

How To Build AI Agents with Knowledge Graph?
An AI agent is only as good as what it can remember and retrieve. The model at its center is stateless: it reasons well within a single call, then forgets everything the moment the call returns. Most agents paper over this with a vector store of embedded text, which is good at finding passages that sound like the question but poor at answering questions about how things are connected. A knowledge graph agent takes a different route. It gives the agent a structured, queryable model of its domain, entities and the relationships between them, so its memory is something the agent can traverse and reason over rather than a bag of similar-looking snippets.
This post explains what a knowledge graph agent is, why persistent memory is the constraint that most limits agent reliability, and how a knowledge graph fills that gap. It then walks through how such an agent works, its architecture, how it differs from GraphRAG, the benefits it brings, and a practical path to building one.
What is a knowledge graph agent?
A knowledge graph agent is an AI agent that uses a knowledge graph as its structured memory and knowledge base. Instead of storing what it knows only as free text, the agent holds its domain as a graph: nodes are entities (customers, orders, services, hosts, documents), and edges are the relationships between them (placed, depends-on, owns, references). The agent reads from this graph to gather context before it reasons, and in many designs it writes back to the graph to record what it has learned.
The distinction from a standard retrieval-augmented agent is the shape of the memory, not just its contents. A vector-backed agent asks “what text is similar to my question?” A knowledge graph agent can ask “what is connected to this entity, and through what path?” That second question is a graph traversal, and it is the one enterprise work tends to require: tracing a dependency chain, following an ownership hierarchy, or connecting an alert to the assets it touches. The graph also carries an explicit schema, often an ontology, that names the entity and relationship types the domain contains. That schema gives the agent a stable map of the world to reason against, rather than a set of raw records it has to rediscover on every run.
Why AI agents need persistent memory
A large language model has no memory between calls. Everything it “knows” in a session lives in the context window, and the context window is both finite and lossy. As a task runs long, two failures set in. The window fills, and older information is evicted to make room. And model attention thins across very long inputs, so relevant tokens get crowded out by accumulated noise, an effect practitioners call context rot. An agent that keeps its plan and its findings only in context will lose the thread partway through a long job.
