

7 Knowledge Graph Examples of 2026
Knowledge graphs are among the most transformative data technologies enabling modern applications to interpret context, meaning, and relationships rather than simply storing isolated facts. As organizations face increasingly fragmented data across systems, knowledge graphs offer a way to unify this information into coherent, semantically rich networks that both machines and humans can navigate intuitively. These graphs empower generative AI, intelligent assistants, compliance engines, fraud detection platforms, and enterprise analytics by providing a structured backbone grounded in real-world entities and their interconnections. In this article, we explore what knowledge graphs are, why they are vital in contemporary data ecosystems, and highlight seven leading real-world examples illustrating their practical power and strategic value.
What Are Knowledge Graphs
A knowledge graph organizes information by modeling entities, like people, places, companies, products, or ideas, and the meaningful relationships between them. Unlike traditional databases, which rely on rigid table structures or document formats, a knowledge graph uses nodes and edges to mirror how the real world works. This design allows systems to navigate from one concept to another fluidly, revealing chains of meaning: who worked with whom, which product is compatible with another, how a concept evolved across time, or how a disease relates to its genetic markers.
Knowledge graphs often integrate data from multiple systems, such as CRM platforms, external APIs, content repositories, and internal knowledge bases, and enrich that data with ontologies that define the types of entities and the meaning of their relationships. Because of this enrichment, both humans and machines can query the graph, infer new connections, and reason about relationships in ways that go beyond simple keyword matching. This contextual intelligence is what makes knowledge graphs especially valuable in AI-driven applications, where understanding semantics and context is critical.
Why Knowledge Graphs Matter in Modern Data Systems
Knowledge graphs serve as a bridge between fragmented, raw data and actionable insight. As companies generate enormous volumes of structured data, unstructured text, and real‑time events, traditional storage systems struggle to unify these sources into a coherent, queryable model. By encoding semantics, knowledge graphs enable richer queries, support inferencing, and make it possible to reveal hidden relationships that traditional systems cannot easily capture.
Moreover, knowledge graphs enhance AI and personalization capabilities by providing semantic context. They enable natural language interfaces to interpret user intent rather than just surface-level commands. They feed personalization engines with deep connections between user behavior, preferences, and content. In compliance‑driven settings, graphs help track provenance, ensure lineage of data, and explain how automated decisions were reached. Because they represent data in a web of meaning, knowledge graphs are particularly adept at supporting risk, fraud, and anomaly detection by mapping entities and their interactions across complex networks.
Another crucial reason knowledge graphs matter is that they allow architectures to remain flexible and scalable. New data sources, evolving business domains, or changing regulatory requirements can be added into the graph without requiring a complete redesign. This incremental growth ensures the system stays adaptive over time. In 2026, as AI becomes deeply integrated into enterprise workflows, knowledge graphs are essential for models to be rooted in truth, transparency, and trust.
Key Features That Define an Effective Knowledge Graph
Not all graph structures qualify as knowledge graphs in the fullest sense. The most robust ones embody certain core qualities that enable meaningful reasoning, broad interoperability, and ongoing adaptability. One essential feature is semantic richness: relationships in the graph must convey meaning, not merely point from one node to another. When a graph knows not only that two nodes are connected, but how they are connected, by role, by causality, by shared attribute, it can support far more powerful insights.
Equally critical is the integration of diverse data sources. An effective knowledge graph harmonizes information from legacy databases, real‑time streams, documents, APIs, and external datasets into one shared semantic model. This convergence is what turns disconnected data into a unified intelligence layer.
The third defining feature, inferencing or reasoning, allows the graph to derive new facts from existing ones. For instance, if a company owns a subsidiary, and that subsidiary owns an asset, a well-constructed graph can infer that the parent company indirectly owns the asset. These inferences deepen the insight the system can deliver without manually encoding every relationship.
