

What is the Louvain Method?
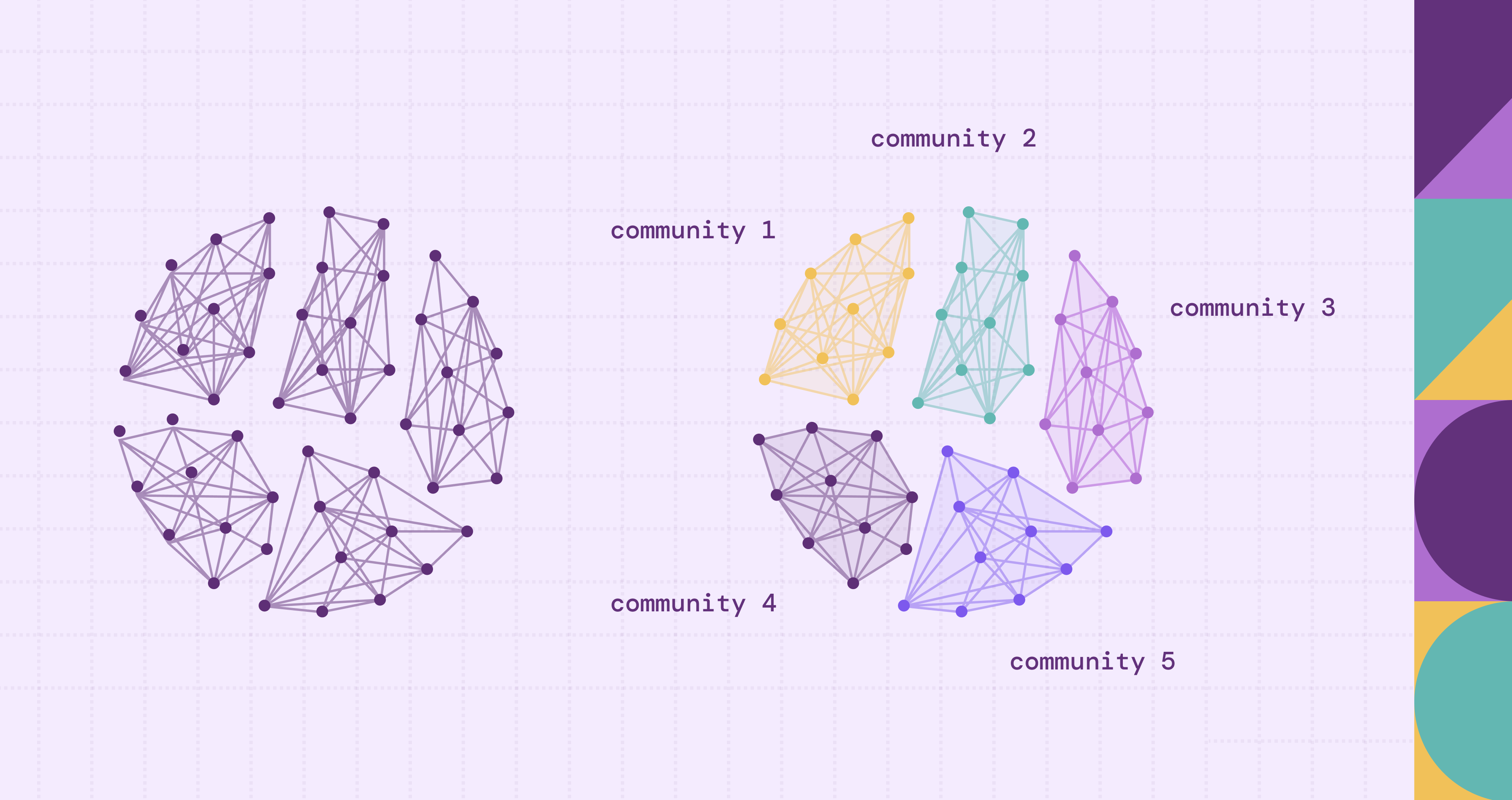
Across industries, platforms and databases generate vast networks of relationships. Social platforms connect people, financial systems link accounts through transactions, and enterprise systems record complex supply chains. In each of these domains, understanding how entities cluster together reveals structure that raw data alone cannot easily expose. Community detection algorithms were developed to uncover these hidden groupings automatically, even in networks with millions or billions of connections.
