantics while it remains in place.

PuppyGraph is the first and only real-time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.

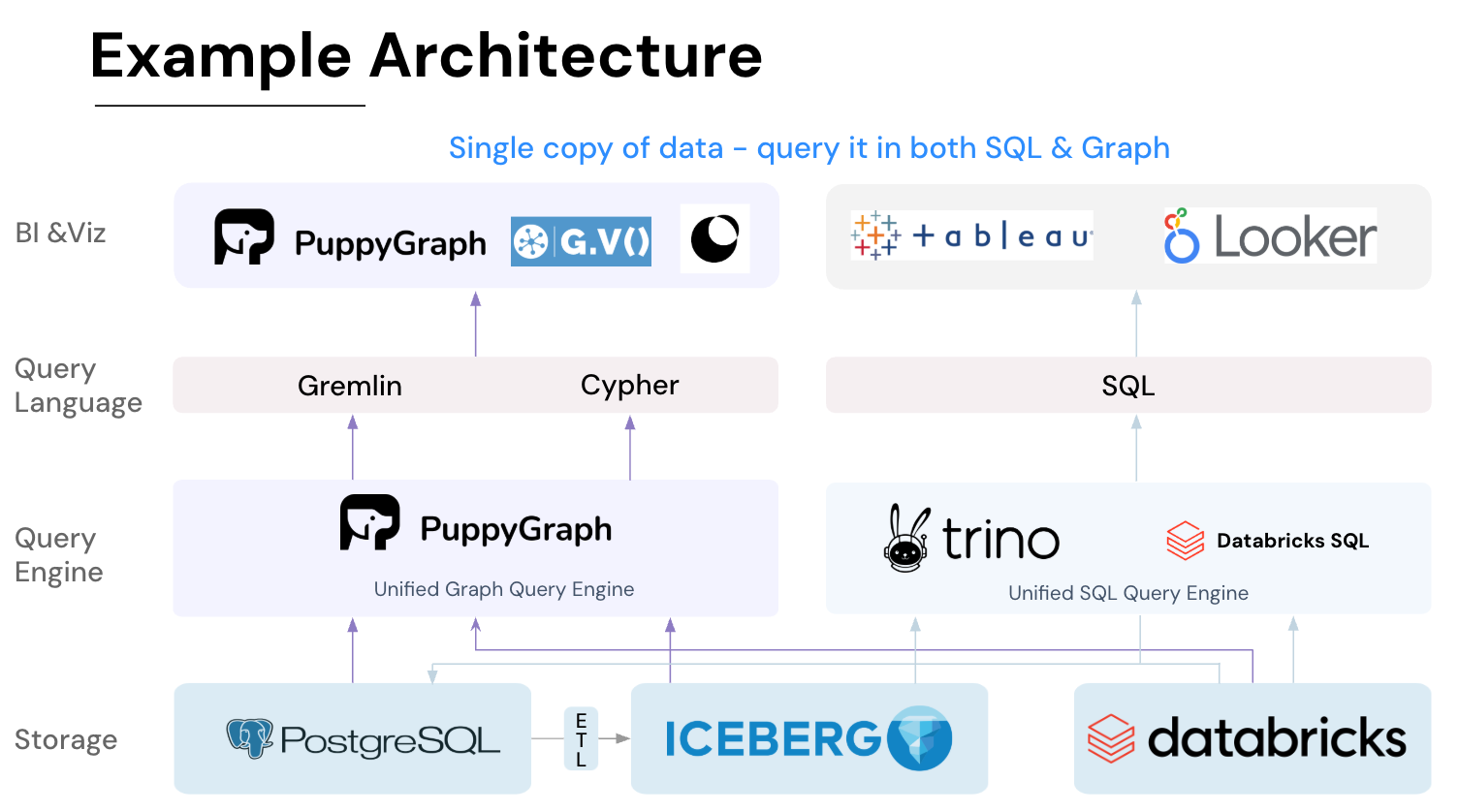
Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata-driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
GPT and Neo4j are two essential but different technologies in modern AI applications. GPT provides natural language understanding and generation but operates on static training data, with limited accuracy in specific domains. Neo4j offers precise relationship queries and analysis, but requires upfront data modeling and ETL investment.
Combining them through GraphRAG grounds AI responses in accurate, structured knowledge graphs. This approach delivers better results than either technology alone, reducing hallucinations while maintaining natural language interfaces.
Traditional GraphRAG implementations face significant overhead from ETL pipelines and duplicate data storage. PuppyGraph eliminates these barriers by creating graph layers over existing databases. Organizations gain graph capabilities and GraphRAG benefits without migrating data or maintaining complex synchronization processes.
For teams evaluating graph databases for AI applications, consider whether you need a standalone graph database or a virtual graph layer. If your data already exists in relational or other databases, PuppyGraph provides a faster, simpler path to GraphRAG capabilities.
Want GraphRAG without the ETL hassle? Try PuppyGraph’s forever-free Developer Edition or book a demo with our graph team to explore your use case.

Matt is a developer at heart with a passion for data, software architecture, and writing technical content. In the past, Matt worked at some of the largest finance and insurance companies in Canada before pivoting to working for fast-growing startups.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install