Finally, the graph must support continuous evolution. As business domains change, new entities emerge, new relationships are discovered, and data sources evolve. A knowledge graph built on flexible ontologies and schema patterns can grow without massive refactoring or data migration, making it sustainable in the long run.
Taken together, these features allow knowledge graphs to remain coherent, extensible, and reliable even as the scale and complexity of data grow.
Top 7 Knowledge Graph Examples and Their Use Cases
1. Google Knowledge Graph: Powering Semantic Search and AI
Google’s Knowledge Graph underlies the way Google Search understands entities and context. Rather than simply matching keywords, Google interprets user intent by linking queries to a rich network of entities like people, places, books, and events. This allows search results to include entity panels, context-aware suggestions, and disambiguation when a term could refer to multiple things.
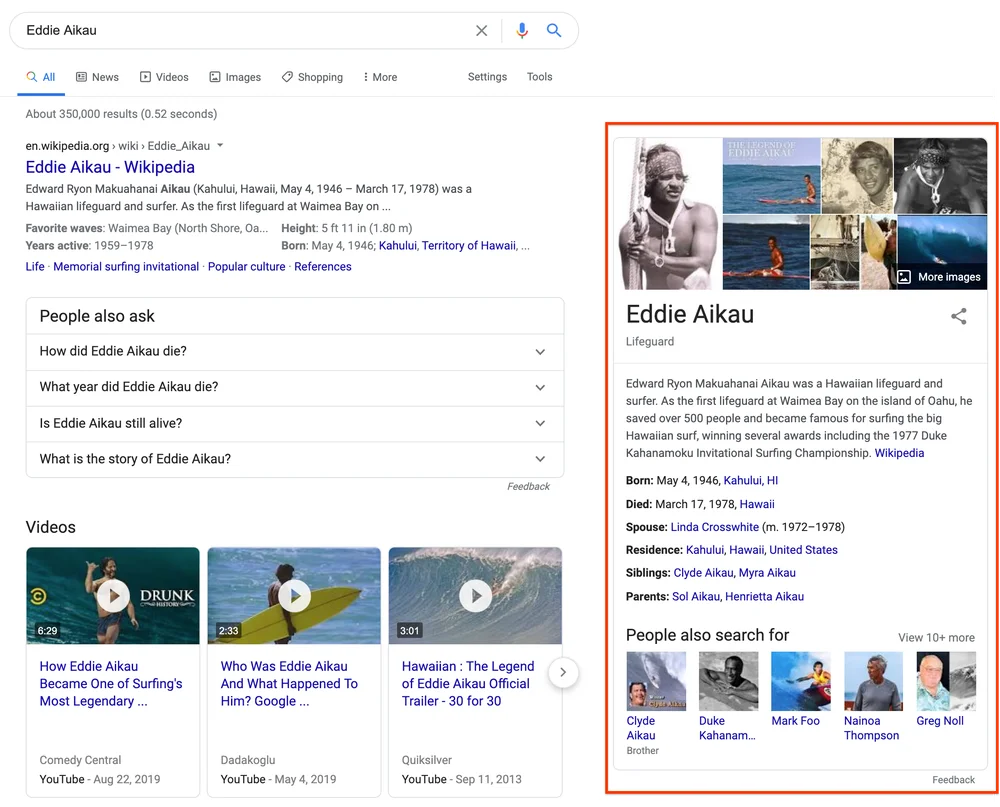
By representing billions of real-world entities and their interrelations, Google’s graph enables more natural search, supports voice queries, and enhances generative AI by grounding responses in verified facts. In 2026, as Google integrates even more with multimodal inputs, images, video, and voice, the Knowledge Graph provides the stable, factual core that ensures consistency and trust in AI-driven experiences.
2. LinkedIn Economic Graph: Modeling the Global Workforce
LinkedIn’s Economic Graph captures the relationships between professionals, the companies they work for, the educational institutions they attended, and the skills they possess. Through this graph, LinkedIn can analyze labor market trends, match talent to roles, and suggest learning paths that align with future opportunities.