Among these algorithms, the Louvain method has become one of the most widely used due to its balance of scalability, efficiency, and practical accuracy. It is designed to optimize a metric known as modularity, which measures how strongly nodes are grouped compared to a random baseline. Since its introduction, the Louvain method has been applied in social network analysis, fraud detection, and graph-based machine learning pipelines. This article explores the method in depth, explaining how it works, why it matters, and how it can be implemented in modern graph environments.
What is the Louvain Method?
The Louvain method is a community detection algorithm introduced in 2008 by researchers at the Université catholique de Louvain, including Vincent Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre. The algorithm was presented in their paper “Fast unfolding of communities in large networks,” and it quickly became a foundational technique in network science.
At its core, the Louvain method detects communities by maximizing modularity. Modularity measures how densely connected nodes are within a group compared to how connected they would be if edges were randomly distributed. A high modularity score indicates strong internal connections and sparse connections between communities. The Louvain method works by iteratively improving modularity through local node movements and graph aggregation, forming a hierarchical structure of communities.
One of the primary reasons for its popularity is scalability. Unlike earlier algorithms that struggled with large graphs, Louvain can process millions of nodes efficiently. This makes it suitable for real-world networks such as social graphs, transportation systems, and knowledge graphs.
Core Concept of Louvain Method
The central concept behind the Louvain method is modularity optimization. Modularity, often denoted as \( Q \), compares the density of edges within communities to the expected density if connections were random. The idea is simple: communities should have more internal edges than would be expected by chance.
The modularity \( Q \) is defined as
\[
Q = \frac{1}{2m} \sum_{i,j}
\left(
A_{ij} - \frac{k_i k_j}{2m}
\right)
\delta(c_i, c_j)
\]
where:
- \( A_{ij} \) is the weight of the edge between nodes \( i \) and \( j \) (or 1 if the graph is unweighted),
- \( k_i = \sum_j A_{ij} \) is the (weighted) degree of node \( i \),
- \( m = \frac{1}{2} \sum_{i,j} A_{ij} \) is the total weight of all edges in the graph,
- \( c_i \) denotes the community to which node \( i \) belongs, and
- \( \delta(c_i, c_j) \) equals 1 if nodes \( i \) and \( j \) belong to the same community, and 0 otherwise.
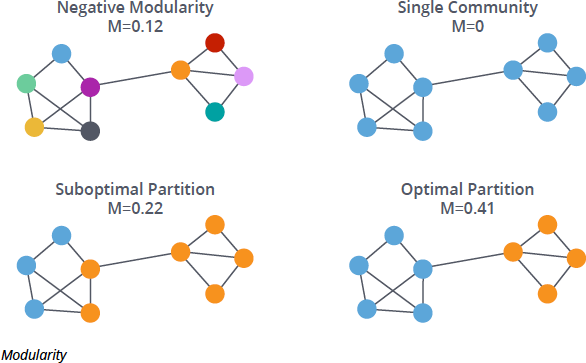
Mathematically, modularity evaluates the difference between actual edges and expected edges under a null model. If nodes within a proposed community are highly interconnected relative to random expectation, modularity increases. If they are weakly connected, modularity decreases. The algorithm attempts to find a partitioning of the graph that maximizes this value.
