

RedisGraph vs Neo4j: Key Differences
RedisGraph and Neo4j both implement the property graph model and use Cypher as their query language, but they were designed for very different purposes. Neo4j is a purpose-built, disk-persistent graph database optimized for deep multi-hop traversals across large connected datasets. RedisGraph was a graph database module for Redis that stored graphs entirely in RAM using sparse adjacency matrices and linear algebra operations via GraphBLAS, trading graph scale for sub-millisecond query performance.
Before going further: RedisGraph reached official end-of-life on January 31, 2025. Redis disabled RedisGraph commands on Redis Enterprise Cloud, tagged the GitHub repository as deprecated in February 2025, and removed graph capabilities from Redis Stack entirely. No new patches or features will be released.
This comparison is still worth reading for two reasons. First, teams running legacy RedisGraph deployments need to understand their current state before deciding where to migrate. Second, the core trade-off between these two databases, namely the contrast of raw query speed on smaller datasets versus deep traversal at scale, is one that comes up constantly when choosing a graph database.
For teams currently running RedisGraph and deciding where to go next, this comparison (along with a brief intro to PuppyGraph as a potential alternative) walks through your options without requiring a full infrastructure rebuild.
What is RedisGraph?

RedisGraph was a graph database built on Redis, first released in 2018 by Roi Lipman at Redis Labs. It extended the popular in-memory key-value store with property graph capabilities, using a storage approach unlike anything else in the graph database space: sparse adjacency matrices powered by GraphBLAS, a high-performance linear algebra library.
Rather than storing relationships as pointer chains or adjacency lists, RedisGraph represented the entire graph as a set of sparse matrices. Graph queries were translated into linear algebra operations (primarily matrix multiplications) executed against these matrices using the SuiteSparse implementation of GraphBLAS. For 1-2 hop traversals on small datasets and moderately sized graphs, this approach was extremely fast, showing 6-600x faster than comparable databases in Redis's own benchmarks.
The entire graph structure lived in RAM, enabling fast access to graph data with minimal latency. Persistence was handled by Redis's existing RDB snapshots and AOF (Append-Only File) mechanisms, not native graph-aware checkpointing.
Key features
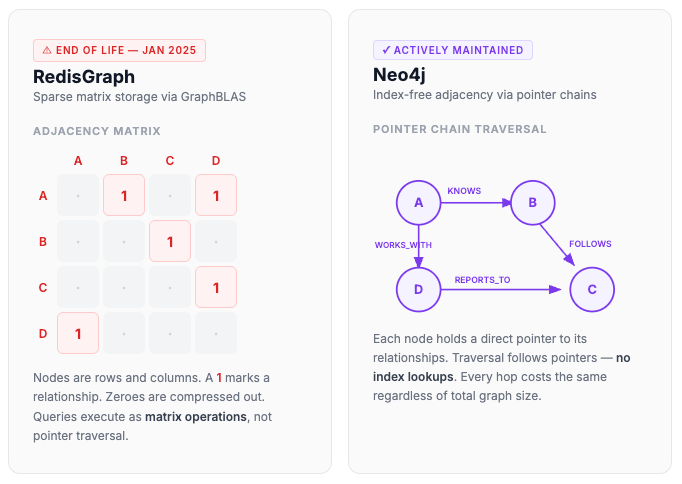
Sparse matrix storage via GraphBLAS
RedisGraph stores adjacency matrices in Compressed Sparse Row (CSR) and Compressed Sparse Column (CSC) formats, suppressing zero values and storing only non-zero elements. This kept memory usage reasonable despite keeping everything in RAM, and let graph traversals run as matrix operations rather than pointer chasing.
Cypher query language (subset)
RedisGraph implemented a subset of the Cypher query language, the same query language used by Neo4j. This made it accessible to developers already familiar with Neo4j's query model. Coverage was incomplete, though, since not all Cypher clauses, functions, and path expressions were supported, and complex queries involving multi-hop patterns could hit those limits.
In-memory processing for real-time performance
With the entire graph in RAM and queries running as linear algebra operations, RedisGraph delivered sub-millisecond response times for shallow graph traversal. Redis's own benchmarks showed it outperforming Neo4j by 36-15,000x on single-request 1-hop queries. This made it a strong fit for real-time analytics and fast query execution on bounded datasets.
Redis ecosystem integration
As a graph database module, RedisGraph inherited Redis persistence (RDB/AOF), Redis Sentinel for high availability, and Redis Cluster for horizontal scaling. Teams already running Redis could add graph capabilities without standing up a separate system. Full-text search was available through RediSearch integration.
Multi-tenancy via graph-per-tenant
RedisGraph supported multiple named graphs within a single Redis instance, making it a good fit for multi-tenant applications where each tenant's graph data needed to be isolated without separate infrastructure.
Read/write isolation
RedisGraph used a read/write lock for graph modifications. Multiple reads could run at the same time, but writes needed exclusive access, meaning that write-heavy workloads could run into contention.
What is Neo4j?