By understanding how roles connect to skills, how companies relate to industries, and how professionals move between jobs, LinkedIn’s graph supports career recommendations, informs hiring strategies for organizations, and helps educators align curricula with market needs. In 2025, this graph fuels AI career assistants that can forecast emerging roles, identify skill gaps, and recommend tailored training programs.
3. Amazon Product Knowledge Graph: Enabling Intelligent Shopping
Amazon’s Product Graph connects information about products, attributes, customer browsing behavior, reviews, purchases, and compatibility. Rather than treating each item in isolation, this graph understands how products relate to each other, such as which items are accessories, which compete directly, or which are often bought together.
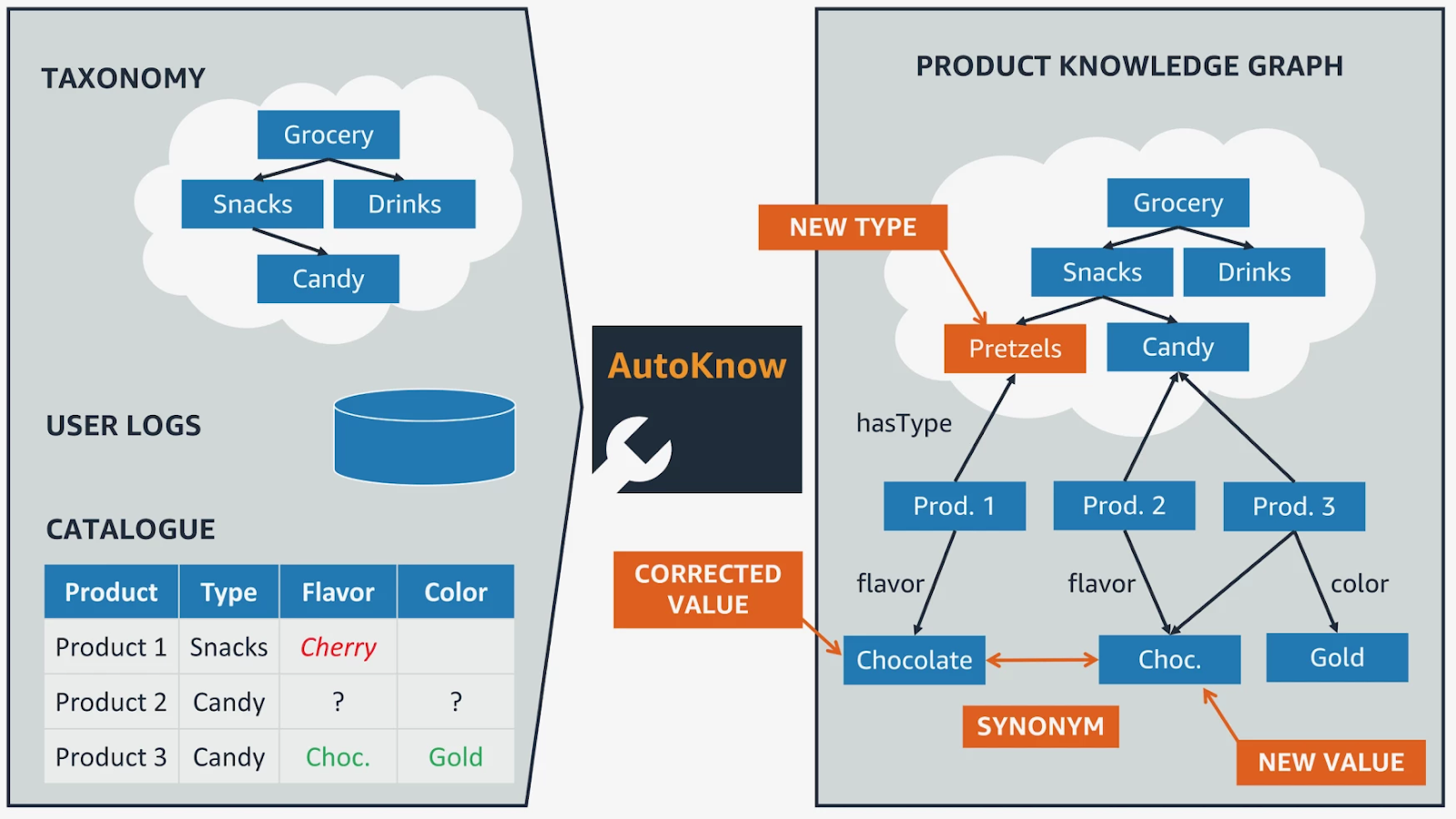
This structured view powers recommendation systems, substitution suggestions when a product is out of stock, dynamic bundling logic, and more robust fraud detection. For sellers, it provides taxonomy guidance and clarity. For Amazon itself, the graph helps optimize inventory and manage supply chain relationships. In 2026, as conversational commerce and generative shopping assistants advance, the Product Knowledge Graph plays a key role in maintaining factual consistency, enabling natural dialogue, and delivering smarter experiences.