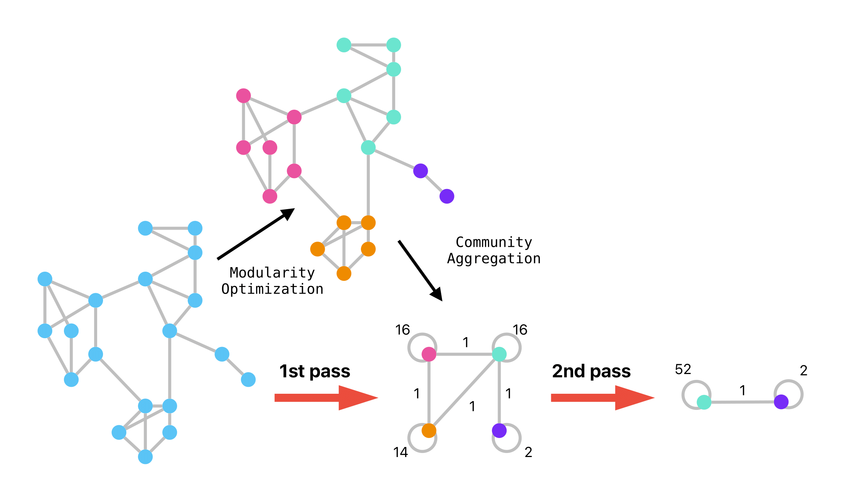
Another key concept is hierarchical clustering. Louvain does not just produce a single flat partition. Instead, it builds communities in layers. After grouping nodes locally, it compresses communities into super-nodes and repeats the process. This hierarchical approach allows the method to uncover multi-level structures in networks, reflecting the fact that communities often exist within larger communities.
How the Louvain Algorithm Works
The Louvain algorithm proceeds in two main phases that are repeated iteratively until no further improvement in modularity is possible.
In the first phase, each node is initially assigned to its own community. The algorithm then considers each node and evaluates the modularity gain that would result from moving it into each of its neighboring communities. The node is moved to the community that provides the highest modularity increase, provided that the increase is positive. This process continues until no local movement can improve modularity.
In the second phase, the algorithm builds a new graph in which each community identified in the first phase becomes a single super-node. Edges between communities are aggregated, and self-loops represent internal connections. The first phase is then applied again to this compressed graph.
This alternating process creates a hierarchy of communities.
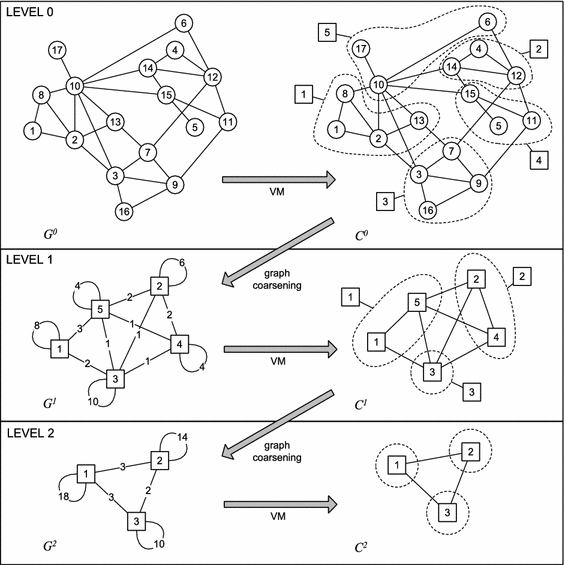
The algorithm stops when modularity can no longer be improved or when a predefined maximum number of iterations is reached. The final partition typically achieves high modularity, although not necessarily the global maximum.
Below is a simplified pseudo-code illustration:
initialize each node as its own community
improvement = true
while improvement:
improvement = false
# Phase 1: local moving
repeat:
moved = false
for each node:
remove node from its community
compute modularity gain for neighboring communities
move node to the community with maximum positive gain
if node moved:
moved = true
until no node moves
# Phase 2: graph aggregation
rebuild graph with communities as super-nodes
if modularity increased:
improvement = trueFeatures of the Louvain Method
The Louvain method is known for computational efficiency. It operates in near-linear time for sparse graphs, making it practical for very large networks. This efficiency is achieved through local updates rather than global optimization, which would be computationally expensive.
The algorithm is also flexible. It can be adapted for weighted graphs, where edges have strengths, and for directed graphs with certain modifications. This flexibility allows it to be applied across diverse domains, from telecommunications to social networks.
