

Knowledge Graph vs LLM: Know the Differences
Large Language Models (LLMs) handle everyday questions for millions of users worldwide. Alongside them, knowledge graphs have long served as structured knowledge bases. Both systems provide answers to human queries.
Although they share this function, their methods differ sharply. LLMs converse naturally in everyday language for effortless interaction, though accuracy can vary. Knowledge graphs deliver rigorously verified answers but require technical query skills that limit broader accessibility.
LLMs generate responses using statistical patterns from training data, which may sometimes be inaccurate. Knowledge graphs retrieve answers through verified connections between facts, offering reliability but requiring technical expertise to use.
This article will introduce both technologies, explaining how they work and where they overlap or diverge. We will compare their capabilities and limitations, then explore practical ways to combine their strengths.
What is a Knowledge Graph?
A knowledge graph is a highly structured knowledge base that uses a graph-structured data model to represent and operate on data, capturing the semantic meaning of information. Unlike traditional databases that merely store data in rigid rows and columns, knowledge graphs store interlinked descriptions of entities (objects, events, concepts) and the explicit relationships between them. This semantic structure allows machines to reason with information like humans do.
Diverse Architectural Implementations
Knowledge graphs are implemented using different graph database architectures, which are optimized for specific data organization and query needs. It is crucial to understand that there is no singular foundational structure for all knowledge graphs, but rather two dominant models:
- Resource Description Framework (RDF) Triple Stores: These systems are rooted in the Semantic Web standards and organize information into basic units called triples, consisting of a Subject, a Predicate, and an Object. For example, triple ex:MarieCurie ex:discovered ex:radium represents the fact “Marie Curie discovered radium”.
- Property Graphs: A Property Graph is a directed graph model, designed to represent entities and their relationships with key-value pairs called properties. If we have a node with key-value pair name: Marie Curie, another node with chemical elements: radium, then the two nodes together with a directed edge of type discovered from the Marie Curie node to the radium node, state the fact “Marie Curie discovered radium”.

Trusted Data Source
Knowledge graphs serve as trusted data sources by connecting information through human-verified relationships. This explicit structure ensures high factual accuracy and full auditability, making knowledge understandable for both people and AI systems.
Their interconnected design also supports reasoning capabilities and graph algorithms, allowing systems to move beyond keyword searches, finding information through semantic meaning and complex connections. Enterprises gain a reliable foundation for intelligent applications requiring verified knowledge.
Accessibility Challenges
While knowledge graphs provide rigorously verified knowledge, directly interacting with and querying these graphs requires technical expertise in specialized query languages (such as Cypher, Gremlin or SPARQL), creating a significant barrier for non-technical users.
Consequently, knowledge graphs are rarely exposed directly to end-users. Instead, they are seamlessly integrated into intuitive applications like search engines or virtual assistants, where they enhance capabilities such as semantic search and fact-grounded responses.
What is an LLM (Large Language Model)?
A Large Language Model (LLM) is typically a neural network based on the transformer architecture, and is pretrained via self-supervised learning on extensive text corpora. It generates text through next-token prediction. Many prominent LLMs operate as general-purpose sequence models, capable of generating, summarizing, translating, and reasoning over text.