4. Microsoft Academic Graph: Driving Research Discovery and Innovation
The Microsoft Academic Graph models connections among authors, research institutions, scientific publications, fields of study, citations, and influence networks. It enables rich exploration of the academic landscape: finding who’s publishing on what topics, how they cite each other, and how ideas propagate across disciplines.
This knowledge graph supports literature navigation, collaboration recommendations, and automated generation of research summaries. It accelerates innovation by making it easier for scholars to discover relevant work, identify key influencers, and trace the evolution of scientific ideas. In the context of AI research, the graph offers a structured foundation for training models that need grounding in factual, peer-reviewed sources.
5. Meta (Facebook) Social Knowledge Graph: Understanding Relationships at Scale
Meta’s social knowledge graph captures the richness of social interactions: friendships, group memberships, event participation, shared interests, and communications. By modeling these relationships explicitly, Meta can craft more personalized, meaningful experiences across its platforms.
This graph powers content ranking, community discovery, and trust scoring. It also helps Meta detect coordinated behavior, misinformation, and networks of influence. In 2026, as augmented reality (AR) and virtual reality (VR) deepen Meta’s ecosystem, the social graph also anchors identity continuity, allowing users to carry their social context across immersive experiences.
6. IBM Watson Health Knowledge Graph: Structuring Medical Intelligence
IBM Watson’s medical knowledge graph integrates a broad array of health data: clinical trials, patient records, genetic biomarkers, diagnoses, treatment protocols, symptom data, and drug interactions. This structured representation allows healthcare professionals and decision‑support systems to reason over complex medical knowledge in a more human-like, contextual way.
By connecting clinical studies to real-world patient outcomes, Watson Health’s graph helps clinicians identify treatment pathways, assess risk, and provide personalized care. Because the knowledge graph supports provenance and evidence tracking, it also underpins regulatory alignment, patient safety, and explainable AI. In 2026, this graph grows ever more critical as generative health assistants and precision medicine platforms demand rigorous, verifiable knowledge structures.
7. Wikidata: The Open, Global, Collaborative Knowledge Graph
Wikidata stands apart because it is community-driven, multilingual, and openly licensed. It contains structured data about millions of entities, including people, places, events, languages, and more, and allows anyone to contribute, query, or reuse the knowledge without cost.


This open knowledge graph underlies Wikipedia infoboxes, supports fact-checking platforms, enables linked data applications, and provides high-quality training data for AI systems. Because it is collaboratively maintained, Wikidata remains up to date, transparent, and reflective of global diversity. In 2026, it plays a pivotal role in semantic web applications, open research efforts, and AI systems that require trustworthy, freely available structured knowledge.
How Different Industries Leverage Knowledge Graphs
Having explored concrete examples from leading technology platforms, it's worth looking more broadly at how knowledge graphs operate across diverse real-world industries. The following use cases illustrate how different sectors apply graph intelligence to enhance decision-making, automation, and insight generation.