Finally, Louvain is relatively simple to implement compared to more mathematically complex methods such as spectral clustering. This simplicity has contributed to its widespread adoption in network analysis libraries and graph processing frameworks.
Applications of Louvain
The Louvain method has been widely adopted in social network analysis. Platforms like Facebook and Twitter rely on community detection techniques to understand user clusters, interest groups, and content propagation patterns. Louvain helps identify tightly knit groups within massive user graphs.
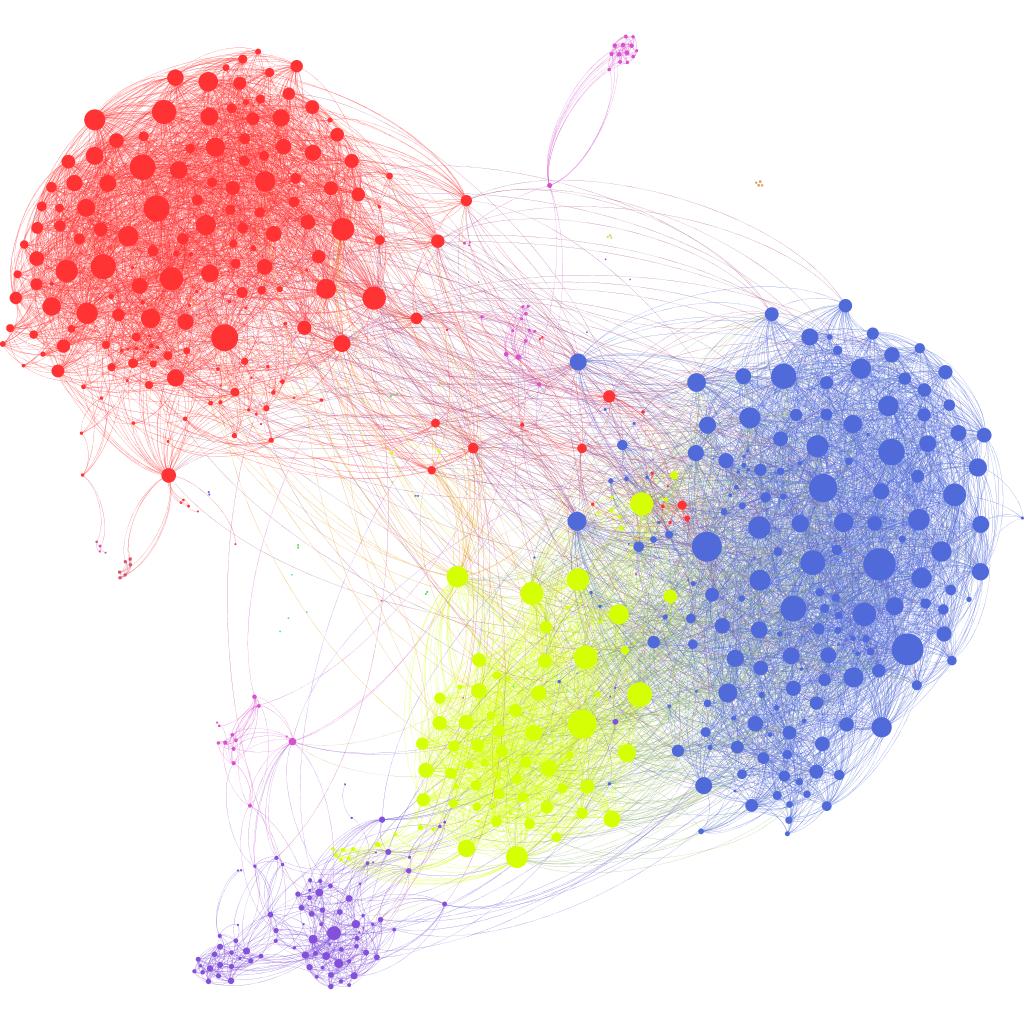
Financial institutions use Louvain in fraud detection. Transaction networks often reveal suspicious clusters of accounts that transfer funds frequently among themselves. Detecting these communities can uncover organized fraud rings or money laundering networks.