Persistent memory is the layer that survives this. It is the external store an agent writes to and reads from across steps and across sessions, so that a decision made at step three is still available at step forty, and a fact learned yesterday is available today. This is a core responsibility of the agent harness, the software layer around the model that supplies the loop, tools, state, and retrieval the model cannot hold by itself. Without persistent memory an agent repeats work it has already done, forgets constraints it was given, and cannot accumulate the domain understanding that makes it more useful over time.
But storage alone is not enough. Memory has to be retrievable in the shape the task needs. Writing everything to a log gives you durability without usefulness, because the agent still has to find the right facts and, more often than not, the connections between them. The question is not only “can the agent store what it learns,” but “can it retrieve the right connected context at the moment it reasons.” That requirement is what points toward a graph.
The role of knowledge graphs in agent memory
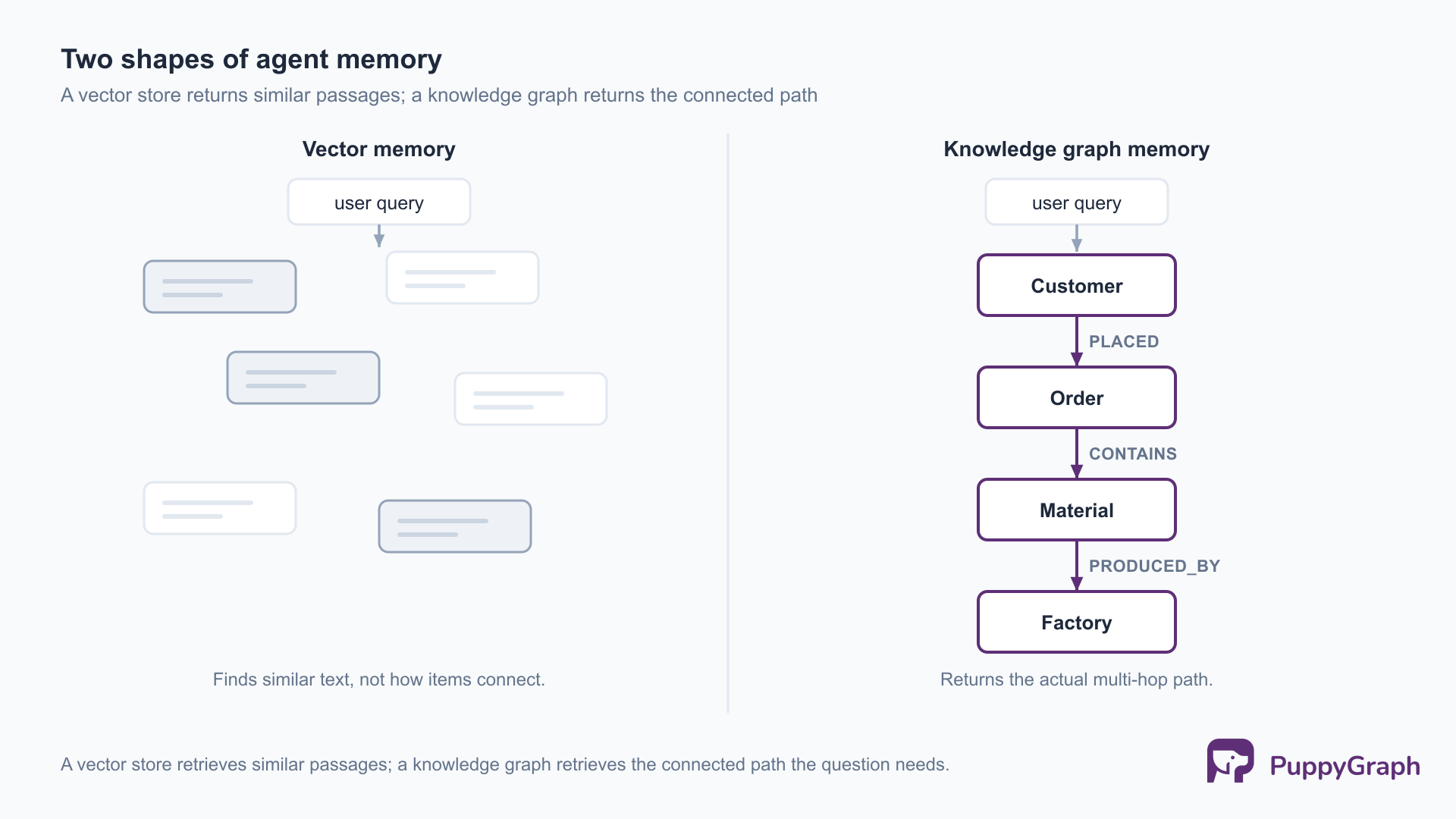
The reason a knowledge graph fits agent memory is that most of what an agent needs to recall is relational, and a graph stores relationships as first-class objects rather than reconstructing them at query time.
Relationships are the data, not a byproduct. In a knowledge graph an edge is a real, typed thing you can query directly: (:Order)-[:CONTAINS]->(:Material) is stored, not inferred. A question like “which factories produce the materials behind this customer’s open orders” is answered by walking edges, so the answer comes back as an actual path through the data rather than a guess assembled from passages that happen to mention the entities.
Multi-hop retrieval stays precise. Similarity search degrades as a question spans more hops, because each hop is another chance to retrieve a plausible-but-wrong passage. A graph traversal follows the exact edges instead, so a three-hop or five-hop question is the same kind of operation as a one-hop question, just longer. This is the gap that pure vector retrieval-augmented generation struggles to close.
Memory stays queryable and updatable. A graph is not a frozen snapshot. The agent can add nodes and edges as it learns, update properties as facts change, and query the current state at any time. That makes the graph a living memory the agent maintains, not just a store it reads.
Retrieval is explainable. Because a traversal returns the path it took, the context an agent retrieves is auditable: you can see exactly which entities and relationships produced an answer. For agents doing consequential work, that traceability matters as much as the answer itself.
Taken together, these properties reframe memory from “text the agent can search” to “a model of the domain the agent can reason over.” That shift, from similar to connected, is the core of why a knowledge graph is a natural memory substrate for an agent.