Cybersecurity & Threat Intelligence
Security teams rely on knowledge graphs to correlate logs, vulnerabilities, assets, identities, alerts, and threat indicators. By representing infrastructure as an interconnected graph, organizations can trace attack paths, detect lateral movement, prioritize risks, and automate incident response with clearer context and far fewer false positives.
Financial Crime & Risk Management
Banks use knowledge graphs to link transactions, accounts, ownership structures, and behavioral patterns into a unified network. This allows analysts and AI systems to detect fraud rings, uncover hidden relationships, assess credit exposure, and monitor regulatory compliance in real time, far beyond the capabilities of traditional rule-based tooling.
Healthcare & Life Sciences
Healthcare providers integrate clinical notes, diagnoses, treatments, genomics, and real-world evidence into patient-centric graphs. These models help identify symptom correlations, predict adverse events, recommend therapies, and support precision medicine by contextualizing each decision within a broader medical and biological knowledge landscape.
Retail, E-Commerce & Customer 360
Retailers build Customer 360 graphs that merge product metadata, browsing signals, purchase history, and inventory data into a semantic profile of customers and offerings. This enables richer recommendations, churn prediction, demand forecasting, and omnichannel personalization, all grounded in relationships between users, products, and behaviors.
Enterprise Search & Knowledge Management
Enterprises use knowledge graphs to connect documents, experts, projects, codebases, and business concepts into a unified semantic workspace. This improves internal search, accelerates onboarding, and powers conversational assistants that understand organizational context, enabling teams to discover relevant information quickly and reduce duplicated effort.
Supply Chain & Manufacturing Intelligence
Supply chain graphs link suppliers, parts, logistics flows, contracts, risks, and product configurations. These relationships help organizations anticipate disruptions, manage dependencies, optimize production planning, and simulate how component shortages or shipping delays ripple through the network.
Energy, Utilities & Smart Infrastructure
Utilities use knowledge graphs to map assets, sensors, maintenance records, geographic constraints, and energy consumption patterns. This allows operators to detect anomalies, optimize energy distribution, predict equipment failures, and support ESG reporting with verifiable, interconnected operational data.
Why PuppyGraph
As organizations increasingly recognize the value of knowledge graphs, a practical challenge emerges: building, maintaining, and querying these graphs efficiently across diverse data sources. Traditional graph databases often require costly ETL pipelines, duplicated storage, and specialized infrastructure, which can slow down deployment and limit real-time insights. Teams need a solution that allows them to leverage the power of knowledge graphs without introducing additional complexity or latency.

This is where PuppyGraph comes in. Instead of copying data into a graph database, PuppyGraph builds a real-time knowledge graph directly from your relational data sources. You can load tables as nodes and edges instantly, run Gremlin or Cypher queries without ETL, and even query the graph through the PuppyGraph chatbot using natural language, turning your existing data into a live, semantic layer with zero duplication.