In cybersecurity, Louvain is used to analyze communication and access networks within enterprise environments. Devices, users, and applications form complex interaction graphs. Community detection can reveal abnormal clusters of activity, potentially identifying compromised accounts or lateral movement within a network.
Knowledge graph construction and GraphRAG pipelines also leverage Louvain for structural understanding. When entities such as documents, concepts, and citations form dense relational graphs, community detection can group related knowledge clusters. These clusters improve retrieval quality, contextual summarization, and reasoning by narrowing search space to semantically coherent regions of the graph.
Louvain vs Other Community Detection Methods
Several alternative community detection algorithms exist, each with its own strengths. The Girvan–Newman method, for example, removes edges with high betweenness centrality to reveal community boundaries. While conceptually elegant, it is computationally expensive and unsuitable for large graphs.
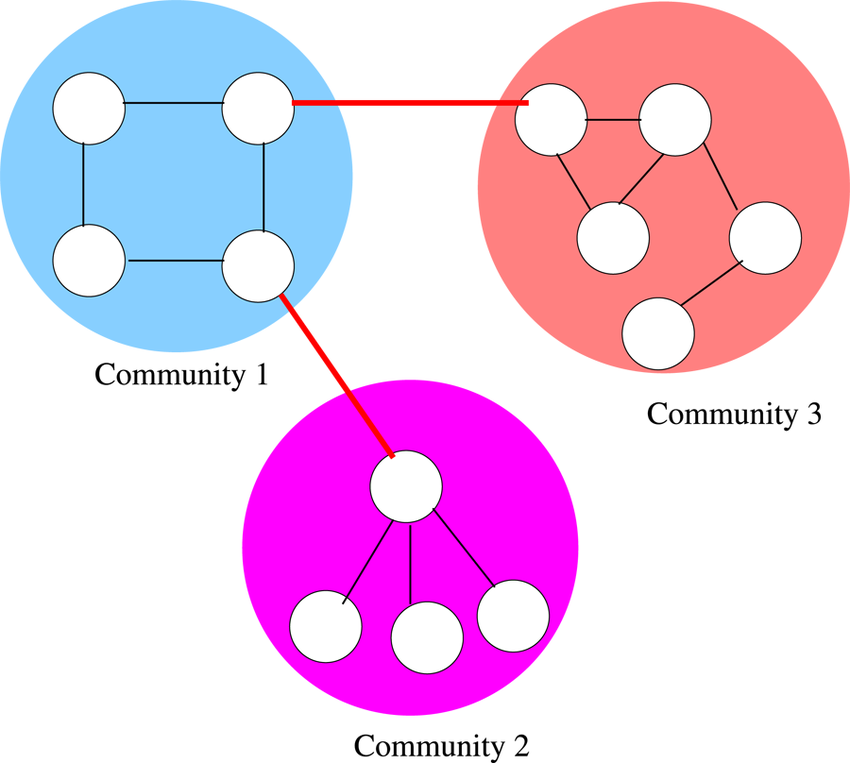
Spectral clustering uses eigenvectors of graph Laplacians to partition networks. It can provide mathematically rigorous partitions but requires matrix computations that scale poorly for massive datasets. In contrast, Louvain’s greedy optimization approach scales far more efficiently.
Label propagation is another fast method. It assigns labels to nodes based on majority voting among neighbors. While extremely fast, it can produce unstable results across runs. Louvain tends to produce more stable partitions due to its modularity-based objective.
Compared to these methods, Louvain strikes a balance between scalability and structural quality. However, it shares a limitation common to modularity-based approaches: sensitivity to resolution limits.
Limitations of Louvain
Despite its strengths, the Louvain method has notable limitations. One key issue is the resolution limit of modularity. The algorithm may fail to detect small communities within large networks because modularity optimization can favor merging smaller clusters into larger ones.
Another limitation is non-determinism. The order in which nodes are processed can influence the final partition. Different runs on the same graph may yield slightly different community structures, particularly in ambiguous regions of the network.