The Transformer Architecture
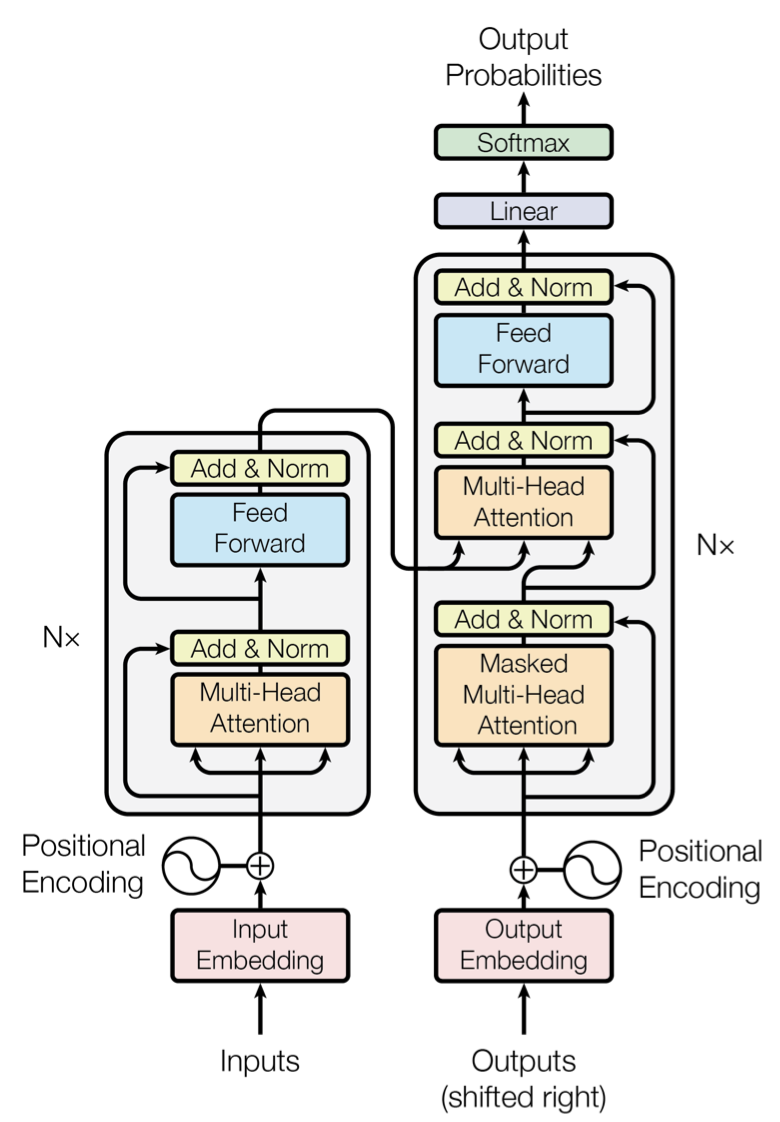
While ChatGPT’s 2022 launch ignited today’s LLM revolution, its roots stretch back to the introduction of the Transformer architecture in 2017. This pivotal innovation replaced the less efficient recurrence of earlier neural networks with a multi-head self-attention mechanism, allowing for highly efficient parallel computation and scaling to unprecedented data volumes. The scale of these models, featuring billions to trillions of parameters, allows them to acquire powerful latent knowledge and exhibit emergent reasoning behaviors, such as few-shot learning and compositional reasoning, with minimal task-specific supervision.
Next-Token Prediction
A fundamental distinction of the LLM is its operational mechanism: it does not work by searching or retrieving information from a verified source. Instead, LLMs function by predicting the most probable sequence of words that should follow the input prompt, based on patterns learned during training. When an LLM answers a question, it is completing a text sequence consistent with its trained context, prioritizing linguistic flow and probability.
Factual Reliability Challenges
The reliance of LLMs on next-token prediction, rather than verifiable fact checking, introduces core challenges that compromise factual reliability.
The first major issue of LLMs is their tendency to hallucinate, generating plausible-sounding but entirely fabricated information with high confidence. Because these models construct responses based on learned linguistic patterns rather than verified knowledge sources, they may invent authoritative-sounding details like fake research citations, non-existent events, or incorrect technical specifications when filling gaps in their training data. This behavior emerges directly from their architecture: without built-in fact-checking mechanisms, coherence and fluency often override truthfulness.
LLMs also face static knowledge constraints, as their training data has a fixed cutoff date. They cannot reliably answer questions about events or data that occurred afterward without specialized tooling, making it unreliable for tasks requiring real-time currency, such as market analysis.
Collectively, these inherent limitations make pure LLM outputs fundamentally not reliable for high-stakes enterprise applications, such as legal or medical contexts.
LLMs as Tool Users
While a pure LLM has considerable limitations due to its static, probabilistic nature, its true potential is realized when it acts as an AI agent capable of using external tools. This tool-calling capability is essential for overcoming the knowledge cutoff and factual unreliability challenges.
For instance, if a user asks, “What is the weather today?” or “Tell me today's news”, the LLM recognizes that this query requires current, verified external data. Instead of relying on its outdated pre-trained weights, the LLM converts the natural language request into a precise action, such as calling a weather API or a search engine tool, to retrieve the necessary up-to-date information.
This approach transforms the LLM from a static text generator into a dynamic orchestrator that utilizes verifiable data sources to provide accurate, real-time answers, effectively compensating for its internal knowledge gaps.
How is a Knowledge Graph Different from an LLM?
While both technologies manage knowledge, they operate on entirely different principles. The core differences can be broken down into their architecture, storage, explainability, reliability, and usability.