For the purpose of illustration, let’s deploy the dataset Northwind on PuppyGraph:
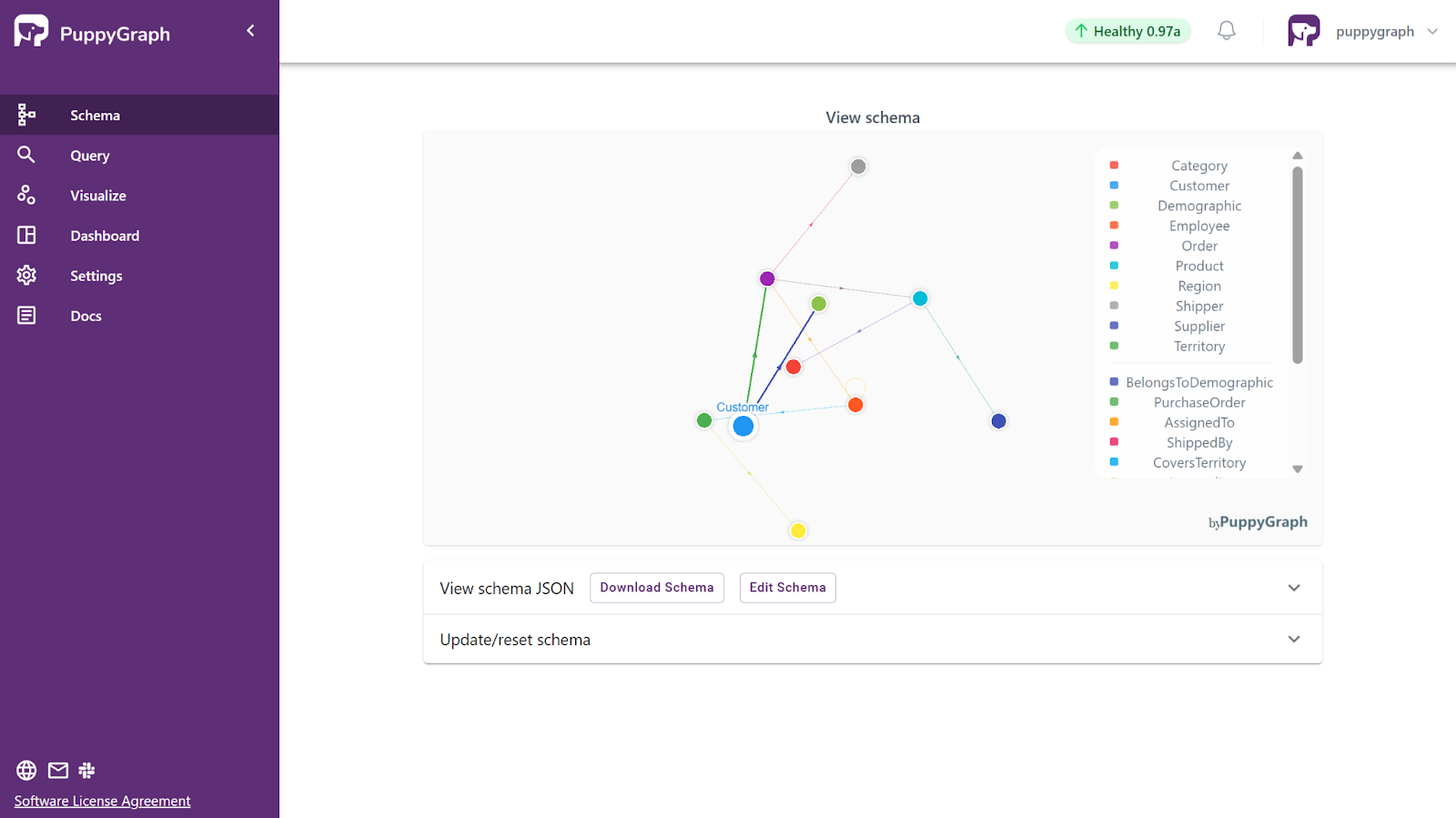
In the screenshot above, you can see how PuppyGraph maps the tables into nodes and edges automatically: customers link to their orders, orders link to products, and employees link to the orders they are responsible for. Once the graph view is defined, you can run a Gremlin or Cypher query against the dataset directly, surfacing insights that would require complex joins or custom pipelines in SQL.

Then we can see how this experience becomes even more intuitive with the PuppyGraph Chatbot. Instead of writing queries, users can simply ask natural language questions like “Which suppliers are associated with the products that appear most frequently in customer orders?” The chatbot interprets the intent, generates the appropriate graph query, and returns structured results. This turns your knowledge graph into an interactive exploration environment where business users, analysts, and engineers can all navigate multi-hop relationships without needing to learn a graph language.