Louvain also optimizes modularity greedily, which means it can become trapped in local maxima. It does not guarantee finding the global modularity maximum. Although results are often satisfactory in practice, they are not theoretically optimal.
Advancements & Alternatives
Several improvements and alternatives have emerged to address Louvain’s limitations. One prominent advancement is the Leiden algorithm, which improves both connectivity and stability. Unlike the Louvain method, which may produce communities that are internally poorly connected or even fragmented due to purely greedy node movements, Leiden introduces a refinement phase that explicitly repairs and improves community structure before graph aggregation.
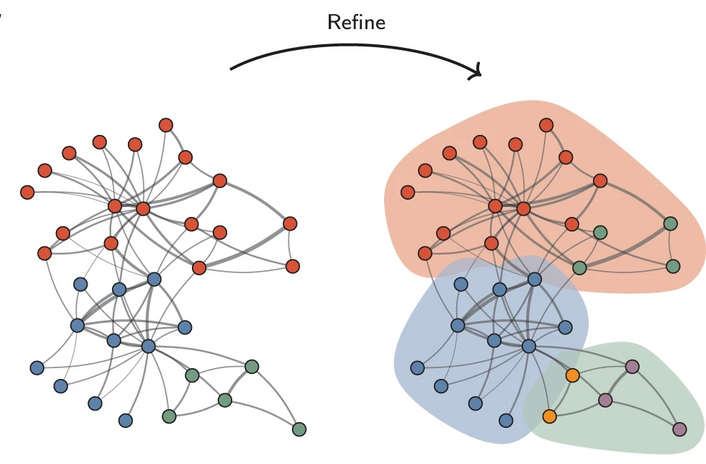
In this phase, each community obtained from the local moving step is first split into singleton nodes and then rebuilt using a constrained local moving procedure restricted to that community. Nodes are allowed to merge only with sufficiently well-connected subgroups (i.e., groups with relatively strong connectivity to the node compared with the node’s total edge strength) that yield a positive improvement in the quality function, and candidate moves are selected in a randomized rather than strictly greedy manner. This refinement step ensures that communities are internally well connected at a finer granularity, while also reducing sensitivity to node ordering and generally producing higher-quality and more stable partitions.
Leiden can also address the resolution limit through multi-resolution modularity. The resolution limit refers to the tendency of modularity optimization to merge small but well-defined communities when the graph becomes large. This can be controlled by introducing a resolution parameter \( \gamma \) into the quality function:
\[
Q(\gamma) =
\frac{1}{2m}
\sum_{i,j}
\left(
A_{ij} -
\gamma \frac{k_i k_j}{2m}
\right)
\delta(c_i,c_j)
\]
When \( \gamma > 1 \), smaller communities are favored; when \( \gamma < 1 \), larger communities are preferred. In practice, if a network contains several densely connected subgroups that are weakly connected to each other, increasing \( \gamma \) will penalize inter-community edges more strongly and help separate these dense groups. This helps mitigate the resolution limit problem, where small communities may otherwise be absorbed into larger ones during optimization.

Graph neural networks have also introduced new approaches to community detection. Instead of optimizing modularity directly, Graph Neural Network models learn node embeddings that capture structural information of nodes in a low-dimensional feature space. After obtaining these embeddings, community structures can be identified by applying clustering algorithms (e.g., k-means clustering) in the embedding space, where nodes belonging to the same community tend to be located close to each other due to their similar structural contexts.
Although these advancements provide benefits, Louvain remains a baseline method due to its simplicity and speed. In many real-world use cases, it provides sufficiently accurate results with minimal computational overhead.
Implementing Louvain in Practice
Implementing Louvain is straightforward using graph libraries. In Python, the NetworkX ecosystem offers community detection extensions that include Louvain. Similarly, graph databases such as Neo4j provide built-in implementations within their graph data science libraries.