Architecture: Structured Framework vs. Neural Network
The most fundamental difference is their design. A knowledge graph is a structured knowledge source, representing data through a clearly defined framework, usually property graphs or RDF. In contrast, an LLM is a complex neural network, specifically a transformer.
Knowledge Storage: Explicit Entities vs. Opaque Model Weights
In a knowledge graph, facts are stored as triples (in RDF) or as nodes and edges (in property graphs). This makes the knowledge explicit: if a fact is incorrect, it is easy to locate the specific node or relationship and correct it.
While in an LLM, knowledge is stored as model weights (billions of parameters). This is a “black box” environment: you cannot simply find a single weight to change a specific fact, making errors much harder to fix.
Explainability: Traceable Reasoning vs. Black Box
Knowledge graphs offer high explainability, you can easily trace the reasoning path through graph traversal to see exactly how a conclusion was reached. Large language models, however, function as black boxes. Their outputs emerge from complex numerical computations across billions of parameters, making it difficult to identify the specific sources or logic behind any given response.
Reliability: Factual Grounding vs. Token Prediction
Since knowledge graphs are based on verified, interlinked facts, they are considered highly reliable and trustworthy. LLMs generate plausible text through token prediction, which is effective for general tasks but unreliable for mission-critical facts due to potential hallucination. They are designed to be fluent and probable, not necessarily factually accurate.
Usability: Expert Queries vs. Natural Language
The trade-off for the knowledge graph's reliability is its complexity: it typically requires an expert to write specialized queries (such as Cypher, Gremlin or SPARQL) to retrieve information. LLMs are significantly more easy to use, as they allow anyone to interact with and retrieve information using simple, everyday natural language.
Knowledge Graph vs LLM: Side-by-Side Comparison
This table summarizes the core technical and operational differences detailed in the previous section.
A Brief History: Knowledge Graph and LLM
Knowledge graphs evolved from foundational research in knowledge representation and reasoning in the 1960s and 1970s. Throughout the 1990s and early 2000s, the Semantic Web project further matured the field by establishing standards like RDF and OWL to facilitate a machine-readable web. Projects like DBpedia (2007) demonstrated scalable implementations. And by the early 2010s, these systems achieved mainstream adoption, transforming search engines like Google or Microsoft Bing with entity-aware context understanding.
Large language models emerged from neural network research. Recurrent architectures (RNNs/LSTMs) handled sequential data from the 1990s onward. Word embeddings (2013) efficiently captured semantic relationships, while attention mechanisms (mid-2010s) improved context handling in translation. The Transformer architecture (2017) enabled massive scaling, culminating in systems like ChatGPT (2022) that transformed human-AI interaction.
Which is Best: Knowledge Graph or LLM?
Divergence of knowledge graphs and LLMs represents the broader tension in artificial intelligence between symbolic AI and connectionist AI. Symbolic AI, exemplified by knowledge graphs, excels at processing and manipulating concepts through explicit logical rules, while connectionist AI shines at identifying complex patterns and generating human-like text based on vast amounts of data. Each paradigm offers unique advantages and trade-offs.
Therefore, the question is not which technology is superior, but how their distinct, non-overlapping strengths can be optimally combined. LLMs excel at its usability, interpreting human ambiguity and generating fluent responses, while knowledge graphs at verifying facts, executing complex logic and managing knowledge structure.
Knowledge Graph Retrieval-Augmented Generation (GraphRAG)
As LLMs reach their full potential when acting as AI agents that use external tools, integrating them with knowledge graphs becomes a natural progression. This approach, called Graph Retrieval-Augmented Generation (GraphRAG), equips LLMs with verified factual knowledge. It significantly improves answer accuracy and mitigates hallucinations compared to standard methods.
GraphRAG uses structured queries over semantic relationships instead of unstructured text searches. This provides clear evidence for responses. Users can see both the natural language query and the precise graph results, making the reasoning process transparent and verifiable.
PuppyGraph supports GraphRAG, enabling seamless integration of structured knowledge retrieval with LLMs. Its interactive visualizations transform complex relationships into intuitive node-and-edge diagrams, revealing structural patterns directly within your data.