How a knowledge graph agent works
A knowledge graph agent runs the same basic loop any agent does, with the graph as the memory it reads from and writes to at each turn. The loop has a read path and a write path.
On the read path, the agent turns a goal into a query against the graph. Given a user request, the agent (usually the model, guided by the harness) formulates a graph query in a language like openCypher, issues it as a tool call, and gets back a precise, connected result to reason over. A retrieval that traces every factory producing the materials behind a customer’s open orders looks like this:
MATCH (c:Customer {id: $customer_id})-[:PLACED]->(:Order)-[:CONTAINS]->(m:Material)
MATCH (m)-[:PRODUCED_BY]->(f:Factory)
RETURN DISTINCT m.name, f.nameThe result is the actual set of materials and factories, with the path that connects them, not a set of documents the agent then has to interpret. The agent reasons over that grounded context and decides what to do next.
On the write path, the agent records what it learns back into the graph: new entities it discovers, relationships it establishes, or properties it updates. This is what turns the graph into durable, growing memory rather than a static reference. A research agent might add a newly found dependency between two services; a support agent might link a resolved ticket to the root-cause component so the next agent inherits that connection.
The step that makes this reliable is grounding. Before a query runs, it can be validated against the graph’s schema, so a reference to an entity or relationship type that does not exist is caught rather than silently returning nothing or a wrong result. When a query is rejected, structured feedback tells the agent which part was invalid, and the agent can repair the query and try again. That validate-and-repair cycle is a self-correction loop, and it is what keeps an agent’s queries semantically aligned with a domain even when the model does not know the exact schema.
Knowledge graph agent architecture
The architecture of a knowledge graph agent stacks into a few layers, from the raw data at the bottom to the reasoning at the top.
Data sources. The facts an agent needs usually already live somewhere: relational databases, data warehouses, data lakes, and open table formats. This is the ground truth the graph is built over.
The graph and ontology layer. On top of the data sits the knowledge graph itself: the entities and relationships, plus the ontology that types them. This layer is what the agent treats as memory. It exposes a query interface, typically openCypher or Gremlin, that turns a traversal into a result.
The query and grounding interface. Between the agent and the graph is the interface that accepts queries, validates them against the ontology, executes traversals, and returns results (or structured errors). This is where grounding happens and where the self-correction loop closes.