Take Python as an example:
import networkx as nx
# Number of nodes in each community
sizes = [30, 30, 30]
# Probability matrix
# Diagonal = high intra-community connection probability
# Off-diagonal = low inter-community connection probability
probs = [
[0.7, 0.05, 0.02],
[0.05, 0.7, 0.02],
[0.02, 0.02, 0.7]
]
# Generate benchmark community graph using stochastic block model
G = nx.stochastic_block_model(sizes, probs, seed=123)
# Detect communities using Louvain method (modularity optimization)
communities = nx.community.louvain_communities(G, seed=123)
# Output community sizes
print([len(c) for c in communities])Setting a random seed here is recommended for reproducibility since Louvain is not deterministic. Different node ordering or initialization states may lead to slightly different community partitions across runs.
In practical deployments, Louvain is usually executed multiple times, and the partition with the highest modularity score is selected. Tracking modularity values across iterations helps verify convergence and ensures that the algorithm is not stuck in a suboptimal local optimum.
Another important practical consideration is the resolution parameter, which controls the granularity of detected communities. Higher resolution values tend to produce smaller and more fine-grained communities, while lower values merge nodes into larger clusters. Tuning this parameter is often necessary when analyzing graphs with hierarchical or multi-scale structures.
For large-scale graphs, performance optimization is also critical. Sparse graph representations, parallel preprocessing, and limiting unnecessary recomputation can significantly reduce runtime overhead. Early stopping criteria can be introduced when modularity improvement between iterations falls below a small threshold.
Louvain with PuppyGraph
Relationship data is often distributed across multiple systems: relational stores, data lakes, and real-time pipelines. To analyze it as a graph, teams commonly build ETL workflows that replicate data into a separate graph store, increasing storage costs and latency. This additional complexity becomes especially noticeable when running iterative community detection algorithms such as Louvain.
PuppyGraph addresses this challenge by enabling graph queries directly on existing data sources without copying data into a separate graph database. By exposing relational or lakehouse data as a property graph layer, it allows teams to apply algorithms such as Louvain without maintaining a parallel graph store.
PuppyGraph uses a graph schema to define how tabular data should be interpreted as a graph. The schema specifies which tables represent vertices and edges, how columns map to identifiers and attributes, and how relationships are constructed. After uploading the schema, you can query the graph using openCypher or Gremlin, or invoke built-in algorithms with openCypher or Gremlin syntax.
PuppyGraph provides a built-in implementation of the Louvain Community Detection algorithm for identifying modular structures in large networks. It works by iteratively grouping nodes into communities and then compressing communities into super-nodes to further refine the structure. The algorithm assigns each node a communityId representing its community membership.
To run Louvain, you can use either Gremlin or openCypher syntax. A simple example in Cypher looks like this:
CALL algo.louvain({
labels: ['User'],
relationshipTypes: ['LINK'],
maxIterations: 30,
relationshipWeightProperty: 'weight',
maxLevels: 1,
threshold: 0.0001,
largeCommunityThreshold: 10000,
seed: 42
}) YIELD id, communityId
RETURN id, communityIdThe algorithm scales to large datasets and can optionally export results directly to object storage for downstream analytics and machine learning workflows.

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.


Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
The Louvain method is an efficient and practical algorithm for detecting community structures in large networks. By iteratively optimizing modularity through local node movements and hierarchical graph aggregation, it balances scalability and accuracy for real-world graph analytics. Although it has limitations such as resolution sensitivity and non-deterministic results, it remains a widely used baseline for large-scale community detection tasks across many industries.
PuppyGraph simplifies graph analytics by allowing users to run graph queries directly on existing data sources without building separate graph databases or ETL pipelines. This enables users to apply algorithms like Louvain-based community detection directly on their operational data. This zero-ETL approach reduces cost and complexity while enabling real-time relationship analysis across distributed data systems. By supporting standard graph query languages and scalable infrastructure, PuppyGraph helps organizations extract insights from complex relationship networks efficiently.
Explore the forever-free PuppyGraph Developer Edition, or book a demo to see it in action.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


{kind=link}
{kind=link}
Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install