Neo4j is a native graph database built specifically for storing and traversing connected data. Initially released in 2007, it stores relationships as physical pointers between multiple nodes using index-free adjacency, meaning traversal cost scales with the number of relationships you explore, not the total size of the graph.
For a full breakdown of Neo4j's architecture, query language, clustering model, and ecosystem, see our Neo4j vs MongoDB comparison. The summary below focuses on what matters most for the RedisGraph comparison.
Key features
Index-free adjacency
Each node record in Neo4j contains a direct pointer to its first relationship. Each relationship record contains pointers to its start node, end node, and neighboring relationships in a doubly-linked list. Graph traversal follows these pointers directly; no index lookups happen during exploration. This keeps multi-hop traversal time at O(N) relative to the explored subgraph, regardless of total graph size, which is what makes it effective for complex graph analytics on large datasets.
Full Cypher implementation
Neo4j created the Cypher query language and implements the full OpenCypher specification, including variable-length path expressions, complex graph patterns, APOC procedures, and the Graph Data Science library for running advanced graph algorithms like PageRank, Louvain community detection, and shortest path calculations.
Native graph storage on disk
Neo4j stores data on disk in specialized files (separate files for nodes, relationships, properties, and labels), providing true native graph storage. Each record type has a fixed size, so Neo4j can calculate disk locations directly from record IDs. The graph doesn't need to fit in RAM, which makes it viable for large datasets that would blow past memory limits.
ACID transactions with locking
Neo4j provides ACID transactions; its default isolation level is read committed. Write operations lock affected nodes and relationships until commit. Concurrent reads see a consistent snapshot from transaction start. This supports both transactional and analytical workloads on the same dataset, something traditional relational databases struggle with when data has complex graph patterns.
Enterprise clustering
Neo4j Enterprise Edition uses a Core + Read Replica architecture with Raft consensus for leader election. All writes go through the single leader Core node. Read Replicas serve read-only queries and scale with horizontal scaling. The Community edition runs as a single node without clustering.
Graph Data Science library
Neo4j includes a dedicated library for deep graph analytics and complex relationship analysis: community detection, centrality analysis, pathfinding, node similarity, and link prediction. These run directly on graph data without shipping results out to separate data pipelines or data lakes.
RedisGraph vs Neo4j: core differences
When to use RedisGraph
Since RedisGraph is end-of-life, this section is mainly for teams reviewing their existing deployment before deciding on a migration path. For those still actively using RedisGraph (without support), here are a few key use cases it is/was able to cover well:
Sub-millisecond graph queries on bounded datasets
RedisGraph's in-memory data store and GraphBLAS execution made it the fastest option for shallow traversals on graphs that fit in RAM. If your graph is under a few hundred GB, has well-defined relationships, and your queries rarely go beyond 2 hops, RedisGraph delivers real-time query performance that disk-based databases simply couldn't touch.
Redis-native teams running real-time queries
Teams already running Redis for caching, session storage, or pub/sub could add graph capabilities without standing up a new system. The shared infrastructure, familiar tooling, and Redis Cluster integration made it easy to adopt for things like real-time fraud detection of suspicious patterns, lightweight recommendations, or session-based relationship tracking.
Multi-tenant graph applications
RedisGraph's graph-per-tenant model gave clean isolation without separate infrastructure per tenant. For SaaS platforms running hundreds or thousands of small, isolated graphs, this kept operations simple.
High-throughput concurrent reads
The read/write lock lets multiple read queries run at the same time while only blocking on writes. For read-heavy workloads with infrequent mutations, throughput was strong.
Note for existing RedisGraph users
If you're currently running RedisGraph, you have two main options. FalkorDB is the actively maintained community fork that is backward compatible with your Cypher queries and faster in most benchmarks. Alternatively, PuppyGraph (covered below) can run graph queries directly against your existing databases without needing a graph database at all.
When to use Neo4j