The agent and harness. At the top is the agent proper: the model plus the harness that runs the loop, manages the context window, calls the graph as a tool, applies guardrails, and persists state. The graph is one tool among possibly several, but for a knowledge graph agent it is the primary memory and retrieval surface.
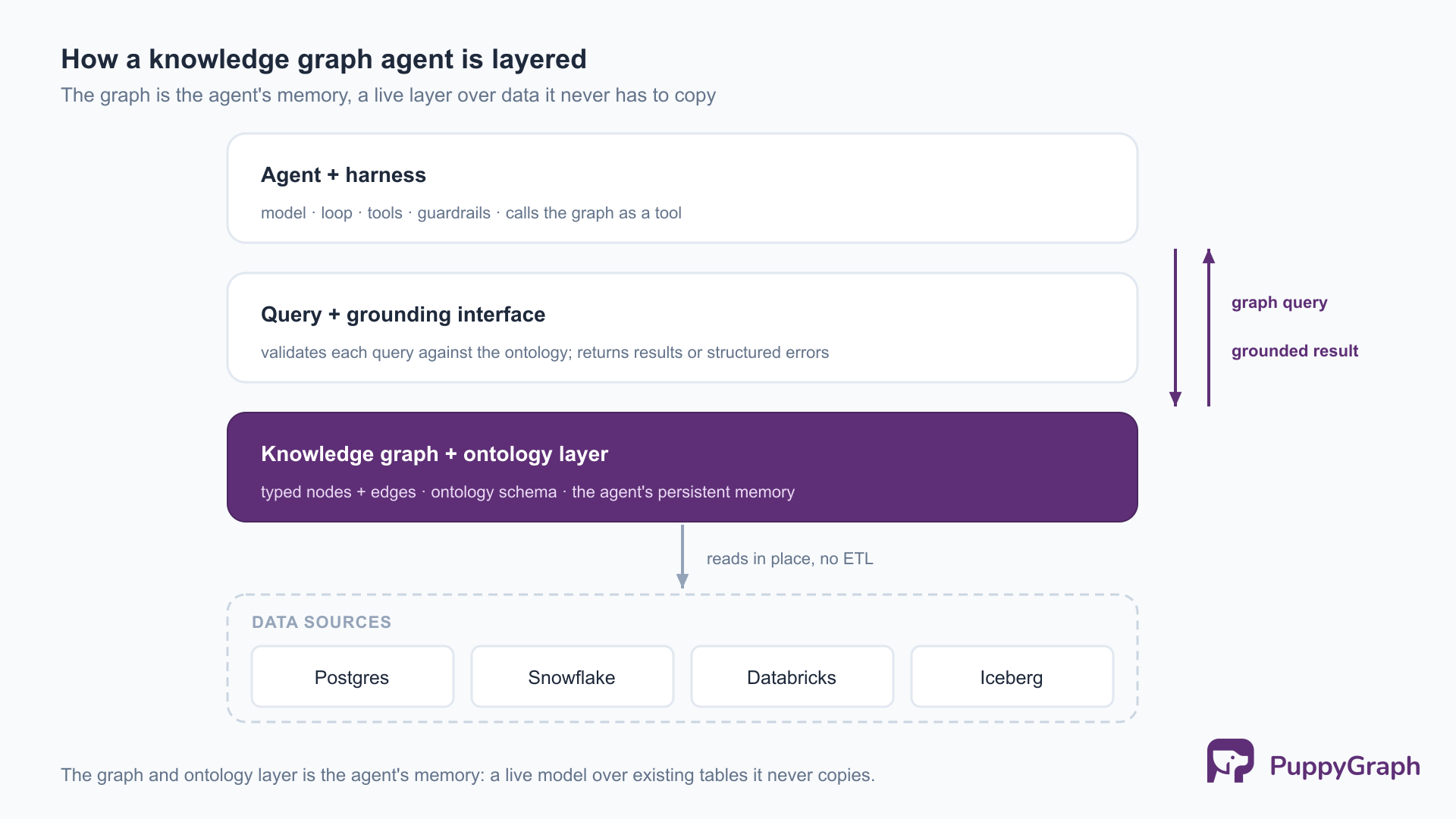
The layer that tends to cause the most operational pain is the second one. The standard way to stand up a knowledge graph is to build an ETL pipeline that copies data out of the source systems and loads it into a separate graph database, which then has to be kept in sync as the underlying data changes. For an agent whose value depends on current data, a stale graph is worse than no graph.
This is where PuppyGraph fits into the architecture. It is a graph query engine that sits between existing relational stores and the agent as an ontology layer: you define a graph schema over tables you already have in Postgres, Snowflake, Databricks, or an Iceberg lakehouse, and the agent queries that model in openCypher or Gremlin. The data stays where it lives, so there is no ETL pipeline to build or keep in sync, and the graph is a live model over the underlying tables rather than a copy held in a separate database. Underneath, PuppyGraph compiles a traversal into a plan of node and edge operators that execute inside its own engine, rather than translating the query into one large SQL statement pushed down to the source, which is what keeps deep multi-hop traversals practical rather than bounded by a relational query planner. AMD, for example, uses this approach to build a graph layer over Apache Iceberg across tickets, code, logs, and telemetry, the kind of connected context an agent working across those systems would traverse.
Knowledge graph agent vs GraphRAG
These two terms are often used as if they compete, but they sit at different levels, and the cleanest way to see the difference is that one is a retrieval technique and the other is a system architecture.
GraphRAG is a retrieval pattern: retrieval-augmented generation that uses a knowledge graph, instead of or alongside a vector store, as the source it retrieves from. Its job is to fetch better, more connected context to put in front of the model for a single generation. (Some implementations, such as Microsoft’s GraphRAG, also bundle a graph-construction and summarization step, but the end the retrieval serves is the same.) A knowledge graph agent is the larger system: an agent that uses a knowledge graph as persistent memory and can plan, take multiple steps, call tools, write new facts back, and pursue a goal over many turns. GraphRAG is frequently a component inside a knowledge graph agent, the mechanism the agent uses on its read path, not an alternative to it.