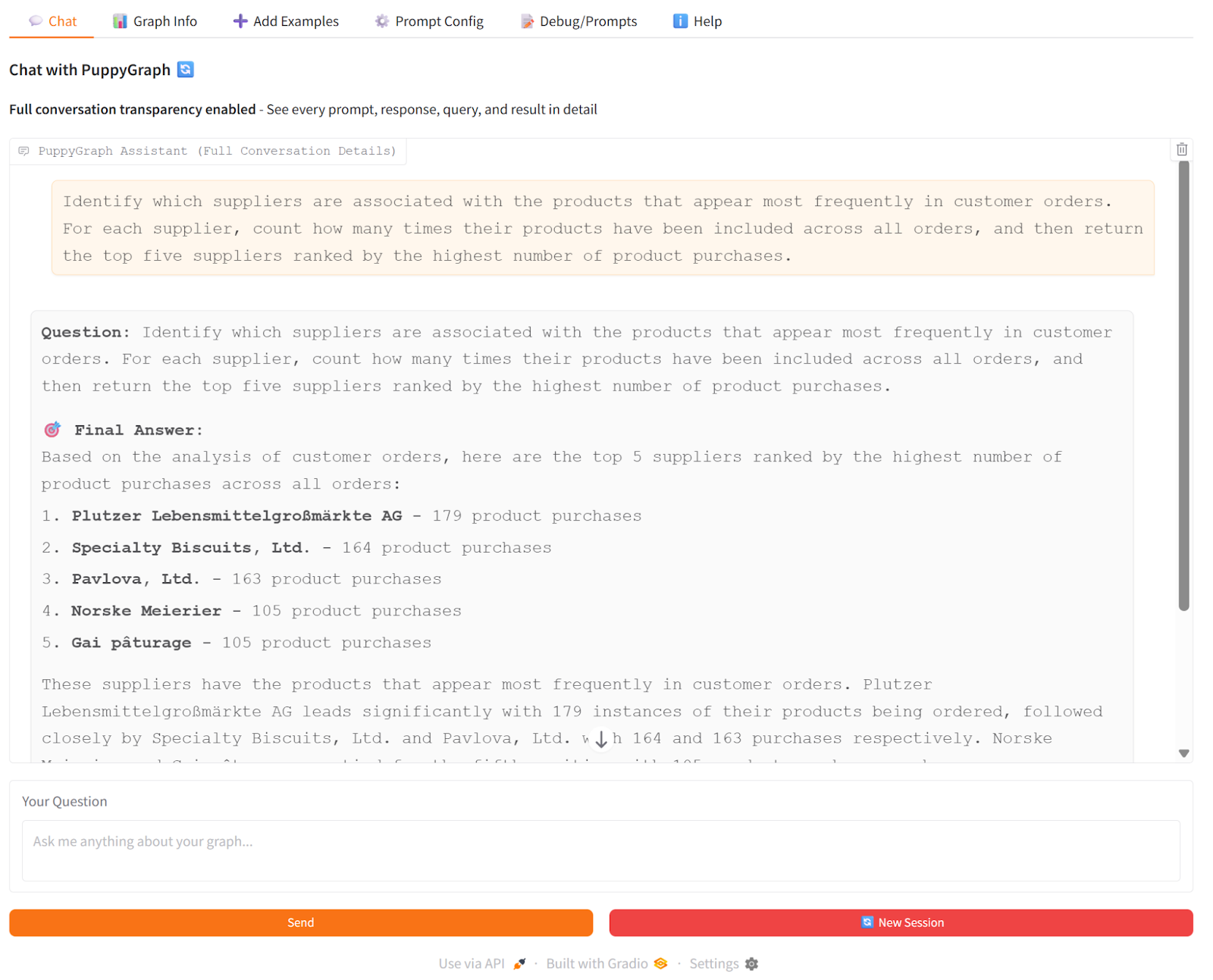
Click on ‘view detailed processing steps’, the UI will display more details of processing, including the generated Cypher query.