Neo4j, a more traditional graph database, can handle more complex use cases and data volumes and remains actively maintained. Neo4j tends to excel over RedisGraph in the following scenarios:
Deep multi-hop traversals at scale
Neo4j's index-free adjacency keeps traversal time proportional to the explored subgraph: a query touching 1,000 relationships takes roughly the same time in a million-node graph as in a billion-node graph. For fraud detection, supply chain tracing, or identity resolution that regularly goes 3-10+ hops across multiple nodes, that's the key advantage.
Graphs that exceed available RAM
RedisGraph needed the full graph in memory. Neo4j stores data on disk and pulls what it needs through a page cache, so graph size isn't constrained by memory. Organizations running knowledge graphs, enterprise identity graphs, or social network datasets at scale need that.
Complex graph analytics and advanced graph algorithms
The Graph Data Science library covers PageRank, Louvain community detection, Dijkstra's shortest path, node similarity, and dozens of other algorithms, all running directly in the database. These are table stakes for real-time fraud detection and recommendation engines, and RedisGraph didn't offer them without external processing.
Full Cypher coverage
Neo4j implements the complete OpenCypher specification plus APOC procedures. Complex graph patterns, subqueries, and path predicates that hit walls in RedisGraph's subset work fine in Neo4j. Teams migrating from RedisGraph often find queries that run at a small scale need rewrites because of gaps in Cypher coverage.
Long-term production reliability
Neo4j has been running in production at enterprise scale since 2007. It has ACID transactions, mature clustering, solid security controls, and a commercial support tier. For production applications, that track record matters.
Which is best? RedisGraph vs Neo4j
RedisGraph and Neo4j were built for opposite ends of the same problem. RedisGraph gave up graph scale and full Cypher support to get exceptional query speed on datasets that fit in memory. Neo4j gave up that raw speed to handle much larger graphs, deeper traversals, and the full algorithm library.
That comparison is less relevant now since RedisGraph is end-of-life. For anything new, Neo4j is the default choice for graph-native workloads when deciding between these two platforms. For existing RedisGraph deployments, the real question is where your data goes next, and that depends on what your queries actually look like.
Choose Neo4j if:
- Your graphs exceed available RAM or will keep growing
- You regularly run 3+ hop traversals or need to match complex graph patterns
- You need graph algorithms like centrality, community detection, or pathfinding
- You need full Cypher coverage, including path predicates and complex subqueries
- You need enterprise clustering, advanced security, or commercial support
Migrate away from RedisGraph if:
- You're on Redis Enterprise Cloud since RedisGraph commands were disabled after January 31, 2025
- You're on self-managed Redis Enterprise since no new support is provided, though you can keep running it
- You need Cypher features beyond what RedisGraph's subset covered
Why consider PuppyGraph as an Alternative
If RedisGraph’s end-of-life has you looking for a new path, or you’re considering Neo4j while your data is still spread across your stack, PuppyGraph takes a different approach: it runs graph queries directly on your existing data sources.

PuppyGraph is the first and only real-time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata-driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
RedisGraph had a genuinely unusual architecture with sparse adjacency matrices and GraphBLAS, giving it query speeds that no other graph database matched for shallow traversals on in-memory datasets. But it reached end-of-life in January 2025, and Redis has no plans to revive it.
Neo4j is the mature, actively maintained choice for graph-native workloads. Its index-free adjacency, full Cypher implementation, and Graph Data Science library handle deep graph traversal at scale across fraud detection, knowledge graphs, recommendation engines, and identity resolution.
If you're already running RedisGraph, where you go next depends on your data volume, how deep your queries go, and what your existing infrastructure looks like. If your data lives in relational or analytical systems, PuppyGraph runs graph queries directly against your existing stack: no dedicated graph database required.
To see how PuppyGraph works with your current setup, download PuppyGraph's forever-free Developer edition or book a demo.

Matt is a developer at heart with a passion for data, software architecture, and writing technical content. In the past, Matt worked at some of the largest finance and insurance companies in Canada before pivoting to working for fast-growing startups.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install