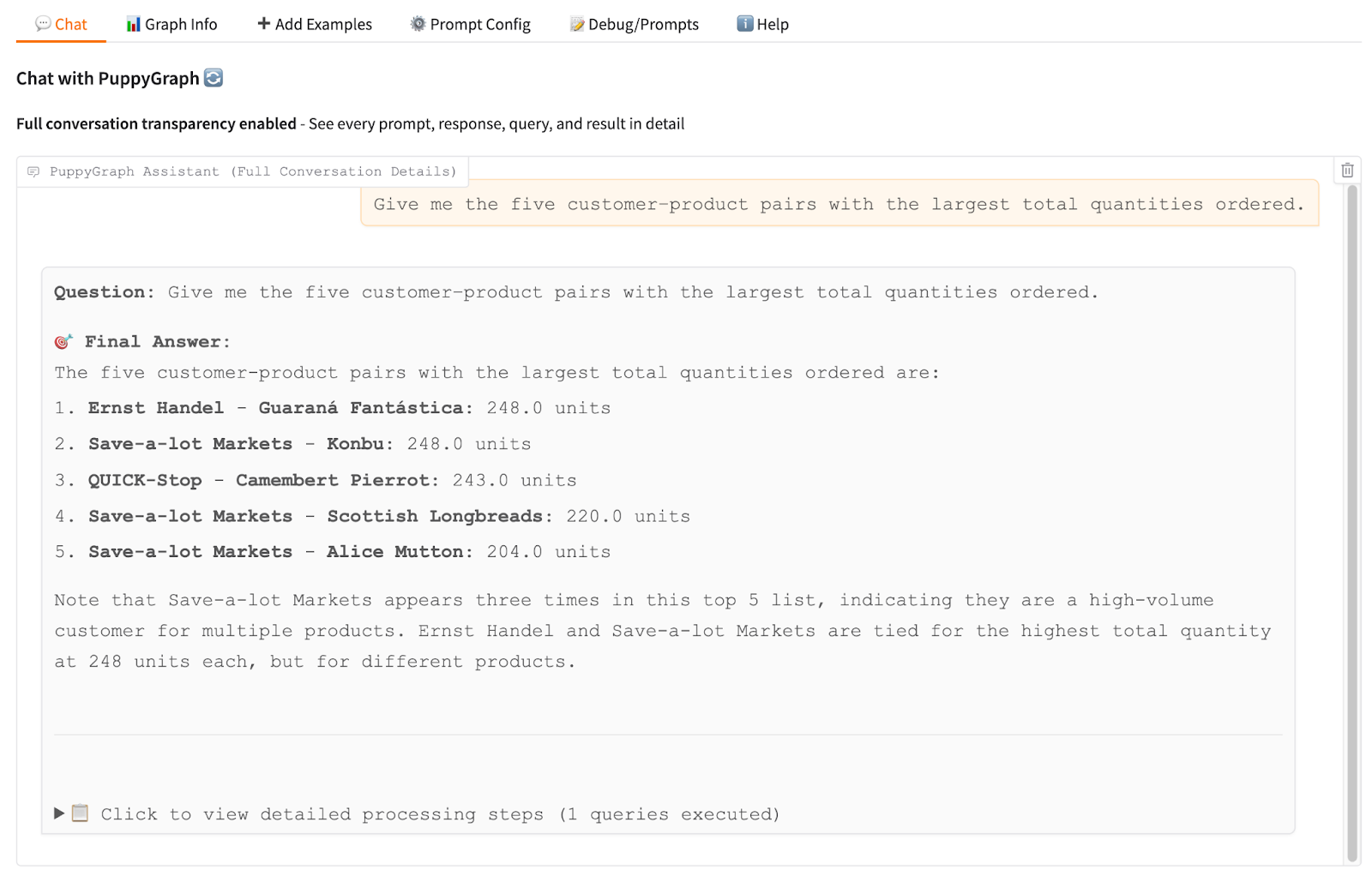
Enhanced by LLM, users no longer need to write specialized query languages like Cypher. PuppyGraph Chatbot automatically converts everyday questions into accurate graph queries, preserving the knowledge graph's logical reasoning capabilities while making its trusted information easily accessible through simple conversations.