What is PuppyGraph
PuppyGraph is the first and only real time, zero-ETL graph query engine in the market, empowering data teams to query existing relational data stores as a unified graph model that can be deployed in under 10 minutes, bypassing traditional graph databases' cost, latency, and maintenance hurdles.
It seamlessly integrates with data lakes like Apache Iceberg, Apache Hudi, and Delta Lake, as well as databases including MySQL, PostgreSQL, and DuckDB, so you can query across multiple sources simultaneously.


Key PuppyGraph capabilities include:
- Zero ETL: PuppyGraph runs as a query engine on your existing relational databases and lakes. Skip pipeline builds, reduce fragility, and start querying as a graph in minutes.
- No Data Duplication: Query your data in place, eliminating the need to copy large datasets into a separate graph database. This ensures data consistency and leverages existing data access controls.
- Real Time Analysis: By querying live source data, analyses reflect the current state of the environment, mitigating the problem of relying on static, potentially outdated graph snapshots. PuppyGraph users report 6-hop queries across billions of edges in less than 3 seconds.
- Scalable Performance: PuppyGraph’s distributed compute engine scales with your cluster size. Run petabyte-scale workloads and deep traversals like 10-hop neighbors, and get answers back in seconds. This exceptional query performance is achieved through the use of parallel processing and vectorized evaluation technology.
- Best of SQL and Graph: Because PuppyGraph queries your data in place, teams can use their existing SQL engines for tabular workloads and PuppyGraph for relationship-heavy analysis, all on the same source tables. No need to force every use case through a graph database or retrain teams on a new query language.
- Lower Total Cost of Ownership: Graph databases make you pay twice — once for pipelines, duplicated storage, and parallel governance, and again for the high-memory hardware needed to make them fast. PuppyGraph removes both costs by querying your lake directly with zero ETL and no second system to maintain. No massive RAM bills, no duplicated ACLs, and no extra infrastructure to secure.
- Flexible and Iterative Modeling: Using metadata driven schemas allows creating multiple graph views from the same underlying data. Models can be iterated upon quickly without rebuilding data pipelines, supporting agile analysis workflows.
- Standard Querying and Visualization: Support for standard graph query languages (openCypher, Gremlin) and integrated visualization tools helps analysts explore relationships intuitively and effectively.
- Proven at Enterprise Scale: PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


As data grows more complex, the most valuable insights often lie in how entities relate. PuppyGraph brings those insights to the surface, whether you’re modeling organizational networks, social introductions, fraud and cybersecurity graphs, or GraphRAG pipelines that trace knowledge provenance.

Deployment is simple: download the free Docker image, connect PuppyGraph to your existing data stores, define graph schemas, and start querying. PuppyGraph can be deployed via Docker, AWS AMI, GCP Marketplace, or within a VPC or data center for full data control.
Conclusion
In 2026, knowledge graphs have moved from niche experiments to essential components of intelligent data systems. By modeling entities and their relationships with semantic depth, they give applications a way to understand context rather than simply retrieve information. This shift enables richer reasoning, more accurate explanations, and far more intuitive interactions across search, analytics, and AI-driven workflows.
Across industries, knowledge graphs now underpin everything from fraud detection and supply-chain visibility to biomedical discovery and personalized digital experiences. The real-world examples explored above, from search engines and e-commerce to research networks and open data, highlight how these graphs bring structure and meaning to increasingly complex data environments, unlocking insights that traditional systems struggle to surface.
For organizations looking to adopt this capability without heavy pipelines or duplicated infrastructure, PuppyGraph offers a practical path forward: a real-time, zero-ETL graph engine that turns existing relational data into a unified, queryable knowledge layer in minutes.If you want to see this in your own data, you can try PuppyGraph’s forever-free Developer Edition or book a demo with the team to walk through your use cases live.

Hao Wu is a Software Engineer with a strong foundation in computer science and algorithms. He earned his Bachelor’s degree in Computer Science from Fudan University and a Master’s degree from George Washington University, where he focused on graph databases.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install