The practical takeaway is that this is not a choice between the two. If you need to answer one question with graph-grounded context, GraphRAG is the pattern. If you need a system that reasons across many steps, remembers what it learned, and acts, you are building a knowledge graph agent, and it will likely use GraphRAG-style retrieval as one of its moves. For a deeper treatment of the retrieval side, see our GraphRAG architecture deep dive.
Benefits of using a knowledge graph agent
Grounded reasoning and fewer hallucinations. When an agent retrieves an explicit path through real data rather than passages that resemble the question, it has less room to invent. Grounding queries against an ontology adds a second guard: a query that references something the schema does not contain is rejected instead of returning a confident but wrong answer.
Reliable multi-hop reasoning. The questions enterprises actually ask are traversals over dependencies, permissions, ownership, and lineage. A graph answers those precisely at any depth, where similarity search loses accuracy with each additional hop.
Persistent, updatable memory. The graph is memory the agent maintains over time. It survives context compaction and session restarts, and it grows as the agent records what it learns, so later runs inherit the connections earlier runs discovered.
Explainable retrieval. Because a traversal returns the path it followed, you can audit why the agent believed what it did. For agents doing consequential work, that traceability is often as valuable as the answer.
Current data without a sync lag. When the graph is a live layer over the systems of record rather than a periodically refreshed copy, the agent reasons over current state, which is what keeps its answers trustworthy in domains where the data moves.
How to build a knowledge graph agent
The most reliable way to build one is to work backward from the behavior you want, the same discipline that guides building any agent harness. Define the task and the standard for “done,” then derive the graph, the queries, and the loop from there rather than assembling components first and hunting for a use.
Model the domain as an ontology. Start with the entities and relationships the task reasons over, and name them as a schema. This ontology is both the structure of the graph and the contract the agent’s queries are validated against. Keep it scoped to what the task needs; a smaller, sharper ontology grounds the agent better than an exhaustive one.
Get the data into the graph. This is the step that decides how fresh the agent’s memory is. Copying data into a standalone graph database via ETL works but leaves you maintaining a pipeline and a graph that lags its sources. Building the graph as a layer over the data where it already lives avoids both. PuppyGraph takes this path: it maps existing warehouse and lakehouse tables into a graph the agent queries directly, with no separate graph database and no ETL, so the agent’s memory reflects current data. Because it speaks openCypher and is accessible over the Bolt protocol, existing Neo4j drivers and tools can point at it without rewriting queries.
Expose the graph to the agent as a tool. Give the agent a query tool that accepts a traversal, runs it, and returns results or a structured error. In practice this is a thin wrapper the harness registers, so the model can request a graph query the way it requests any other tool call:
def graph_query(cypher: str, params: dict) -> list[dict]:
# Validate against the ontology, execute the traversal,
# and return rows or a structured error the agent can repair from.
return kg.run(cypher, params)Close the grounding and self-correction loop. Validate each query against the ontology before it runs, and when one is rejected, return machine-readable feedback naming the invalid entity or relationship so the agent can repair and retry rather than proceed on a wrong result. This loop is what keeps generated queries semantically aligned with the domain.
Add the write path and verification. Decide what the agent is allowed to record back into the graph and how, so its memory grows without corrupting. And build an evaluation set of representative tasks with checkable outcomes, so you can tell whether a change to the ontology, the queries, or the loop made the agent better or worse.