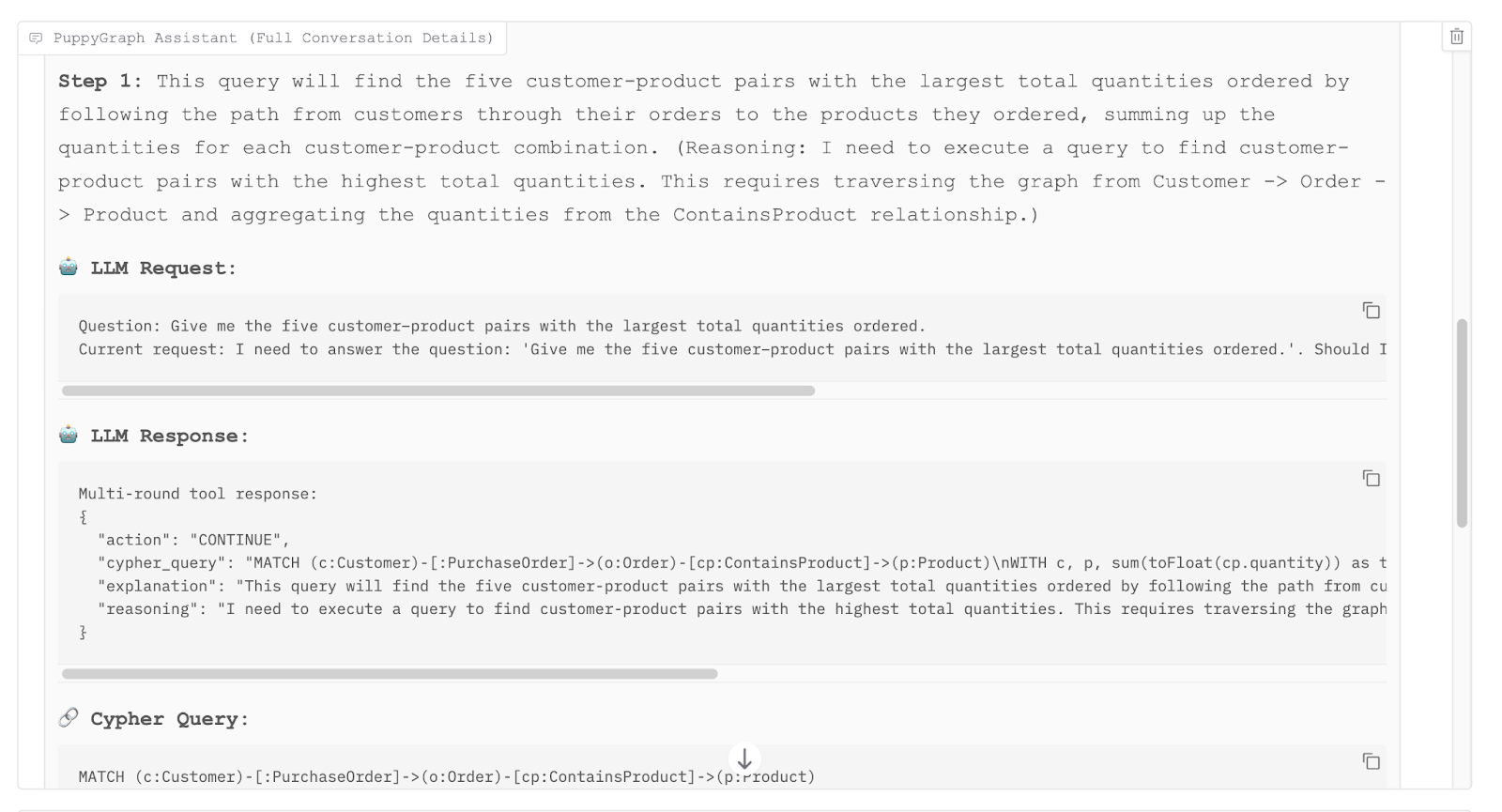
By expanding detailed processing steps, users can trace exactly how the LLM formulated its knowledge graph queries. This granular visibility transforms opaque outputs into auditable workflows, directly enhancing explainability while providing explicit checkpoints to detect potential errors.
What is PuppyGraph

PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.




Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
Knowledge Graphs and Large Language Models are complementary forces, essential for robust enterprise AI. LLMs provide the generalization, fluency, and ability to handle ambiguity, while knowledge graphs provide the structure, factual grounding, and auditability.
For organizations transitioning to knowledge-aware AI systems, the integration of these two paradigms through frameworks like GraphRAG is a strategic imperative. The hybrid model is designed to maximize the LLM's powerful generative utility while enforcing the factual rigor and logical consistency required for real-world deployment. By anchoring the probabilistic outputs to a verifiable, explicit source of truth, architects ensure systems are not only powerful but also reliable, traceable, and strategically agile.
To see how GraphRAG connects the LLM with trusted knowledge graphs, try the forever free PuppyGraph Developer Edition or book a demo with our team.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install