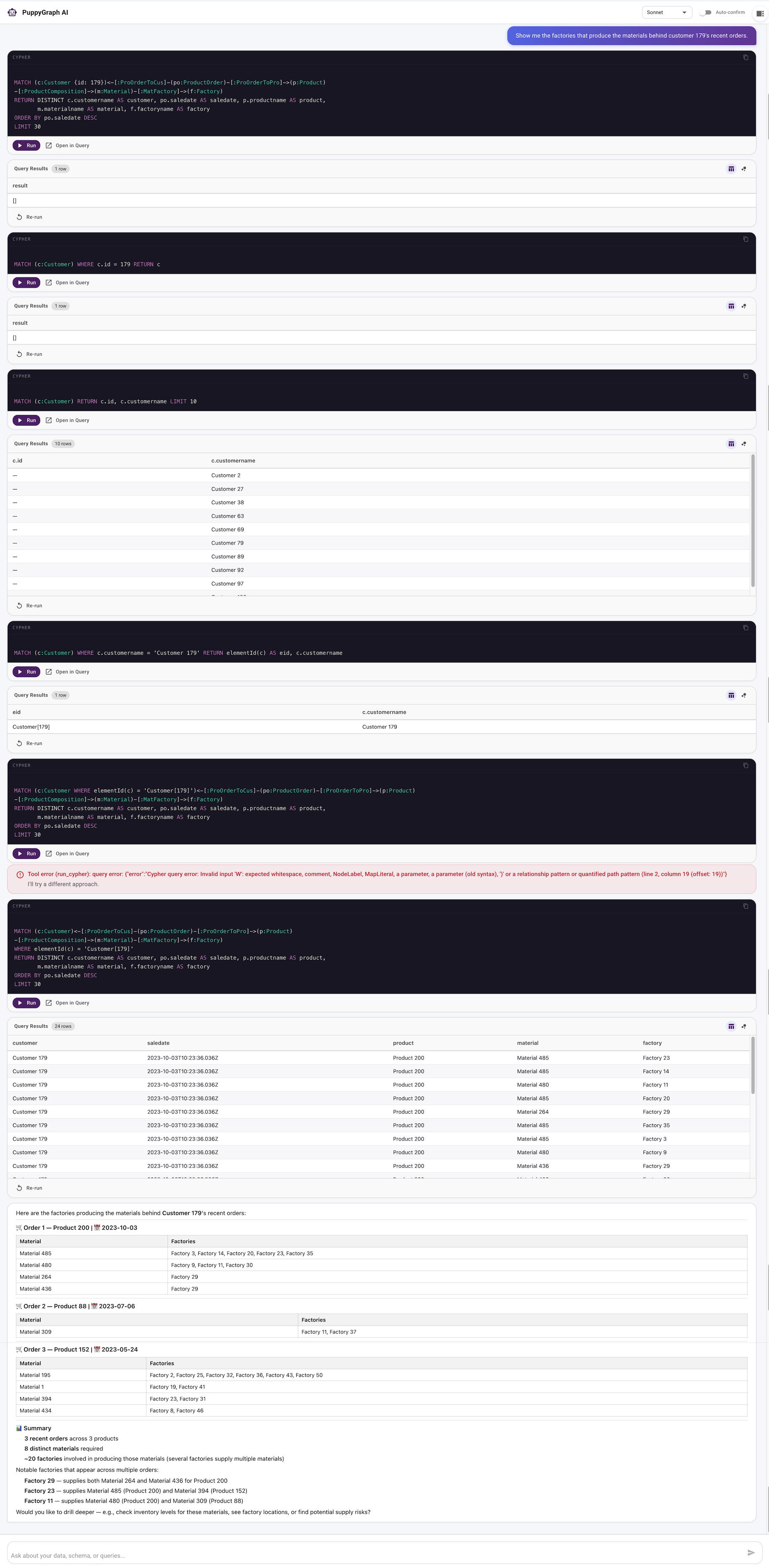
PuppyGraph’s built-in AI assistant is a working instance of the read-path loop these steps assemble: you ask a question in natural language, it generates a graph query against the ontology, and when a query comes back rejected it reads the structured error and rewrites it rather than return a wrong answer. It is a useful existence proof of the grounding-and-self-correction mechanism that a knowledge graph agent depends on.
Conclusion
A knowledge graph agent solves the memory problem that limits most agents by giving the model a structured, queryable model of its domain instead of a flat pile of embedded text. Entities and relationships become memory the agent can traverse, ground its reasoning in, update as it learns, and audit after the fact. That connected context is what raises the ceiling on how reliably an agent can reason over the multi-hop questions real work is made of, and building the graph as a live layer over data you already have, rather than a copied and constantly re-synced database, is what keeps that memory current.
Try the forever-free PuppyGraph Developer Edition and book a demo with the team to see how openCypher and Gremlin queries run over warehouse and lakehouse tables, with no graph-specific ETL, give a knowledge graph agent the persistent, multi-hop memory its reasoning depends on.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install